[转载]如何向妻子解释OOD – 倪大虾 – 博客园.
前言
此文译自CodeProject上<How I explained OOD to my wife>一文,该文章在Top Articles上排名第3,读了之后觉得非常好,就翻译出来,供不想读英文的同学参考学习。
作者(Shubho)的妻子(Farhana)打算重新做一名软件工程师(她本来是,后来因为他们孩子出生放弃了),于是作者就试图根据自己在软件开发设计方面的经验帮助她学习面向对象设计(OOD)。
自作者从事软件开发开始,作者常常注意到不管技术问题看起来多复杂,如果从现实生活的角度解释并以对答的方式讨论,那么它将变得更简单。现在他们把在OOD方面有些富有成效的对话分享出来,你可能会发现那是一种学习OOD很有意思的方式。
下面就是他们的对话:
OOD简介
Shubho:亲爱的,让我们开始学习OOD吧。你了解面向对象原则吗?
Farhana:你是说封装,继承,多态对吗?我知道的。
Shubho:好,我希望你已了解如何使用类和对象。今天我们学习OOD。
Farhana:等一下。面向对象原则对面向对象编程(OOP)来说不够吗?我的意思是我会定义类,并封装属性和方法。我也能根据类的关系定义它们之间的层次。如果是,那么还有什么?
Shubho:问得好。面向对象原则和OOD实际上是两个不同的方面。让我给你举个实际生活中的例子帮你弄明白。
再你小时候你首先学会字母表,对吗?
Farhana:嗯
Shubho:好。你也学了单词,并学会如何根据字母表造词。后来你学会了一些造句的语法。例如时态,介词,连词和其他一些让你能造出语法正确的句子。例如:
“I” (代词) “want” (动词) “to” (介词) “learn” (动词) “OOD”(名词)。
看,你按照某些规则组合了单词,并且你选择了有某些意义的正确的单词结束了句子。
Farhana:OK,这意味着什么呢?
Shubho:面向对象原则与这类似。OOP指的是面向对象编程的基本原则和核心思路。在这里,OOP可以比作英语基础语法,这些语法教你如何用单词构造有意义且正确的句子,OOP教你在代 码中构造类,并在类里封装属性和方法,同时构造他们之间的层次关系。
Farhana:嗯..我有点感觉了,这里有OOD吗?
Shubho:马上就有答案。现在假定你需要就某些主题写几篇文章或随笔。你也希望就几个你擅长主体写基本书。对写好文章/随笔或书来说,知道如何造句是不够的,对吗?为了使读者能更轻 松的明白你讲的内容,你需要写更多的内容,学习以更好的方式解释它。
Farhana:看起来有点意思…继续。
Shubho:现 在,如果你想就某个主题写一本书,如学习OOD,你知道如何把一个主题分为几个子主题。你需要为这些题目写几章内容,也需要在这些章节中写前言,简介,例 子和其他段落。 你需要为写个整体框架,并学习一些很好的写作技巧以便读者能更容易明白你要说的内容。这就是整体规划。
在软件开发中,OOD是整体思路。在某种程度上,设计软件时,你的类和代码需能达到模块化,可复用,且灵活,这些很不错的指导原则不用你重新发明创造。确实有些原则你已经在你的类和对象中已经用到了,对吗?
Farhana:嗯…有个大概的印象了,但需要继续深入。
Shubho:别担心,你马上就会学到。我们继续讨论下去。
为什么要OOD?
Shubho:这是一个非常重要的问题。当我们能很快地设计一些类,完成开发并发布时,为什么我们需要关心OOD?那样子还不够吗?
Farhana:嗯,我早先并不知道OOD,我一直就是开发并发布项目。那么关键是什么?
Shubho:好的,我先给你一句名言:
走在结冰的河边不会湿鞋,开发需求不变的项目畅通无阻(Walking on water and developing software from a specification are easy if both are frozen)
–Edward V. Berard
Farhana:你的意思是软件开发说明书会不断变化?
Shubho:非常正确!软件开发唯一的真理是“软件一定会变化”。为什么?
因为你的软件解决的是现实生活中的业务问题,而现实生活中得业务流程总是在不停的变化。
假设你的软件在今天工作的很好。但它能灵活的支持“变化”吗?如果不能,那么你就没有一个设计敏捷的软件。
Farhana:好,那么请解释一下“设计敏捷的软件”。
Shubho:”一个设计敏捷的软件能轻松应对变化,能被扩展,并且能被复用。”
并且应用好”面向对象设计”是做到敏捷设计的关键。那么,你什么时候能说你在代码中很好的应用了OOD?
Farhana:这正是我的问题。
Shubho:如果你代码能做到以下几点,那么你就正在OOD:
- 面向对象
- 复用
- 能以最小的代价满足变化
- 不用改变现有代码满足扩展
Farhana:还有?
Shubho:我们并不是孤立的。很多人在这个问题上思考了很多,也花费了很大努力,他们试图做好OOD,并为OOD指出几条基本的原则(那些灵感你能用之于你的OOD)。他们最终也确实总结出了一些通用的设计模式(基于基本的原则)。
Farhana:你能说几个吗?
Shubho:当然。这里有很多涉及原则,但最基本的是叫做SOLID的5原则(感谢Uncle Bob,伟大OOD导师)。
S = 单一职责原则 Single Responsibility Principle
O = 开放闭合原则 Opened Closed Principle
L = Liscov替换原则 Liscov Substitution Principle
I = 接口隔离原则 Interface Segregation Principle
D = 依赖倒置原则 Dependency Inversion Principle
接下去,我们会仔细探讨每一个原则。
单一职责原则
Shubho:我先给你展示一张海报。我们应当谢谢做这张海报的人,它非常有意思。

单一职责原则海报
它说:”并不是因为你能,你就应该做”。为什么?因为长远来看它会带来很多管理问题。
从面向对象角度解释为:”引起类变化的因素永远不要多于一个。”
或者说”一个类有且只有一个职责”。
Farhana:能解释一下吗?
Shubho:当然,这个原则是说,如果你的类有多于一个原因会导致它变化(或者多于一个职责),你需要一句它们的职责把这个类拆分为多个类。
Farhana:嗯…这是不是意味着在一个类里不能有多个方法?
Shubho:不。你当然可以在一个类中包含多个方法。问题是,他们都是为了一个目的。如今为什么拆分是重要的?
那是因为:
- 每个职责是轴向变化的;
- 如果类包含多个职责,代码会变得耦合;
Farhana:能给我一个例子吗?
Shubho:当然,看一下下面的类层次。当然这个例子是从Uncle Bob那里得来,再谢谢他。

违反单一职责原则的类结构图
这里,Rectangle类做了下面两件事:
并且,有两个应用使用了Rectangle类:
- 计算几何应用程序用这个类计算面积;
- 图形程序用这个类在界面上绘制矩形;
这违反了SRP(单一职责原则);
Farhana:如何违反的?
Shubho:你看,Rectangle类做了两件事。在一个方法里它计算了面积,在另外一个方法了它返回一个表示矩形的GUI。这会带来一些有趣的问题:
在计算几何应用程序中我们必须包含GUI。也就是在开发几何应用时,我们必须引用GUI库;
图形应用中Rectangle类的变化可能导致计算几何应用变化,编译和测试,反之亦然;
Farhana:有点意思。那么我猜我们应该依据职责拆分这个类,对吗?
Shubho:非常对,你猜我们应该做些什么?
Farhana:当然,我试试。下面是我们可能要做的:
拆分职责到两个不同的类中,如:
- Rectangle:这个类应该定义Area()方法;
- Rectangle:这个类应继承Rectangle类,并定义Draw()方法。
Shubho:非常好。在这里,Rectangle类被计算几何应用使用,而RectangleUI被图形应用使用。我们甚至可以分离这些类到两个独立的DLL中,那会允许我们在变化时不需要关心另一个就可以实现它。
Farhana:谢谢,我想我明白SRP了。SRP看起来是把事物分离成分子部分,以便于能被复用和集中管理。我们也不能把SRP用到方法级别吗?我的意思是,我们可以写一些方法,它们包含做很多事的代码。这些方法可能违反SRP,对吗?
Shubho:你理解了。你应当分解你的方法,让每个方法只做某一项工作。那样允许你复用方法,并且一旦出现变化,你能购以修改最少的代码满足变化。
开放闭合原则
Shubho:这里是开放闭合原则的海报

开放闭合原则海报
从面向对象设计角度看,它可以这么说:”软件实体(类,模块,函数等等)应当对扩展开放,对修改闭合。”
通俗来讲,它意味着你应当能在不修改类的前提下扩展一个类的行为。就好像我不需要改变我的身体而可以穿上衣服。
Farhana:有趣。你能够按照你意愿穿上不同的衣服来改变面貌,而从不用改造身体。你对扩展开放了,对不?
Shubho:是的。在OOD里,对扩展开发意味着类或模块的行为能够改变,在需求变化时我们能以新的,不同的方式让模块改变,或者在新的应用中满足需求。
Farhana:并且你的身体对修改是闭合的。我喜欢这个例子。当需要变化时,核心类或模块的源代码不应当改动。你能用些例子解释一下吗?
Shubho:当然,看下面这个例子。它不支持”开放闭合”原则。

违反开发闭合原则的类结构
你看,客户端和服务段都耦合在一起。那么,只要出现任何变化,服务端变化了,客户端一样需要改变。
Farhana:理解。如果一个浏览器以紧耦合的方式按照指定的服务器(比如IIS)实现,那么如果服务器因为某些原因被其他服务器(如Apache)替换了,那么浏览器也需要修改或替换。这确实很可怕!
Shubho:对的。下面是正确的设计。
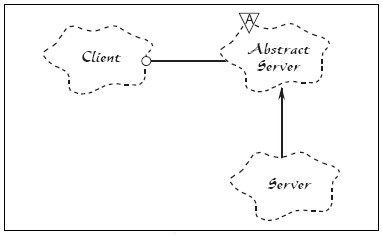
遵循开放闭合原则的类结构
在这个例子中,添加了一个抽象的服务器类,客户端包含一个抽象类的引用,具体的服务类实现了抽象服务类。那么,因任何原因引起服务实现发生变化时,客户端都不需要任何改变。
这里抽象服务类对修改是闭合的,实体类的实现对扩展是开放的。
Farhana:我明白了,抽闲是关键,对吗?
Shubho:是的,基本上,你抽象的东西是你系统的核心内容,如果你抽象的好,很可能在扩展功能时它不需要任 何修改(就像服务是一个抽象概念)。如果在实现里定义了抽象的东西(比如IIS服务器实现的服务),代码要尽可能以抽象(服务)为依据。这会允许你扩展抽 象事物,定义一个新的实现(如Apache服务器)而不需要修改任何客户端代码。
Liskov’s 替换原则
Shubho:”Liskov’s替换原则(LSP)”听起来很难,却是很有用的基本概念。看下这幅有趣的海报:

Liskov替换原则海报
这个原则意思是:”子类型必须能够替换它们基类型。”
或者换个说法:”使用基类引用的函数必须能使用继承类的对象而不必知道它。”
Farhana:不好意思,听起来有点困惑。我认为这个OOP的基本原则之一。也就是多态,对吗?为什么一个面向对象原则需要这么说呢?
Shubho:问的好。这就是你的答案:
在基本的面向对象原则里,”继承”通常是”is a“的关系。如果”Developer” 是一个”SoftwareProfessional“,那么”Developer“类应当继承”SoftwareProfessional“类。在类设计中”Is a“关系非常重要,但它容易冲昏头脑,结果使用错误的继承造成错误设计。
“Liskov替换原则“正是保证继承能够被正确使用的方法。
Farhana:我明白了。有意思。
Shubho:是的,亲爱的,确实。我们看个例子:

Liskov替换原则类结构图
这里,KingFisher类扩展了Bird基类,并继承了Fly()方法,这看起来没问题。
现在看下面的例子:

违反Liskov替换原则类结构图
Ostrich(鸵鸟)是一种鸟(显然是),并从Bird类继承。它能飞吗?不能,这个设计就违反了LSP。
所以,即使在现实中看起来没问题,在类设计中,Ostrich不应该从Bird类继承,这里应该从Bird中分离一个不会飞的类,Ostrich应该继承与它。
Farhana:好,明白了。那么让我来试着指出为什么LSP这么重要:
- 如果没有LSP,类继承就会混乱;如果子类作为一个参数传递给方法,将会出现未知行为;
- 如果没有LSP,适用与基类的单元测试将不能成功用于测试子类;
对吗?
Shubho:非常正确。你能设计对象,使用LSP做为一个检查工作来测试继承是否正确。
接口分离原则
Shubho:今天我们学习”接口分离原则”,这是海报:

接口分离原则海报
Farhana:这是什么意思?
Shubho:它的意思是:”客户端不应该被迫依赖于它们不用的接口。”
Farhana:请解释一下。
Shubho:当然,这是解释:
假设你想买个电视机,你有两个选择。一个有很多开关和按钮,它们看起来很混乱,且好像对你来说没必要。另一个只有几个开关和按钮,它们很友好,且适合你使用。假定两个电视机提供同样的功能,你会选哪一个?
Farhana:当然是只有几个开关和按钮的第二个。
Shubho:对,但为什么?
Farhana:因为我不需要那些看起来混乱又对我没用的开关和按钮。
Shubho:以便外部能够指导这些类有哪些可用的功能,客户端代码也能根据接口来设计.现在,如果接口太大,包含很多暴露的方法,在外界看来会很混乱.接口包含太多的方法也使其可用性降低,像这种包含了无用方法的”胖接口”会增加类之间的耦合.你通过接口暴露类的功能,对.同样地,假设你有一些类,
这也引起了其他问题.如果一个类想实现该接口,那么它需要实现所有的方法,尽管有些对它来说可能完全没用.所以说这么做会在系统中引入不必要的复杂度,降低可维护性或鲁棒性.
接口隔离原则确保实现的接口有他们共同的职责,它们是明确的,易理解的,可复用的.
Farhana:你的意思是接口应该仅包含必要的方法,而不该包含其它的.我明白了.
Shubho:非常正确.一起看个例子.
下面是违反接口隔离原则的一个胖接口

注意到IBird接口包含很多鸟类的行为,包括Fly()行为.现在如果一个Bird类(如Ostrich)实现了这个接口,那么它需要实现不必要的Fly()行为(Ostrich不会飞).
Farhana:确实如此。那么这个接口必须拆分了?
Shubho:是的。这个”胖接口”应该拆分未两个不同的接口,IBird和IFlyingBird,IFlyingBird继承自IBird.

这里如果一种鸟不会飞(如Ostrich),那它实现IBird接口。如果一种鸟会飞(如KingFisher),那么它实现IFlyingBird.
Farhana:所以回头看包含了很多开关和按钮的电视机的例子,电视机制造商应该有一个电视机的图纸,开关和按钮都在这个方案里。不论任何时候,当他们向制造一种新款电视机时,如果他们想复用这个图纸,他们将需要在这个方案里添加更多的开关和按钮。那么他们将没法复用这个方案,对吗?
Shubho:对的。
Farhana:如果他们确实需要复用方案,它们应当把电视机的图纸份为更小部分,以便在任何需要造新款电视机的时候复用这点小部分。
Shubho:你理解了。
依赖倒置原则
Shubho:这是SOLID原则里最后一个原则。这是海报

它的意思是:高层模块不应该依赖底层模块,两者都应该依赖其抽象
Shubho:考虑一个现实中的例子。你的汽车是由很多如引擎,车轮,空调和其它等部件组成,对吗?
Farhana:是的
Shubho:好,它们没有一个是严格的构建在一个单一单元里;换句话说,它们都是可插拔的,因此当引擎或车轮出问题时,你可以修理它(而不需要修理其它部件),甚至可以换一个。
在替换时,你仅需要确保引擎或车轮符合汽车的设计(如汽车能使用任何1500CC的引擎或任何18寸的车轮)。
当然,汽车也可能允许你在1500CC引擎的地方安装一个2000CC的引擎,事实上对某些制造商(如丰田汽车)是一样的。
现在,如果你的汽车的零部件不具备可插拔性会有什么不同?
Farhana:那会很可怕!因为如果汽车的引擎出故障了,你可能修理整部车或者需要买一个新的。
Shubho:是的,那么该如何做到”可插拔性”呢?
Farhana:这里抽象是关键,对吗?
Shubho:是的,在现实中,汽车是高级模块或实体,它依赖于低级模块或实体,如引擎或车轮。
相比直接依赖于引擎或车轮,汽车应依赖于某些抽象的有规格的引擎或车轮,以便于如果任何引擎或车轮符合抽象,那么它们都能组合到汽车中,汽车也能跑动。
一起看下面的类图
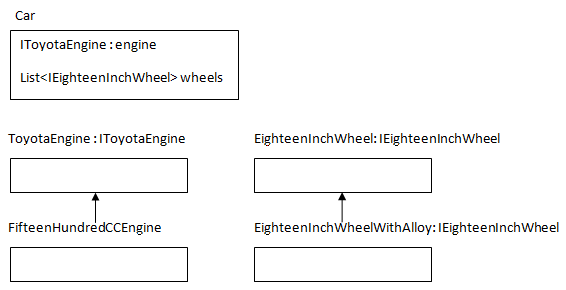
Shubho:注意到上面Car类有两个属性,它们都是抽象类型(接口)。引擎和车轮是可插拔的,因为汽车能接受任何实现了声明接口的对象,并且Car类不需要做任何改动。
Farhana:所以,如果代码中不用依赖倒置,我们将面临如下风险:
- 使用低级类会破环高级代码;
- 当低级类变化时需要很多时间和代价来修改高级代码;
- 产生低复用的代码;
Shubho:你完全掌握了,亲爱的!
总结
Shubho:除SOLID原则外还有很多其它的面向对象原则。如:
“组合替代继承”:这是说相对于继承,要更倾向于使用组合;
“笛米特法则”:这是说”你的类对其它类知道的越少越好”;
“共同封闭原则”:这是说”相关类应该打包在一起”;
“稳定抽象原则”:这是说”类越稳定,越应该由抽象类组成”;
Farhana:我应该学习那些原则吗?
Shubho:当然可以。你可以从整个网上学习。仅仅需要Google一下那些原则,然后尝试理解它。当然如果有需要,尽管问我。
Farhana:在那些设计原则之上我听说过很多设计模式。
Shubho:对的。设计模式只是对一些经常出现的场景的一些通用设计建议。这些灵感主要来自于面向对象原则。你可以把设计模式看作”框架”,把OOD原则看作”规范”.
Farhana:那么接下去我将学习设计模式吗?
Shubho:是的,亲爱的。
Farhana:那会很有意思,对吗?
Shubho:是,那确实令人兴奋。