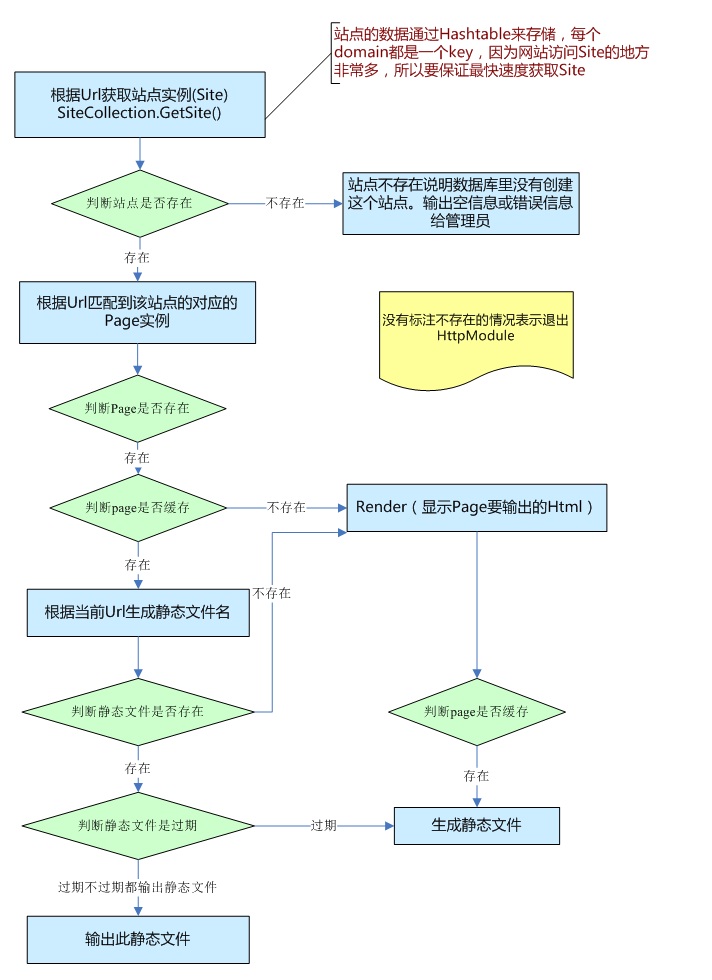
[转载]通过源代码研究ASP.NET MVC中的Controller和View(一) – Ivony… – 博客园.
因为Jumony计划提供ASP.NET MVC的视图模型支持,以取代ASP.NET MVC默认的视图模型(事实上,我觉得很糟糕)。所以,需要先对ASP.NET MVC的视图模型有一个了解。
ASP.NET MVC是一个很年轻的项目,代码并不多,这很好,但麻烦的是文档和资料也不够多,看来要想了解其视图模型只能靠自己。
不 过幸运的是,MVC模型已经决定了其大体的框架,所以我打算直接用Reflector来看看里面的结构(不直接用源代码的原因仅仅是因为 Reflector导航功能实在是太强了,但当我贴代码的时候,贴的是MVC源代码),配合名称和设计思想反析就能够很轻松的了解其架构。
那么这一次研究的对象是.NET Framework 4中的ASP.NET MVC 2。
我先来看一下ASP.NET MVC中的类型,那么我很轻松的发现,这两个类型会是我的切入点:
IView
IController
这两个接口再明白不过的告诉了我它们就是View和Controller的抽象。那么他们俩都只有一个方法,所以职责也很容易就能推导出来:
IView只有一个方法:void Render(ViewContext viewContext, TextWriter writer);
依据视图上下文(ViewContext)呈现HTML。
IController也只有一个方法:void Execute(RequestContext requestContext);
根据请求上下文执行相应的操作。
简单的来说,视图的职责就是呈现(Render),控制器的职责就是执行(Execute),还真简单,哈。
下面我想了解一下视图和控制器是怎么联系到一起的,先来看看MVC的范例网站,我发现Controller里面所有的方法的最后都是这样的:
return View();
而所有的方法的返回值类型都是ActionResult,通过源代码我发现View方法的返回结果是ViewResult,一个ActionResult的子类:
protected internal ViewResult View()
看来先得弄明白这俩东西是干什么的,从名称我不能发现更多的信息,那么先从抽象的ActionResult来研究。
这个类型只有一个方法:
public abstract class ActionResult
{
public abstract void ExecuteResult( ControllerContext context );
}
根据控制器上下文来执行结果,这个方法是抽象的,应该是由具体的类型(如ViewResult)来决定到底要执行什么操作了。
看来这个东西的职责就是执行结果了。
根据上面的观察可以得到推论:
Controller里面的方法都需要返回一个ActionResult(猜测?),这个ActionResult负责下一步的执行操作。不过我有 点奇怪为什么要把操作放在这个ActionResult而不是直接在方法里面执行,那么看看ActionResult有些什么子类型:

我不知道您看出来了什么,不过通过子类我已经找到刚才问题的答案了。
ActionResult执行的操作都是与用户交互相关的,例如JavaScriptResult,又或者是FileResult,当然还有我们的 ViewResult。利用ActionResult可以隔离在Controller里面的的业务逻辑和在ActionResult里面的交互逻辑。这是 一个很经典的设计。呃,顺带说说我为什么讨厌《设计模式》,你经常会发现一些很经典的设计手法,然后,你没办法从那个天杀的《设计模式》中找到一个很NB 的名词来描述(我一会儿思考下这是不是那啥模式),所以。。。。
为了证实我的观点,来看看ActionResult.Execute方法的那个参数ControllerContext里面有什么。是的,里面有一 大堆与用户界面相关的东西,例如HttpContext、RequestContext(尽管我现在还不太清楚这个干什么用的,但单从名称看就知道与业务 没关系)、RouteData等。
那么我们可以得到ActionResult的定义,这是一个用户界面交互动作的抽象,用户界面交互包括,呈现一个视图(ViewResult)、或 是执行一段脚本(JavaScriptResult)、或是下载一个文件(FileResult)。如果我们将用户交互全部定义为MVC中的View部分 的话,那么ActionResult就是Controller通向View的入口。也就是MVC结构图中Controller指向View的那个箭头。
或者说,ActionResult的职责就是,改变和呈现View(广义的View,泛指用户界面,非IView实例)。
或者说我现在可以得到结论,ViewResult的职责就是呈现一个HTML视图(因为还有FileResult、JavaScriptResult,所以ViewResult多半只负责呈现一个动态的HTML视图)?
所以ActionResult之前的事情在这一次研究中我就不太关心了,因为ActionResult是视图的控制入口,我现在只关心视图模型。
来看看ViewResult(ViewResultBase)对于ExecuteResult的实现:
public override void ExecuteResult( ControllerContext context )
{
if ( context == null )
{
throw new ArgumentNullException( "context" );
}
if ( String.IsNullOrEmpty( ViewName ) )
{
ViewName = context.RouteData.GetRequiredString( "action" );
}
ViewEngineResult result = null;
if ( View == null )
{
result = FindView( context );
View = result.View;
}
TextWriter writer = context.HttpContext.Response.Output;
ViewContext viewContext = new ViewContext( context, View, ViewData, TempData, writer );
View.Render( viewContext, writer );
if ( result != null )
{
result.ViewEngine.ReleaseView( context, View );
}
}
这是ViewResultBase的源代码,前面两个if是例行的入口检查,从第三个if开始干活。首先判断自己的View属性(IView类型) 是不是为空,为空的话执行FindView方法,得到一个result(类型是ViewEngineResult),再把result.View赋给自己 的View属性。我将这些步骤称为查找视图。
然后创建一个writer和一个ViewContext,调用View的Render方法来呈现视图。最后如果result不为空,则调用ViewEngine的ReleaseView方法。简单的说就是:
- 查找视图(this.View : IView)
- 呈现视图(IView.Render)
- 释放试图(IViewEngine.ReleaseView)
查找视图的主要方法是 FindView,这是ViewResultBase唯一的一个抽象方法,由子类ViewResult来实现。那么ViewResultBase和 ViewResult的分工也很明确了。ViewResult封装了查找视图的逻辑(因为只有这么一个抽象方法),呈现视图和其他工作则是由 ViewResultBase来完成。
看看ViewResult.FindView的实现:
protected override ViewEngineResult FindView( ControllerContext context )
{
ViewEngineResult result = ViewEngineCollection.FindView( context, ViewName, MasterName );
if ( result.View != null )
{
return result;
}
// we need to generate an exception containing all the locations we searched
StringBuilder locationsText = new StringBuilder();
foreach ( string location in result.SearchedLocations )
{
locationsText.AppendLine();
locationsText.Append( location );
}
throw new InvalidOperationException( String.Format( CultureInfo.CurrentUICulture,
MvcResources.Common_ViewNotFound, ViewName, locationsText ) );
}
首先调用了ViewResultBase.ViewEngineCollection.FindView方法。先不管这个方法的实现,我们看到这个方法的返回值result在后面被原封不动的return了。所以,我们得出结论,ViewResult的FindView方法干了什么事:
- 调用ViewResultBase.ViewEngineCollection.FindView方法
- 如果刚才的结果里面存在一个View(result.View != null),那么返回这个结果。
- 否则抛个InvalidOperationException的异常。
那么这里没有查找视图的逻辑,我需要进一步研究ViewResultBase.ViewEngineCollection.FindView方法。 先看看ViewResultBase.ViewEngineCollection这个属性,其值默认就是ViewEngines.Engines:
public ViewEngineCollection ViewEngineCollection
{
get
{
return _viewEngineCollection ?? ViewEngines.Engines;
}
set
{
_viewEngineCollection = value;
}
}
换言之ViewResultBase.ViewEngineCollection.FindView等于ViewEngines.Engines.FindView,多按几下F12找到这个方法的实现:
public virtual ViewEngineResult FindView( ControllerContext controllerContext, string viewName, string masterName )
{
if ( controllerContext == null )
{
throw new ArgumentNullException( "controllerContext" );
}
if ( string.IsNullOrEmpty( viewName ) )
{
throw new ArgumentException( MvcResources.Common_NullOrEmpty, "viewName" );
}
Func<IViewEngine, ViewEngineResult> cacheLocator = e => e.FindView( controllerContext, viewName, masterName, true );
Func<IViewEngine, ViewEngineResult> locator = e => e.FindView( controllerContext, viewName, masterName, false );
return Find( cacheLocator, locator );
}
private ViewEngineResult Find( Func<IViewEngine, ViewEngineResult> cacheLocator, Func<IViewEngine, ViewEngineResult> locator )
{
ViewEngineResult result;
foreach ( IViewEngine engine in Items )
{
if ( engine != null )
{
result = cacheLocator( engine );
if ( result.View != null )
{
return result;
}
}
}
List<string> searched = new List<string>();
foreach ( IViewEngine engine in Items )
{
if ( engine != null )
{
result = locator( engine );
if ( result.View != null )
{
return result;
}
searched.AddRange( result.SearchedLocations );
}
}
return new ViewEngineResult( searched );
}
这里的cacheLocator和locator是两个匿名方法,其实就是封装了IViewEngine.FindView的调用,利用闭包把controllerContext、viewName和masterName包了进去。
这个手法很好玩,但实际上如果把Find方法代入展开就是这样:
public virtual ViewEngineResult FindView( ControllerContext controllerContext, string viewName, string masterName )
{
if ( controllerContext == null )
{
throw new ArgumentNullException( "controllerContext" );
}
if ( string.IsNullOrEmpty( viewName ) )
{
throw new ArgumentException( MvcResources.Common_NullOrEmpty, "viewName" );
}
ViewEngineResult result;
foreach ( IViewEngine engine in Items )
{
if ( engine != null )
{
result = engine.FindView( controllerContext, viewName, masterName, true );//Func<IViewEngine, ViewEngineResult> cacheLocator = e => e.FindView( controllerContext, viewName, masterName, true );
if ( result.View != null )
{
return result;
}
}
}
List<string> searched = new List<string>();
foreach ( IViewEngine engine in Items )
{
if ( engine != null )
{
result = engine.FindView( controllerContext, viewName, masterName, false );//Func<IViewEngine, ViewEngineResult> locator = e => e.FindView( controllerContext, viewName, masterName, false );
if ( result.View != null )
{
return result;
}
searched.AddRange( result.SearchedLocations );
}
}
return new ViewEngineResult( searched );
}
方法虽然复杂点,但逻辑很简单,首先遍历Items里面所有的IViewEngine,调用FindView方法(最后一个参数为true),如果有任何一个IViewEngine返回的结果的View不是null,就返回。
如果遍历了一次没有找到任何View,那么就进行二次遍历(最后一个参数为false),同样的,一旦发现有一个IViewEngine返回的结果存在有View,就返回。两次遍历都没结果的话,就返回一个new ViewEngineResult( searched )。searched是已经查找过的位置(根据result.SearchedLocations这个名字直接就知道了)。
最后查查MSDN可知,ViewEngines.Engines是所有可用的视图引擎(IViewEngine的实例)的集合,这个Items是其基类Collection<IViewEngine>的属性,简单的说就是一个容器,存放所有视图引擎。
结合之前的结论可以得到ViewResult的ExecuteResult全部执行过程:
- 查找视图(IView)
- 调用ViewResultBase.ViewEngineCollection.FindView
- 调用ViewEngines.Engines.FindView
- 遍历所有的视图引擎(IViewEngine实例),调用FindView方法(最后一个参数为true)
- 若找到任何一个视图引擎返回的结果中View不为null,则返回。
- 第二次遍历,最后一个参数用false来调用FindView
- 若找到View则返回
- 否则返回一个没有View的ViewEngineResult,在ViewResult.FindView中将会抛出异常。
- 调用ViewEngines.Engines.FindView
- 调用ViewResultBase.ViewEngineCollection.FindView
- 呈现视图(IView.Render)
- 释放试图(IViewEngine.ReleaseView)
最后来看看IViewEngine接口长啥样:
public interface IViewEngine
{
ViewEngineResult FindPartialView( ControllerContext controllerContext, string partialViewName, bool useCache );
ViewEngineResult FindView( ControllerContext controllerContext, string viewName, string masterName, bool useCache );
void ReleaseView( ControllerContext controllerContext, IView view );
}
我们发现这个IViewEngine的实例主要就干两件事情:FindView和ReleaseView。
综合上面的结论,我们可以搞清楚ViewResult、IView和IViewEngine的分工和职责了:
ViewResult:提供ActionResult的实现,查找视图(FindView)并且呈现它(IView.Render),最后释放 (IViewEngine.Release)。很明显,ViewResult是视图(IView)的使用者。几乎也是唯一的使用者:

IViewEngine:提供查找视图(FindView)和释放视图(ReleaseView)的功能,从FindView的最后一个参数(useCache)来看,它还可以缓存视图实例以便下次使用。所以,他是视图(IView)的管理者。
IView:负责呈现HTML视图。
好了,今天的研究就到此为止了,要煮饭给老婆吃了。