[转载]SQL Server性能调优:资源管理之内存管理篇(上) – hjq19851202 – 博客园.
对SQL Server来说,最重要的资源是内存、Disk和CPU,其中内存又是重中之重,因为SQL Server为了性能要求,会将它所要访问的数据全部(只要内存足够)放到缓存中。这篇就来介绍SQL Server的内存管理体系。
SQL Server作为Windows上运行的应用程序,必须接受Windows的资源管理,利用Windows的API来申请和调度各类资源。但是,由于 Windows的资源管理体系,是为了满足大多数的应用程序所设计的,这对于SQL Server这种定位于企业级、支持多用户和高并发性的数据库应用程序来说不是很适合,为此SQL Server开发了自己的一套资源管理体系——SQLOS(SQL操作系统)。也就是说SQL Server的资源管理分两层,第一层是在Windows上,通过Windows的API来申请资源。第二层是在SQL Server上,利用SQLOS来决定如何使用从Windows那里申请来的资源。
一、操作系统层面的SQL Server内存管理
由于SQL server的内存是通过Windows的API来申 请的,如果Windows自己本身就缺少内存,SQL Server由于申请不到内存,性能自然受影响。因此做SQL Server的内存检测,第一步就是查看系统层面的内存,以确保系统本身不缺内存,这一步简单但是必不可少。这里先介绍Windows的一些内存管理理 念,然后介绍如何检查系统的内存情况。
1、Windows的一些内存术语
Virtual Address Space(虚拟地址空间):应用程序能够申请访问的最大地址空间。对于32位的服务器,地址寻址空间为2的32次方,也就是4GB,但是这4GB并不是 都给SQL Server使用的,默认情况下是用户态2GB,核心态2GB,所以说对于32位的系统SQL Server只有2GB的内存可供使用。不过可以通过设置/3GB boot.int参数,来调整系统的配置,使用户态为3GB,核心态为1GB。或者开启AWE(地址空间扩展),将寻址空间扩展为64GB,不过该设置有 缺陷,下面会分析。
Physical Memory(物理内存):也就是通常所说的电脑的内存大小。
Reserved Memory(保留地址):应用程序访问内存的方式之一,先保留(Reserve)一块内存地址空间,留着将来使用(SQL Server中的数据页面使用的内存就是通过这个方式申请 的)。被保留的地址空间,不能被其他程序访问,不然会出现访问越界的报错提示。
Committed Memory(提交内存):将保留(Reserve)的内存页面正式提交(Commit)使用。
Shared Memory(共享内存):对一个以上进程可见的内存。
Private Bytes(私有内存):某进程提交的地址空间中,非共享的部分。
Working Set:进程的地址空间中存放在物理内存中的部分。
Page Fault(页面访问错误):访问在虚拟地址空间,但不存在于Working Set中会发生Page Fault。这个又分两种情况,第一种是目标页面在硬盘上,这钟访问会带来硬盘读写,这种称为Hard Fault。另外一种是目标页面在物理内存中,但是不是该进程的Working Set下,Windows只需要重新定向一下,成为Soft Fault。由于Soft Hard不带来硬盘读写,对系统的性能影响很小,因此管理员关心的是Hard Fault。
System Working Set:Windows系统的Working Set。
2、Windows的内存检测
可以通过Windows的性能监视器来检测Windows的内存使用情况,如何使用性能监视器,可以看这篇文章《使用“性能监视器”监视系统性能/运行情况》 。在检测内存上,比较重要的计数器有下面一些:
分析Windows系统的内存总体使用情况的计数器:
Memory:Available MBytes:系统中空闲的物理内存数。
Memory:Pages/Sec:由于Hard Page的发生,每秒钟从硬盘中读取或者写入的页面数。该计数器等于Memory:Pages Input/Sec与Memory:Pages Output/Sec之和。
分析Windows系统自身的内存使用情况的计数器:
Memory:Cache Bytes:系统的Working Set,也就是Windows系统使用的物理内存数。
对于每个进程的内存使用情况的计数器:
Process:Private Bytes:进程提交的地址空间中非共享的部分。
Process:Working Set:进程的地址空间中存放在物理内存中的那部分。
从这些计数器中,我们可以看到系统中是否还有空闲内存,哪个进程使用的内存最多,在发生问题的时候是否有内存使用量突变等情况。这为接下来分析SQL Server的使用提供一个前提条件。
二、SQL Server内部的内存管理
1、内存使用分类
按用途分类
1)Database cache(数据页面)。SQL Server中的页面都是以8KB为一个页面存储的。当SQL Server需要用到某个页面时,它会将该页面读到内存中,使用完后会缓存在内存中。在内存没有压力的情况下,SQL Server不会将页面从内存中删除。如果SQL Server感觉到内存的压力时,会将最长时间没有使用的页面从内存中删除来空出内存。
2)各类Consumer(功能组件)
Connection的连接信息
General:一组大杂烩。语句的编译、范式化、每个锁数据结构、事务上下文、表格和索引的元数据等
Query Plan:语句和存储过程的执行计划。和Database cache类似,SQL Server也会将执行计划缓存以供将来使用,减少编译时间。
Optimizer:生成执行计划的过程中消耗的内存。
Utilities:像BCP、Log Manager、Backup等比较特殊的操作消耗的内存。
3)线程内存:存放进程内每个线程的数据结构和相关信息消耗的内存,每个线程需0.5MB的内存。
4)第三方代码消耗的内存:SQL Server的进程里,会运行一些非SQL Server自身的代码。例如:用户定义的CLR或Extended Stored Procedure代码。
按申请方式分类
1)预先Reserve一块大的内存,然后在使用的时候一块一块的Commit。Database Page是按这种方式申请的。
2)直接用Commit方式申请的内存,成为Stolen方式。除了Database Page之外其他内存基本都是按这种方式申请的。
按申请内存的大小分类
1)申请小于等于8KB为一个单位的内存,这些内存称为Buffer Pool
2)申请大于8KB为一个单位的内存,这些内存称为Multi-Page(或MemToLeave)
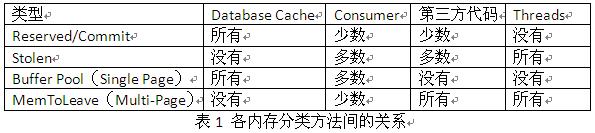
SQL Server对于Database Page都是采用先Reserved后Commit的方式申请的,而数据页都是以8KB为单位进行申请的。
对于Consumer中的内存申请,一般都是按Stolen方式申请的,且大多数的执行计划的大小都是小于8KB的,少数特别复杂的存储过程的执行计划会超过8KB,默认的连接的数据包是4KB,除非客户端特别设置了超过8KB(不建议)
第三方代码的内存申请一般是按Stolen方式申请的,个别比如CLR中可能会用Reserved/Commit的方式申请。
线程的内存每个都以0.5MB的方式申请,自然是放在MemToLeave中。
之所以花了这么大篇幅来讲SQL Server的内存分类,是因为SQL Server尤其是32位的SQL Server对不同种类的内存的申请大小是不一样的,对Commit、Stolen和MemTOLeave等类型的内存是有限制的。因此会出现系统中还有空闲内存,但是SQL Server不会申请使用的现象。
2、各部分内存的大小限制
1)32位的Windows
在SQL Server启动时,会预先分配好MemToLeave区域的大小。默认大小为256MB+256(SQL Server配置的允许最大线程数)* 0.5MB=384MB,因此Buffer Pool中的最大值为2GB-384MB=1.664G。如果使用了AWE技术,可以将系统的扩展地址空间达到64GB,但由于AWE扩展出来的地址只能用Reserved/Commit方式申请,为此MemToLeave的内存还是384MB,Buffer Pool中的Stolen的最大内存为1.664G,剩余的内存都可以为Database Page页面使用。
2)64位的Windows
32位的SQL Server。由于64位的操作系统,核心态不再占用32位进程的虚拟地址空间,因此MemToLeave的大小还是为384MB,Buffer Pool可以达到3.664G。如果还开启了AWE,这3.664GB可以全部用于Buffer Pool中的Stolen,剩余的内存都可以给Database Page页面使用。不过这种情况很少见,哪里用64位操作系统的机器装32位的哦-_- 。
64位的SQL Server。所有的内存都无限申请的,有需要就申请。
3、SQL Server内存使用情况的分析
一般来说有两种方式,第一种就是用来分析系统内存情况时使用的用性能计数器来分析,第二种是使用动态管理视图(DMV,只适用于SQL Server2005和2008)
1)SQL Server性能计数器
SQLServer:Memory Manager:Total Server Memory(KB):SQL Server缓冲区提交的内存。不是SQL Server总的使用内存,只是Buffer Pool中的大小。
SQLServer:Memory Manager:Target Server Memory(KB):服务器可供SQL Server使用的内存量。一般是由SQL Server能访问到的内存量和SQL Server的sp_Configure配置中的Max Server Memory值中的较小值算得。
SQLServer:Memory Manger:Memory Grants Pending:等待内存授权的进程总数。如果该值不为0,说明当前有用户的内存申请由于内存压力被延迟,这意味着比较严重的内存瓶颈。
SQLServer:Buffer Manager:Buffer Cache Hit Ratio:数据从缓冲区中找到而不需要从硬盘中去取的百分比。SQL Server在运行一段时间后,该比率的变化应该很小,而且都应该在98%以上,如果在95%以下,说明有内存不足的问题。
SQLServer:Buffer Manager:Lazy Writes/Sec:每秒钟被惰性编辑器(Lazy writer)写入的缓冲数。当SQL Server感觉到内存压力的时候,会将最久没有使用的数据页面和执行计划从缓冲池中清理掉,做这个动作的就是Lazy Writer。
Page Life Expectancy:页面不被引用后,在缓冲池中停留的秒数。在内存没有压力的情况下,页面会一直待在缓冲池中,Page Life Expectancy会维持在一个比较高的值,如果有内存压力时,Page Life Expectancy会下降。所以如果Page Life Expectancy不能维持在一个值上,就代表SQLServer有内存瓶颈。
SQLServer:Buffer Manager:Database Pages :就是Database Cache的大小。
SQLServer:Buffer Manager:Free Pages:SQL Server中空闲可用的大小。
SQLServer:Buffer Manager:Stolen Pages:Buffer Pool中Stolen的大小。
SQLServer:Buffer Manager:Total Pages:Buffer Pool的总大小(等于Database Pages+Free Pages+Stolen Pages)。该值乘以8KB,应该等于Memory Manager:Total Server Memory的值。
从上面这些计数器中我们就能了解SQL Server的内存使用情况,结合前面说的系统层的计数器大概能看出是否存在内存瓶颈。
2)内存动态管理视图
在SQL Server 2005以后,SQL Server的内存管理是使用Memory Clerk的方式统一管理。所有的SQL Server的内存的申请或释放,都需要通过它们的Clerk,SQL Server也通过这些Clerk的协调来满足不同需求。通过查询这些DMV,可以得到比用性能计数器更加详细的内存使用情况。
我们可以通过下面的查询语句来检测SQL Server的Clerk的内存使用情况。

 使用sys.dm_os_memory_clerks查看内存使用情况
使用sys.dm_os_memory_clerks查看内存使用情况
SELECT type, —Clerk的类型
sum(virtual_memory_reserved_kb) as vm_Reserved_kb, — 保留的内存
sum(virtual_memory_committed_kb) as vm_Committed_kb, —提交的内存
sum(awe_allocated_kb) as awe_Allocated_kb, — 开启AWE后使用的内存
sum(shared_memory_reserved_kb) as sm_Reserved_kb, — 共享的保留内存
sum(shared_memory_committed_kb) as sm_Committed_kb, — 共享的提交内存
sum(single_pages_kb) as SinlgePage_kb, — Buffer Pool中的Stolen的内存
sum(multi_pages_kb) as MultiPage_kb — MemToLeave的内存
FROM sys.dm_os_memory_clerks
GROUP BY type
ORDER BY type
从上面的查询语句,我们可以算出前面提到的内存大小
Reserved/Commit = sum(virtual_memory_reserved_kb) / sum(virtual_memory_committed_kb)
Stolen = sum(single_pages_kb) + sum(multi_pages_kb)
Buffer Pool = sum(virtual_memory_committed_kb) + sum(single_pages_kb)
MemToLeave = sum(multi_pages_kb)
通过上面的介绍我们可以知道SQL Server总体和各部分内存的使用情况,如果我想知道数据页的缓存中到底缓存了哪些数据,这些数据是属于哪个数据库的哪个表中的呢?执行计划又是缓存了哪些语句的执行计划呢?这也可以通过DMV查看的到。
查看内存中的数据页面缓存的是哪个数据库的哪个表格的数据
declare @name nvarchar(100)
declare @cmd nvarchar(1000)
declare dbnames cursor for
select name from master.dbo.sysdatabases
open dbnames
fetch next from dbnames into @name
while @@fetch_status = 0
begin
set @cmd = ‘select b.database_id, db=db_name(b.database_id),p.object_id,p.index_id,buffer_count=count(*) from ‘
—这里的object_id代表是SQL Server中的对象号,index_id代表是索引号,buffer_count代表的是页面数
+ @name + ‘.sys.allocation_units a, ‘
+ @name + ‘.sys.dm_os_buffer_descriptors b, ‘ + @name + ‘.sys.partitions p
where a.allocation_unit_id = b.allocation_unit_id
and a.container_id = p.hobt_id
and b.database_id = db_id(”’ + @name + ”’)
group by b.database_id,p.object_id, p.index_id
order by b.database_id, buffer_count desc‘
exec (@cmd)
fetch next from dbnames into @name
end
close dbnames
deallocate dbnames
go
— 根据上面取出来的@object_id找出是哪个数据库的哪个表
SELECT s.name AS table_schema, o.name as table_name —使用的就是table_schema.table_name表
FROM sys.sysobjects AS o INNER JOIN
sys.schemas AS s ON o.uid = s.schema_id
WHERE (o.id = @object_id)
— 根据上面取出来的@object_id和@index_id找出索引的名称
SELECT id, indid, name as index_name — index_name就是索引的名称
FROM sys.sysindexes
WHERE (id = @object_id) AND (indid = @index_id)
— 根据上面取出来的表名table_schema.table_name和索引的名称index_name,还可以找出该索引是建立在哪些字段上的
EXEC sp_helpindex ‘table_schema.table_name‘
查看内存中缓存的执行计划,以及执行计划对应的语句:
— 输出可能较大,请小心使用
SELECT usecounts, refcounts, size_in_bytes, cacheobjtype, objtype, text
FROM sys.dm_exec_cached_plans cp CROSS APPLY sys.dm_exec_sql_text(plan_handle)
ORDER BY objtype DESC
写了这么多竟然发现大多数讲的还是数据收集的这一部分,相应的解决办法还没有讲到。。。由于文章太长,具体的解决方法将在下一篇讲解,下一篇将从Database Page、Stolen和Multi-Page三部分的具体瓶颈来讲解。