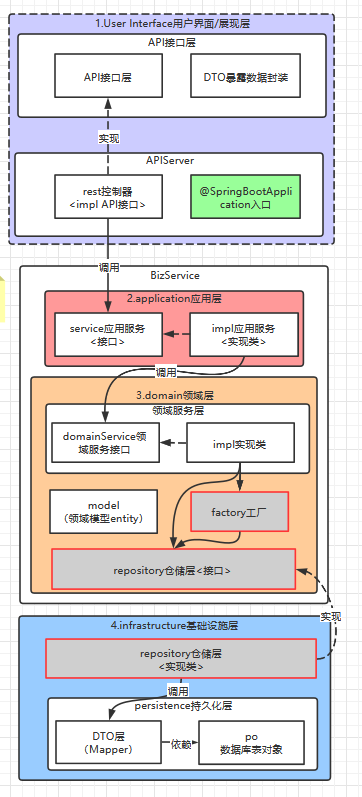
来源: JavaScript数组方法的兼容性写法 汇总:indexOf()、forEach()、map()、filter()、some()、every() – 凳子_joinery – 博客园
ECMA Script5中数组方法如indexOf()、forEach()、map()、filter()、some()并不支持IE6~8,但是国内依然有一大部分用户使用IE6~8,而以上数组方法又确实非常好用。在过去,我会为了兼容性尽量不用这些方法。但是,总不能为了旧的丢了新的吧?!虽然说JQuery已经集成好了不少语法糖,但JQuery体积太庞大,作为一名志于体面的前端儿得知道原生的兼容性写法要怎么写。于是这几天,我开始在琢磨这些方法的兼容性写法。其实并不难,就是以前不够自信不敢写。写完以后,对数组认识更深一些了。总结见下文。
备注:以下兼容性写法均可兼容至IE6;
一. indexOf()
indexOf()方法 返回根据给定元素找到的第一个索引值,否则返回-1。
语法:
array.indexOf(searchElement[, fromIndex = 0])
参数:
searchElement // 位于数组中的元素;
fromIndex // 开始查找指定元素的索引值,默认值为 0 (即在整个数组中查找指定元素);
fromIndex大于或等于数组长度,则停止查找并返回-1。如果参数中提供的索引值是一个负值,则将其作为数组末尾的一个抵消,即-1表示从最后一个元素开始查找,-2表示从倒数第二个元素开始查找 ,以此类推。
兼容性:不兼容IE6~8。
根据indexOf()的语法写出兼容IE6~8的写法如下:
兼容性写法:
if (!Array.prototype.indexOf) {
Array.prototype.indexOf = function(ele) {
// 获取数组长度
var len = this.length;
// 检查值为数字的第二个参数是否存在,默认值为0
var fromIndex = Number(arguments[1]) || 0;
// 当第二个参数小于0时,为倒序查找,相当于查找索引值为该索引加上数组长度后的值
if(fromIndex < 0) {
fromIndex += len;
}
// 从fromIndex起循环数组
while(fromIndex < len) {
// 检查fromIndex是否存在且对应的数组元素是否等于ele
if(fromIndex in this && this[fromIndex] === ele) {
return fromIndex;
}
fromIndex++;
}
// 当数组长度为0时返回不存在的信号:-1
if (len === 0) {
return -1;
}
}
}
调用示例:
var arr = ["a", "b", "c"];
alert(arr.indexOf("b")); // 1
二. forEach()
forEach() 方法让数组的每一项都执行一次给定的函数。forEach()方法会修改原数组。
语法:
array.forEach(callback[, thisArg])
参数:
1 . callback :在数组每一项上执行的函数,接收三个参数: currentValue(当前项的值)、index(当前项的索引)和array(数组本身)。
2 . thisArg :可选参数。用来当作callback 函数内this的值的对象,即callback 函数的执行上下文;
forEach 方法按升序为数组中含有效值的每一项执行一次callback 函数,那些已删除(使用delete方法等情况)或者从未赋值的项将被跳过(但不包括哪些值为 undefined 的项)。
兼容性:不兼容IE6~8。
根据forEach()的语法写出兼容IE6~8的写法如下:
兼容性写法:
if ( !Array.prototype.forEach) {
Array.prototype.forEach = function forEach(callback) {
// 获取数组长度
var len = this.length;
if(typeof callback != "function") {
throw new TypeError();
}
// thisArg为callback 函数的执行上下文环境
var thisArg = arguments[1];
for(var i = 0; i < len; i++) {
if(i in this) {
// callback函数接收三个参数:当前项的值、当前项的索引和数组本身
callback.call(thisArg, this[i], i, this);
}
}
}
}
调用示例:
var arr = ["a", "b", "c", "a", "d", "a"];
arr.forEach(function(ele, index, array){
if(ele == "a") {
array[index] = "**";
}
});
alert(newArr); // ["**", "b", "c", "**", "d", "**"]
三. map()
map() 方法返回一个由原数组中的每个元素调用一个指定方法后的返回值组成的新数组。
语法:
array.map(callback[, thisArg])
参数:
1 . callback : 在数组每一项上执行的函数,接收三个参数: currentValue(当前项的值)、index(当前项的索引)和array(数组本身);
2 . thisArg :可选参数。用来当作callback 函数内this的值的对象,即callback 函数的执行上下文;
兼容性:不兼容IE6~8。
根据map()的语法写出兼容IE6~8的写法如下:
兼容性写法:
if (!Array.prototype.map) {
Array.prototype.map = function(callback) {
// 获取数组长度
var len = this.length;
if(typeof callback != "function") {
throw new TypeError();
}
// 创建跟原数组相同长度的新数组,用于承载经回调函数修改后的数组元素
var newArr = new Array(len);
// thisArg为callback 函数的执行上下文环境
var thisArg = arguments[1];
for(var i = 0; i < len; i++) {
if(i in this) {
newArr[i] = callback.call(thisArg, this[i], i, this);
}
}
return newArr;
}
}
调用示例:
var arr = ["a", "b", "c"];
var newArr = arr.map(function(ele, index, array){
ele += "12";
return ele;
});
alert(newArr); // ["a12", "b12", "c12"]
四. filter()
filter() 方法利用所有通过指定函数测试的元素创建一个新的数组,并返回。
语法:
arr.filter(callback[, thisArg])
参数:
1 . callback : 在数组每一项上执行的函数,接收三个参数: currentValue(当前项的值)、index(当前项的索引)和array(数组本身);
2 . thisArg :可选参数。用来当作callback 函数内this的值的对象,即callback 函数的执行上下文;
filter 为数组中的每个元素调用一次 callback 函数,并利用所有使得 callback 返回 “true” 的元素创建一个新数组。callback 只会在已经赋值的索引上被调用,对于那些已经被删除或者从未被赋值的索引不会被调用。那些没有通过 callback 测试的元素只会被跳过,不会被包含在新数组中。filter 不会改变原数组。
兼容性:不兼容IE6~8。
根据filter()的语法写出兼容IE6~8的写法如下:
兼容性写法:
if (!Array.prototype.filter) {
Array.prototype.filter = function(callback) {
// 获取数组长度
var len = this.length;
if(typeof callback != "function") {
throw new TypeError();
}
// 创建新数组,用于承载经回调函数修改后的数组元素
var newArr = new Array();
// thisArg为callback 函数的执行上下文环境
var thisArg = arguments[1];
for(var i = 0; i < len; i++) {
if(i in this) {
if(callback.call(thisArg, this[i], i, this)) {
newArr.push(val);
}
}
}
return newArr;
}
}
调用示例:
var arr = [1, 2, 3, 4, 3, 2, 5];
var newArr = arr.filter(function(ele, index, array){
if(ele < 3) {
return true;
}else {
return false;
}
});
alert(newArr); // [1, 2, 2]
五. some()
some() 方法测试数组中的某些元素是否通过了指定函数的测试。返回布尔值。some() 被调用时不会改变数组。
语法:
arr.some(callback[, thisArg])
参数:
1 . callback : 在数组每一项上执行的函数,接收三个参数: currentValue(当前项的值)、index(当前项的索引)和array(数组本身);
2 . thisArg :可选参数。用来当作callback 函数内this的值的对象,即callback 函数的执行上下文;
some() 为数组中的每一个元素执行一次 callback 函数,直到找到一个使得 callback 返回一个true 的值。如果找到了这样一个值,some() 将返回 true。否则返回 false。
兼容性:不兼容IE6~8。
根据some()的语法写出兼容IE6~8的写法如下:
兼容性写法:
if (!Array.prototype.some) {
Array.prototype.some = function(callback) {
// 获取数组长度
var len = this.length;
if(typeof callback != "function") {
throw new TypeError();
}
// thisArg为callback 函数的执行上下文环境
var thisArg = arguments[1];
for(var i = 0; i < len; i++) {
if(i in this && callback.call(thisArg, this[i], i, this)) {
return true;
}
}
return false;
}
}
调用示例:
var arr = [1, 2, 3, 4, 3, 2, 5];
var newArr = arr.some(function(ele, index, array){
if(ele < 2) {
return true;
}else {
return false;
}
});
alert(newArr); // true
六. every()
every() 方法测试数组的所有元素是否都通过了指定函数的测试。every() 不会改变原数组。
语法:
arr.every(callback[, thisArg])
参数:
1 . callback : 在数组每一项上执行的函数,接收三个参数: currentValue(当前项的值)、index(当前项的索引)和array(数组本身);
2 . thisArg :可选参数。用来当作callback 函数内this的值的对象,即callback 函数的执行上下文;
every() 方法为数组中的每个元素执行一次 callback 函数。只有所有元素都在callback函数中返回true才返回true,否则返回false。
兼容性:不兼容IE6~8。
根据some()的语法写出兼容IE6~8的写法如下:
兼容性写法:
if (!Array.prototype.every) {
Array.prototype.every = function(callback) {
// 获取数组长度
var len = this.length;
if(typeof callback != "function") {
throw new TypeError();
}
// thisArg为callback 函数的执行上下文环境
var thisArg = arguments[1];
for(var i = 0; i < len; i++) {
if(i in this && !callback.call(thisArg, this[i], i, this)) {
return false;
}
}
return true;
}
}
调用示例:
var arr = [1, 2, 3, 4, 3, 2, 5];
var newArr = arr.every(function(ele, index, array){
if(ele < 3) {
return true;
}else {
return false;
}
});
alert(newArr); // false