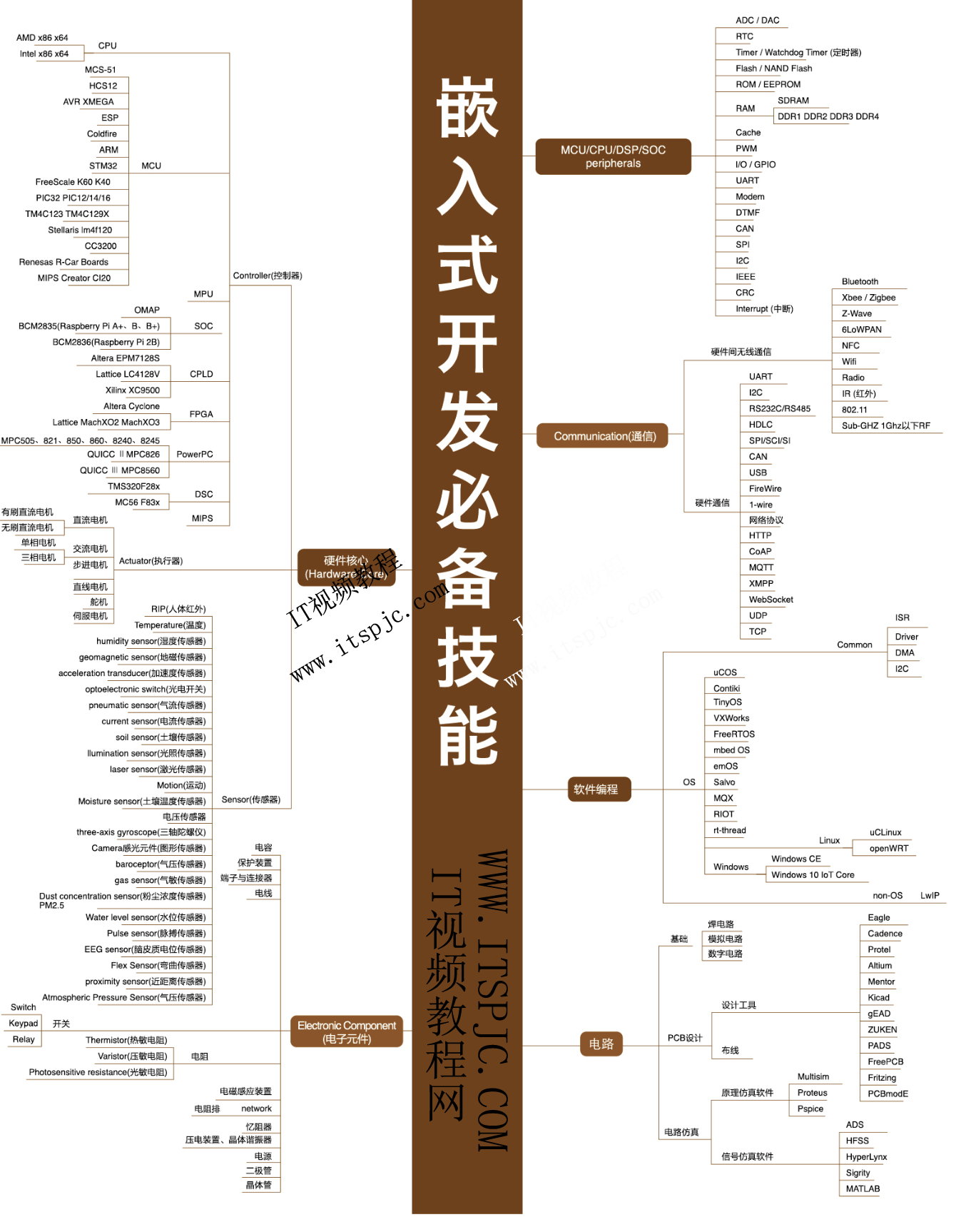
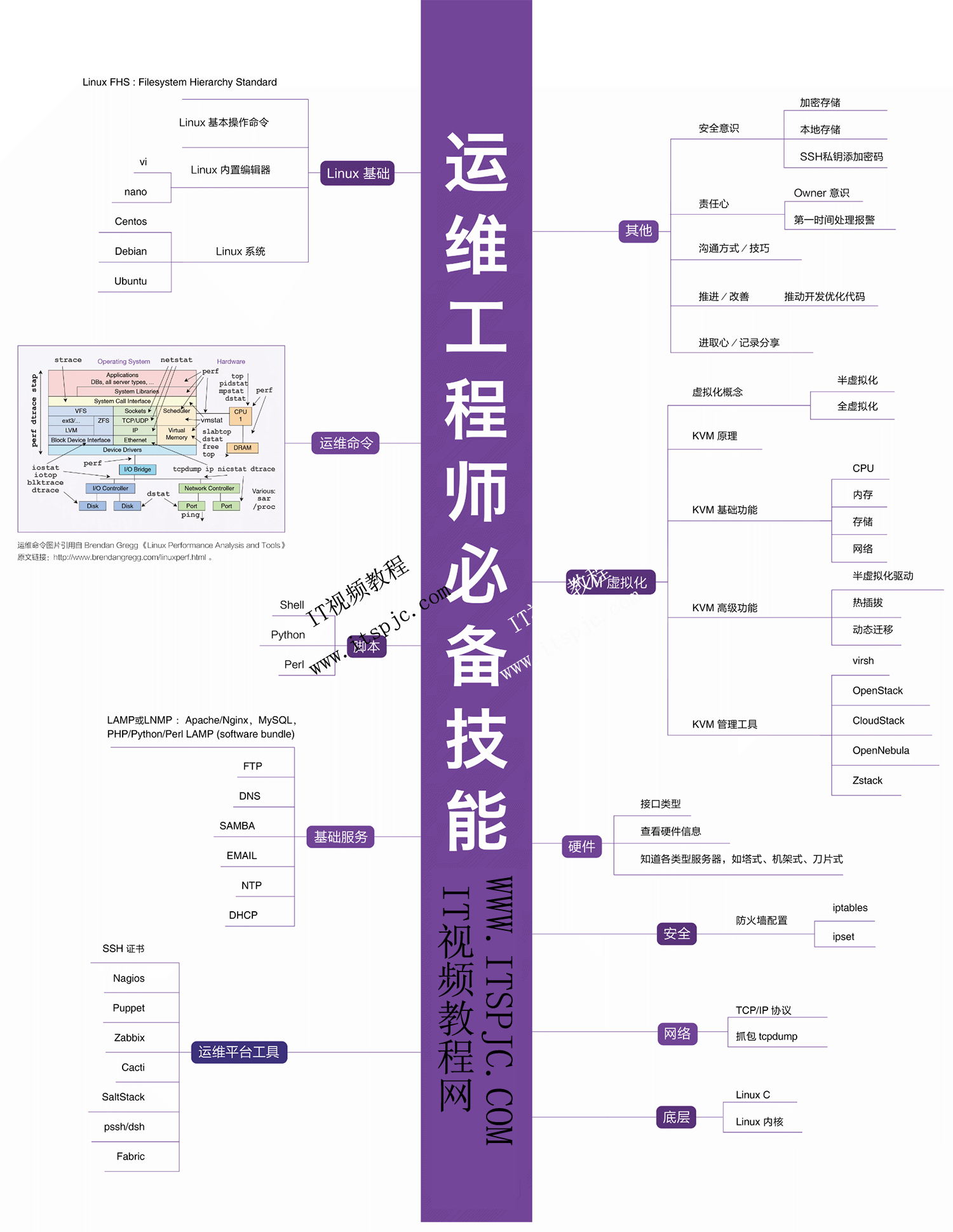
来源: .NET C#杂谈(1):变体 – 协变、逆变与不变 – HiroMuraki – 博客园
0. 文章目的:
介绍变体的概念,并介绍其对C#的意义
1. 阅读基础
了解C#进阶语言功能的使用(尤其是泛型、委托、接口)
2. 从示例入手,理解变体
变体这一概念用于描述存在继承关系的类型间的转化,这一概念并非只适用于C#,在许多其他的OOP语言中也都有变体概念。变体一共有三种:协变、逆变与不变。其中协变与逆变这两个词来自数学领域,但是其含义和数学中的含义几乎没有关系(就像编程语言的反射和光的反射之间的关系)。从字面上来看这三种变体的名字多少有点唬人,但其实际意思并不难理解。广泛来说,三种变体的意思如下:
- 协变(Covariance):允许使用派生程度更大的类型
- 逆变(Contravariance):允许使用派生程度更小的类型
- 不变(Invariance):只允许目标类型
或者换一种更具体的说法:
- 协变(Covariance):若类型A为协变量,则需要使用类型A的地方可以使用A的某个子类类型。
- 逆变(Contravariance):若类型A为逆变量,则需要使用类型A的地方可以使用A的某个基类类型。
- 不变(Invariance):若类型A为不变量,则需要使用类型A的地方只能使用A类型。
(注意是‘协变/量’而不是‘协/变量’)
为了方便说明三者的含义,先定义两个类:
class Cat { }
class SuperCat : Cat { }
上述代码定义了一个Cat类,并从Cat类派生出一个SupreCat类,如无特殊说明,后文的所有代码都会假设这两个类存在。下面利用这两个类逐一说明三种变体的含义。
2.1 协变:在一个需要Cat的场合,可以使用SuperCat
例如,对于下列代码:
Cat cat = new SuperCat();
cat是一个引用Cat对象的变量,从类型安全的角度来说,它应该只能引用Cat对象,但是由于通常子类总是可以安全地转化为其某一基类,因此你也可以让其引用一个SuperCat对象。要实现这种用子类代替基类的操作就需要支持协变,由于OOP语言基本都支持子类向基类安全转化,所以协变在很多人看来是很十分自然的,也容易理解。
2.2 逆变:在一个需要SuperCat的场合,可以使用Cat
逆变有时也被称为抗变,你可能会觉得逆变的含义非常让人迷惑,因为通常来说基类是不能安全转化为其子类的,从类型安全的角度来看,这一概念应该似乎没有实际的应用场合,尤其是对于静态类型的语言。然而,考虑以下代码:
delegate void Action<T>();
void Feed(Cat cat)
{
...
}
Action<SuperCat> f = Feed;
Feed是一个‘参数为Cat对象的方法’,而f是一个引用‘参数为SuperCat对象的方法’的委托。从类型安全的角度来说,委托f应该只能引用参数为SuperCat对象的方法。然而如果你仔细思考上述代码,就会意识到既然委托f在调用时需要传入的是一个SuperCat对象,那么可以处理Cat类型的Feed方法显然也可以处理SuperCat(因为SuperCat可以安全转化为Cat),因此上面的代码从逻辑上来说是可以正常运行的。那么也就是说,本来需要SuperCat类型的地方(这里是委托的参数类型)现在实际给的却是Cat类型,要实现这种用基类代替子类的操作就需要逆变。
不过,结合上述,你会发现所谓逆变实际还是依靠‘子类可以向基类安全转化’这一原则,只是因为我们是从委托f的角度去考虑而已。
2.3 不变:在一个需要Cat的场合,只能使用Cat
相比逆变和协变,不变更容易理解:只接受指定类型,不接受其基类或者子类。比如如果Cat类型具有不变性,那么下述代码将无法通过编译:
Cat cat = new SuperCat();
显然不变从表现上来说是理所当然与符合常识的,故本文主要阐述协变与抗变。
3. C#中的变体
3.1 C#中的变体
同大多数语言一样,C#同样遵循‘基类引用可以指向子类’这一基本原则,因此对C#来说协变是普遍存在的:
Feed(Cat cat)
{
...
}
Cat cat = new SuperCat();
SuperCat superCat = new SuperCat();
Feed(superCat);
C#中的不变体现在值类型上,这是因为值类型都不允许继承与被继承,自然也不存在基类或子类的概念,也不存在类型间通过继承转化的情况。
C#中的逆变在一般情况下没有体现,因为将基类转化为派生类是不安全的,C#不支持这种操作。所以逆变对C#来说很多时候其实只是概念上的认识,真正让逆变对C#有意义的情况是使用泛型的场合,这在接下来就会提到。
从学习语言语法的角度来说,了解变体对学习C#的帮助其实不大,但如果想更进一步理解C#中泛型的设计原理,就有必要理解变体了。
3.2 泛型与变体
理解变体对理解C#的泛型设计原理有重要意义,C#中泛型的类型参数默认为不变量,但可以是out与in关键字来指示类型为参数为协变量或者逆变量。简单来说,in关键字用于修饰输入参数的兼容性,out关键字用于修饰输出参数的兼容性。这一节会通过具体的泛型使用示例来解释变体概念对C#泛型的意义。
3.2.1 泛型委托
(1)输入参数的兼容性:逆变
考虑下面的泛型委托声明:
delegate void Action<T>(T arg);
上述委托可以接受一个参数类型为T,返回类型为TReturn的委托。下面来定义一个方法:
void Feed(Cat cat)
{
}
Foo是一个接受一个Cat对象,并返回一个SuperCat对象的方法。因此,下面的代码是理所当然的:
Action<Cat> act = Feed;
然而,从逻辑上来讲,下面的代码也应该是合法的:
Action<SuperCat> act = Feed;
委托act接受的参数类型为SuperCat,也就是说当调用委托act的时候传入的将会是一个SuperCat对象,显然SuperCat对象可以安全地转换为Foo所需要的Cat对象,因此这一转变是安全的。我们以委托act的视角来看:本来act应该引用的是一个‘参数类型为SuperCat’的方法,然而我们却把一个‘参数类型为Cat的’Feed方法赋值给了它,但结合上面的分析我们知道这一赋值行为是安全的。也就是说,本来此时泛型委托Action<T>中泛型类型参数T需要的类型是SuperCat,但现在实际给的类型却是Cat:

(红色是方法参数类型)
Cat是SuperCat的基类,也就是说这时候泛型委托Action<T>的类型参数T这个位置上出现了逆变。尽管从逻辑上来说这是合理的,但是C#中泛型类型参数默认具有不变性,因此如果要使上述代码通过编译,还需要将泛型委托Func的类型参数T声明为逆变量,在C#中,可以通过在泛型类型参数前添加in关键字将泛型参数声明为逆变量:
delegate void Action<in T>(T arg);
(2):输出参数的兼容性:协变
另一方面,下面的代码从逻辑上说也应该是合法的:
delegate T Func<T>();
SuperCat GetSuperCat()
{
...
}
Func<Cat> func = GetSuperCat;
委托func被调用时需要返回一个Cat对象,而GetSuperCat返回的是一个SuperCat对象,这显然是满足func的要求的:

同样以委托func的视角来看,本来需要类型Cat的地方现在实际给的类型是SuperCat,也就是说,此时出现了协变。同样的,如果要使上述代码通过编译,应该需要将Func的类型参数T声明为协变量,可以在泛型参数前添加out关键字将泛型类型参数声明为协变量:
delegate T Func<out TReturn>();
3.2.2 泛型接口
(1)输出参数的兼容性:协变
假设现有以下用于表示集合的接口声明与实现该接口的泛型类:
interface ICollection<T>
{
}
class Collection<T> : ICollection<T>
{
}
根据上述定义,理所当然的,下面的语句是合法的:
ICollection<Cat> cats = new Collection<Cat>();
然而,从逻辑上讲,下面的语句也应该是合法的:
ICollection<Cat> cats = new Collection<SuperCat>();
原因如下:既然SuperCat是Cat的子类,那么Collection中的任意一个SuperCat对象都应该可以安全转化为Cat对象,那么SuperCat的集合也应该视为Cat的集合。从事实上讲,若对任何一个需要Cat对象集合的方法,即便传入的是一个SuperCat对象的集合也应该可以正常工作。同样以类型为ICollection<Cat>的接口变量cats的视角来看,ICollection<Cat>类型上本来应该为Cat类型的地方现在被SuperCat类型所替代:
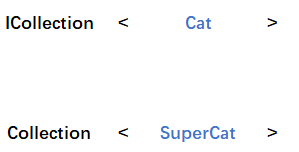
SuperCat代替了Cat,也就是说出现了协变,那么如果要使上述代码通过编译,则需要将类型参数T声明为协变量:
interface ICollection<out T>
{
}
C#中的IEnumerable接口就将其类型参数T声明为了协变量,因此下面的代码可以正常运行:
IEnumerable<Cat> cats = new List<SuperCat>();
(2)输入参数的兼容性:逆变
接着再来考虑一个接口与实现类:
interface IHand<T>
{
void Pet(T animal);
}
class Hand<T> : IHand<T>
{
void Pet(T animal) { ... }
}
下面的代码应该是合理的:
SuperCat cat = new SuperCat();
IHand<SuperCat> hand = new Hand<Cat>();
hand.Pet(cat);
原因如下:实现IHand<Cat>接口的Hand<Cat>的Pet方法可以处理Cat类型,显然其应该也可以处理作为Cat子类的SuperCat。同样的,以类型为IHand<SuperCat>的接口变量hand来看,本来应该需要类型为SuperCat的地方现在实际却是Cat类型:

Cat替代了SuperCat,也就是说此时发生了逆变。同样的,如果要让上述代码通过编译,需要将IHand<>的类型参数T声明为逆变量:
interface IHand<in T>
{
void Pet(T animal);
}
这样下述代码就可以通过编译:
IHand<SuperCat> hand = new Hand<Cat>();
3.2.3 泛型方法
与泛型委托和泛型接口不同的是,泛型方法不允许修改类型参数的变体类型,泛型方法的类型参数只能是不变量,因为让泛型方法的类型参数为变体没有意义。一方面,泛型方法的类型参数会在方法被调用时直接使用目标类型,因此不存在需要变体的情况:
void Pet<T>(T cat)
{
...
}
Pet(new Cat());
Pet(new SuperCat());
另一方面,你不能给一个方法赋值。
TReturn Foo<T, TReturn>(T t)
{
...
}
Foo = ...;
显然上述代码是无法通过编译的。综上,给泛型方法的类型参数定义为协变量或者逆变量是没有意义的,因此也没有必要提供这一功能。
3.2.4 泛型类
C#中的泛型类的类型参数同样只允许为不变量,这里以常用的泛型List<>为例,下面的代码是不允许的:
List<Cat> cats = new List<SuperCat>();
哪怕从概念上说一个SuperCat的对象的集合用于需要Cat对象的集合的场景是合法的,但是这一行为确实是不允许的,原因是CLR不支持。此外,C#限制协变量只能为方法的返回类型(后文会解释),所以下面的类定义是不可行的:
class Foo<out T>
{
public T Get() { }
public Set(T arg) { }
public T Field;
}
既然连字段的类型都不能是协变的泛型类型,那么显然这样的类没有太大的意义。由于以上原因,泛型变体对于定义泛型类的意义不大。
4. 变体限制
C#对泛型中允许变体的类型参数有严格的使用限制,主要限制如下:
- 协变量只能作为输出参数(方法的返回值,不包out参数)
- 逆变量只能作为输入参数(方法的参数,不包括in、out以及ref参数)
- 只能是不变量、协变量或者逆变量三者之一
上述限制也说明了为何C#选择用out关键字来修饰协变量,in关键字来修饰逆变量。如果没有以上限制,可能出现一些很奇怪的操作,例如:
(1)假设:协变量可用于输入参数:
delegate void Action<out T>(T arg);
void Call(SuperCat cat)
{
}
Action<Cat> f = GetCat;
上述代码中当委托f被调用时可能会传入一个Cat对象,然而其引用Call方法需要的是一个SuperCat对象,此时Cat类型无法安全转化为SuperCat类型,因此会出现运行时错误。
(2)假设:逆变量可用于方法的输出参数
delegate T Func<in T>();
Cat GetCat()
{
...
}
Func<SuperCat> f = GetCat;
上述代码中当委托f被调用后,应当返回一个SuperCat对象,然而其引用的GetCat方法返回的只是一个Cat对象,同样,会出现运行时错误。
从上述例子中可以看出,对变体的适用范围进行限制显然有助于提高编写更安全的代码。
6. 变体杂谈
6.1 历史问题
C#的数组支持协变,也就是说下面的代码是允许的:
Cat[] cats = new SuperCat[10];
咋一看没什么问题,SuperCat的数组当然可以安全转化为Cat数组使用,然而这意味着下述代码也能通过编译:
object[] objs = new Cat[10];
objs[0] = new Dog();
但显然这会在运行时出现错误。数组协变在某些场合下可能有用,但很多时候错误的使用或者误用会导致没必要的运行时错误,因此应当尽可能避免使用这一特性。
6.2 缺点
使用变体要求类型可以在引用类型的层面上进行转换,简单来说就是变体只作用于引用类型之间。因此尽管object是所有类型的基类,但是下述代码依然无法通过编译:
IEnumerable<object> data = new List<int>();
这是由于int为值类型,显然值类型无法在引用类型层面转化为object。