PDC 不愧为微软最高级的技术人员专业会议,看得我直呼过瘾。前几天在PDC 2010会议上Anders Hejlsberg发表了一场名为“The Future of
C# and Visual Basic”的演说,谈论了未来C#和VB中最为重要的两个特性:“异步(Async)”及“编译器即服务(Compiler as a Service)”。我现在对这场演讲进行总结,但不会像上次《
编程语言的发展趋势及未来方向》那样逐句翻译,而是以Anders的角度使用一种简捷合适的方式表述其完整内容。
 在 2000年的PDC上,我们给大家带来了一个全新的平台“.NET”,以及一个语言“C#”。.NET与C#每次发布时都有一个“主题”,一开始是“托管 代码”,接着是“泛型”,然后是“LINQ”,直到最近的“动态性”,这就是C#和VB的演变过程。这两种语言面向的用户比较相近,微软也承诺会同时发展 两种语言。因此这个演讲虽然以C#作为主题,但其实也会在VB中得以体现。
在 2000年的PDC上,我们给大家带来了一个全新的平台“.NET”,以及一个语言“C#”。.NET与C#每次发布时都有一个“主题”,一开始是“托管 代码”,接着是“泛型”,然后是“LINQ”,直到最近的“动态性”,这就是C#和VB的演变过程。这两种语言面向的用户比较相近,微软也承诺会同时发展 两种语言。因此这个演讲虽然以C#作为主题,但其实也会在VB中得以体现。
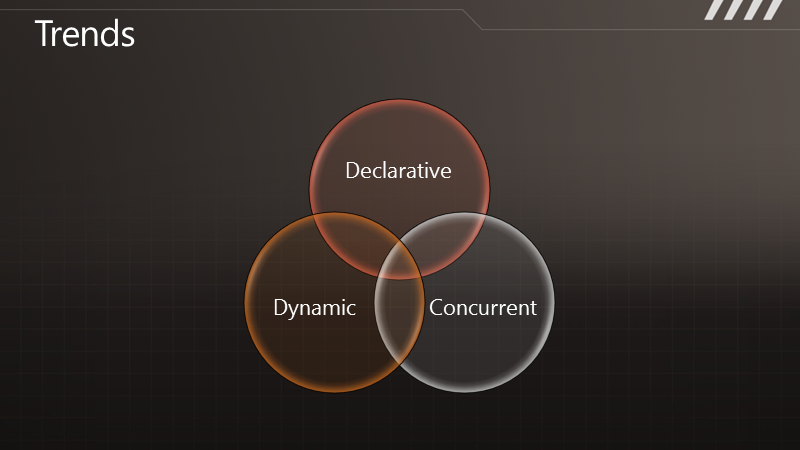
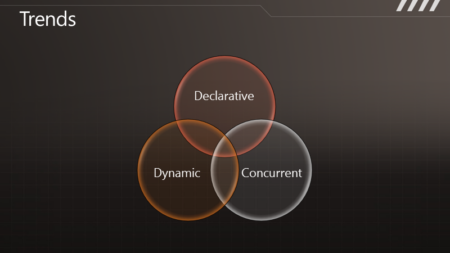 作 为语言的设计者,要设法将工业界所重视的内容,使用语言表现出来,因此也有了这样的分类。“声明式”代表了一种编程的趋势,尽可能表现出“做什么”而不是 “怎么做”,于是有了函数式编程与DSL等等。然后,目前研究的热门之一则是动态语言,如Python,Ruby,JavaScript等等,以及它们是 如何影响静态语言的。还有便是“并发”,这里所指的广义的“并发”,包括单机上多核以及云或是数据中心上分布式系统等等,也就是各种“同时处理”的方式。
作 为语言的设计者,要设法将工业界所重视的内容,使用语言表现出来,因此也有了这样的分类。“声明式”代表了一种编程的趋势,尽可能表现出“做什么”而不是 “怎么做”,于是有了函数式编程与DSL等等。然后,目前研究的热门之一则是动态语言,如Python,Ruby,JavaScript等等,以及它们是 如何影响静态语言的。还有便是“并发”,这里所指的广义的“并发”,包括单机上多核以及云或是数据中心上分布式系统等等,也就是各种“同时处理”的方式。
我 们可以清楚地看到,C# 3.0和VB 9中的函数式编程,LINQ等特性体现了“声明式”,而C# 4.0和VB 10则出现了动态性,但都没有太多关于“并发”的成分在里面──它都体现在框架中了,例如.NET 4包含了任务并行库(Task Parallel Library),但对于语言来说,除了lock似乎就没有什么这方面的支持了。
 如 今对“并发”的需求已经是毋庸质疑的,很少有一个应用程序或是服务不需要连接外部系统。这种与外部系统,例如互联网进行交互的行为则增加了应用程序的延 迟,这可能导致UI在和外部服务交互时长时间失去响应。而对于一个数据中心的服务,您可能就会发现CPU的利用率不高,因为系统都在等待其他服务的回复 了。
如 今对“并发”的需求已经是毋庸质疑的,很少有一个应用程序或是服务不需要连接外部系统。这种与外部系统,例如互联网进行交互的行为则增加了应用程序的延 迟,这可能导致UI在和外部服务交互时长时间失去响应。而对于一个数据中心的服务,您可能就会发现CPU的利用率不高,因为系统都在等待其他服务的回复 了。
为了解决这个问题,我们往往会使用“异步”的编程方式,它逐渐已经成为“高响应度”,“高伸缩性”的代名词了。此外还有一些API只 提供了异步的版本,例如在JavaScript中发起HTTP请求,或是Silverlight的网络交互方面。这种情况以后只会越来越普遍。
 于是下一版本的C#和VB就会在这里有所行动,目前会展示一下我们的早期工作,希望可以得到一些反馈。
于是下一版本的C#和VB就会在这里有所行动,目前会展示一下我们的早期工作,希望可以得到一些反馈。
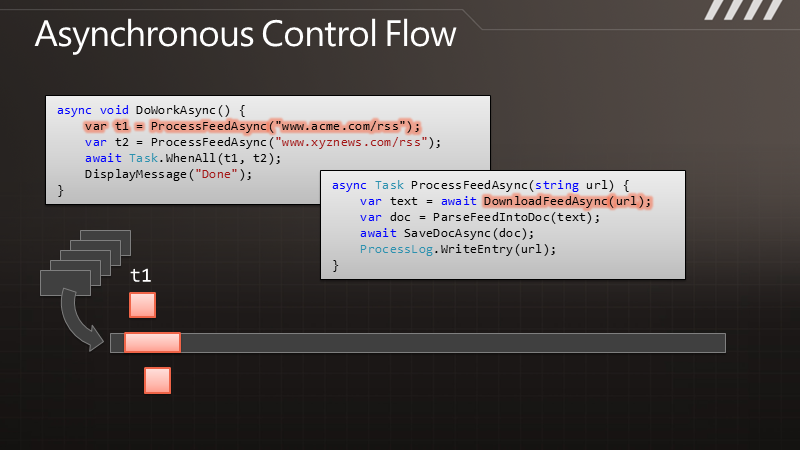
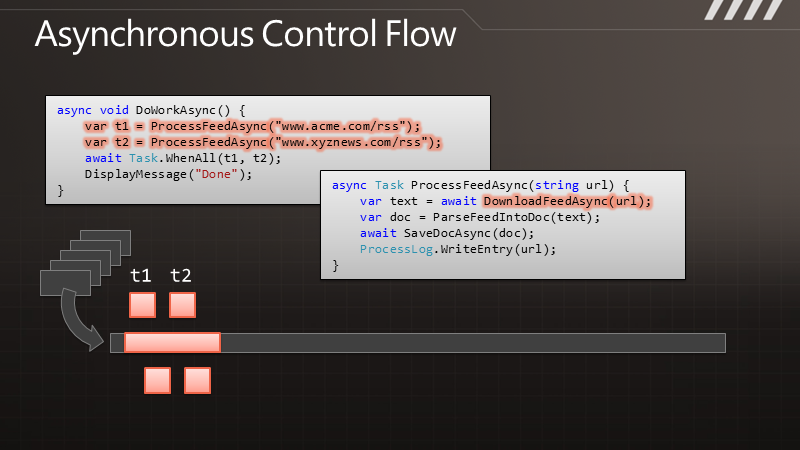
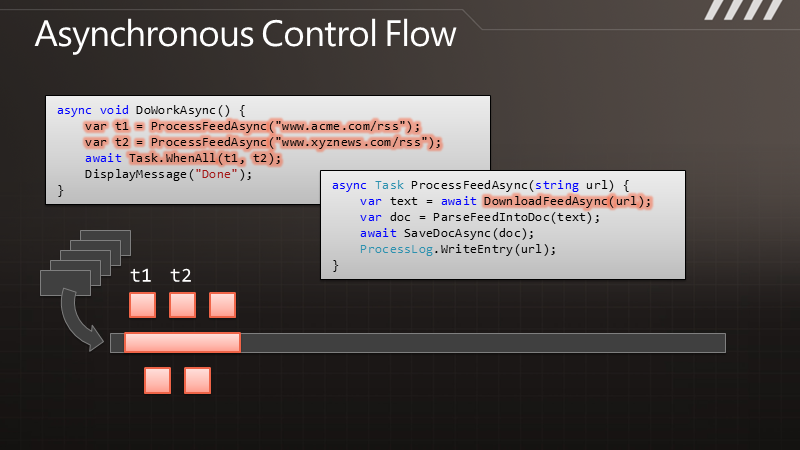
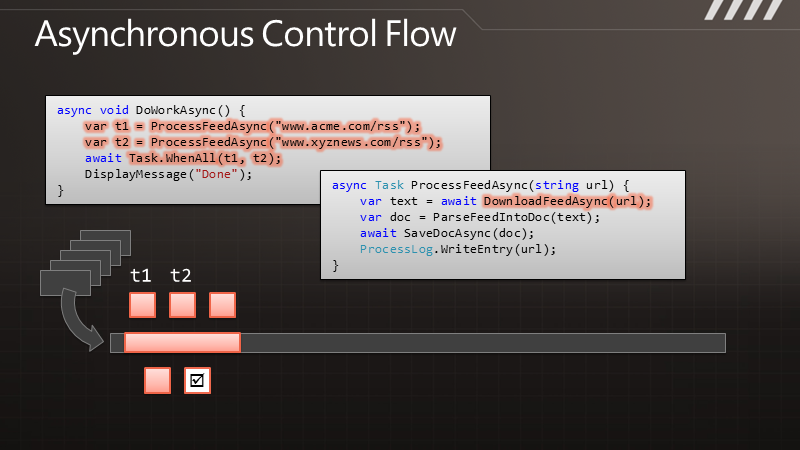
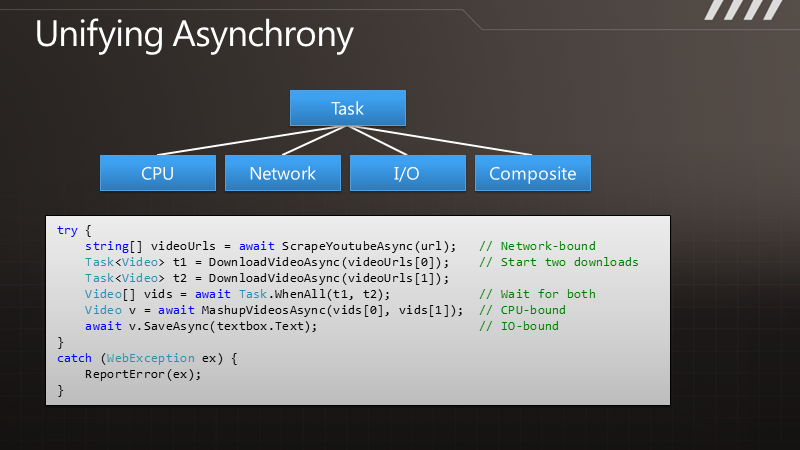
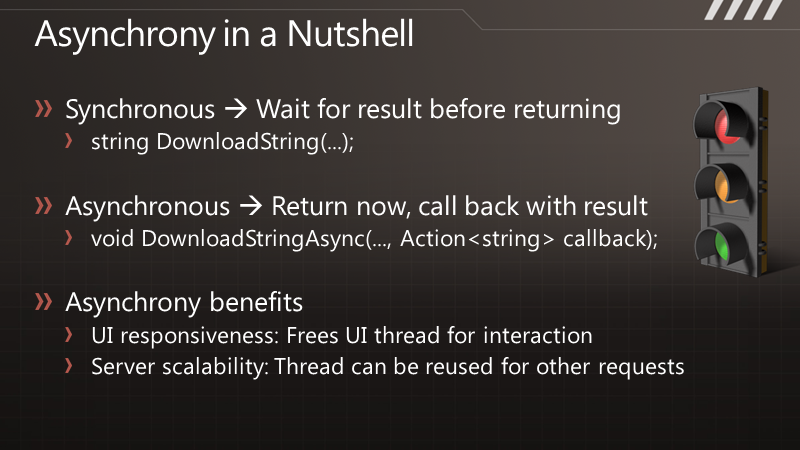
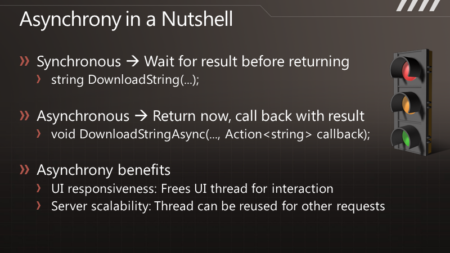 说 到异步化,您可以简单认为“一起运行”。一个同步方法,好比DownloadString,应用程序会执行这个方法,并等待结果返回,但是你不能把工作的 执行过程与结果的送达区分开来。而对于异步编程来说,DownloadStringAsync在调用之后便会立即返回,过了一段时间,结果就会传递过来, 于是执行过程和结果的送达便完全是可分离的了。而对于如今典型的异步模型来说,结果通过一个回调函数传递过来。
说 到异步化,您可以简单认为“一起运行”。一个同步方法,好比DownloadString,应用程序会执行这个方法,并等待结果返回,但是你不能把工作的 执行过程与结果的送达区分开来。而对于异步编程来说,DownloadStringAsync在调用之后便会立即返回,过了一段时间,结果就会传递过来, 于是执行过程和结果的送达便完全是可分离的了。而对于如今典型的异步模型来说,结果通过一个回调函数传递过来。
异步化可以的得到高度的响应能力,因为在等待任务的结果时我们可以做其他一些事情。而对于服务器来说,异步可以带来很好的伸缩性,因为线程得到释放了,而不需要等待请求返回结果。
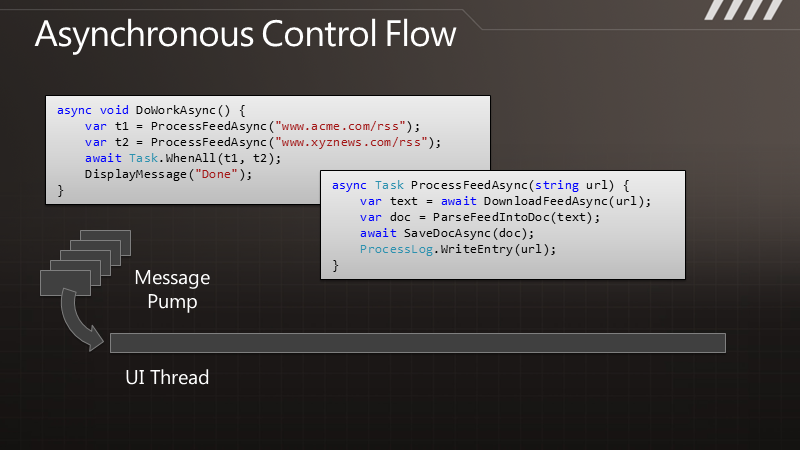
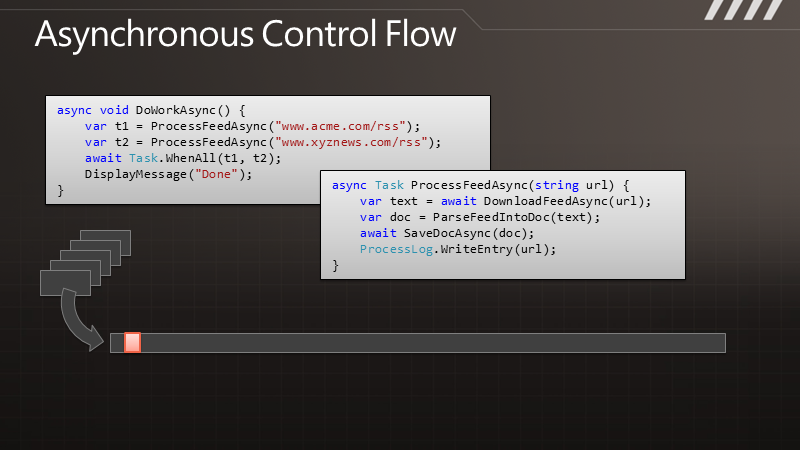
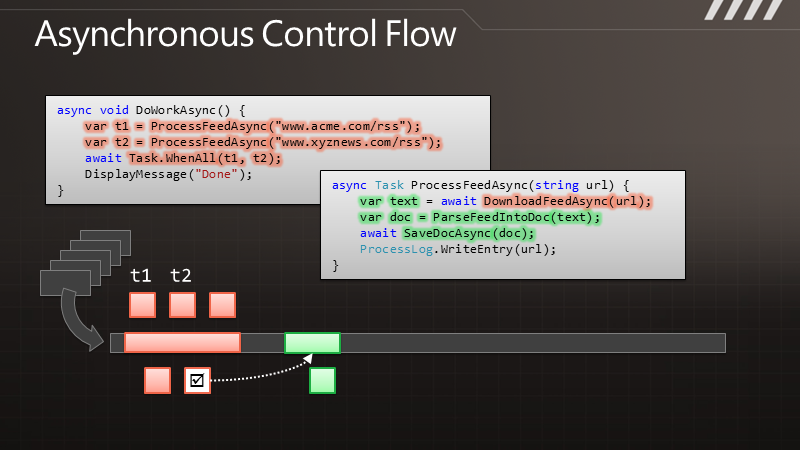
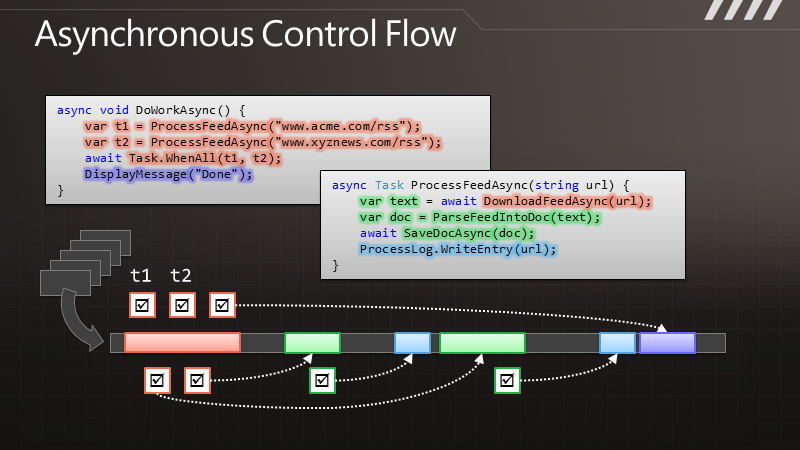
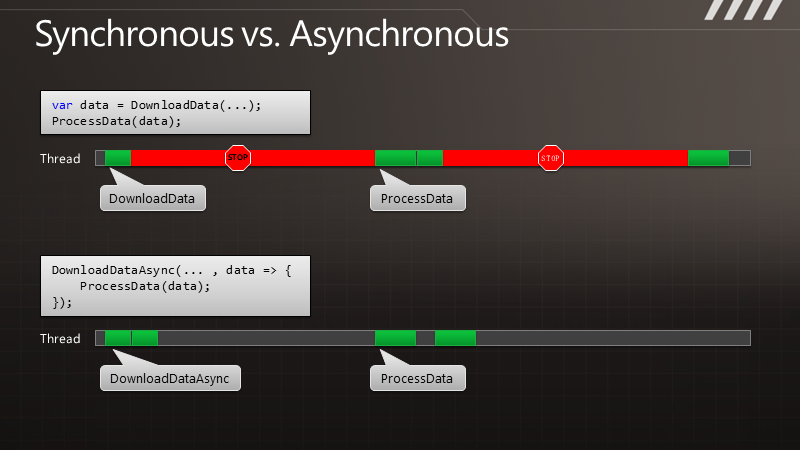
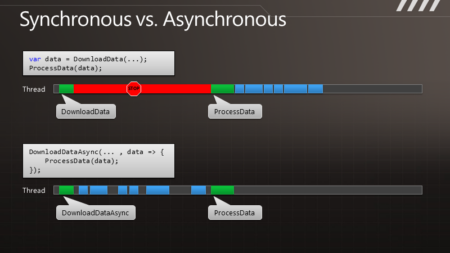 通 过图示可以更清楚地了解这点。例如有段代码叫做DownloadData,调用以后可以得到一些数据。在执行时,线程会有长时间的终止,它被阻塞了,要等 到结果返回之后才能继续处理数据。与此相对的是其异步的版本,我们调用DownloadDataAsync方法之后,它立即将控制权交还给我们,过了一段 时间,它会把结果传递给回调函数,让我们继续处理下去。但是在DownloadData和ProcessData之间,我们可以处理其他一些工作。如果这 是UI线程,那么就可以用于响应其他用户操作。如果这是个服务器线程,那么在等待结果时这个线程可以用来处理其他请求。
通 过图示可以更清楚地了解这点。例如有段代码叫做DownloadData,调用以后可以得到一些数据。在执行时,线程会有长时间的终止,它被阻塞了,要等 到结果返回之后才能继续处理数据。与此相对的是其异步的版本,我们调用DownloadDataAsync方法之后,它立即将控制权交还给我们,过了一段 时间,它会把结果传递给回调函数,让我们继续处理下去。但是在DownloadData和ProcessData之间,我们可以处理其他一些工作。如果这 是UI线程,那么就可以用于响应其他用户操作。如果这是个服务器线程,那么在等待结果时这个线程可以用来处理其他请求。
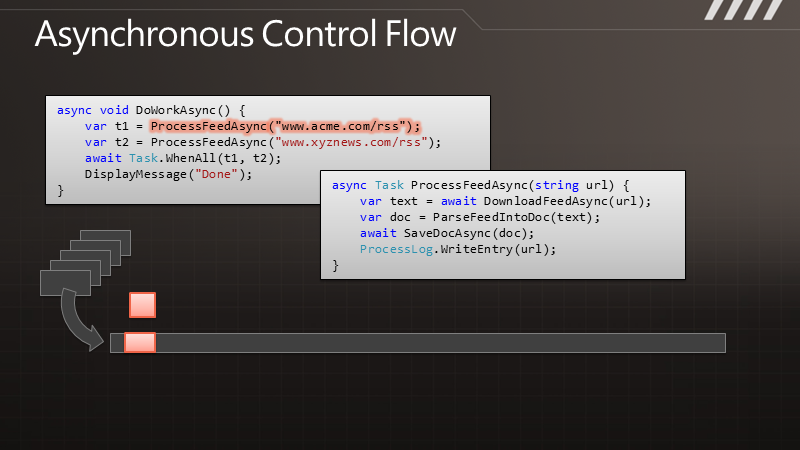
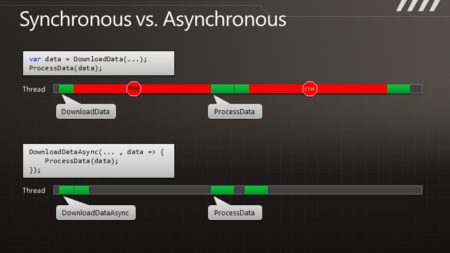 那么,如果我们要执行多个请求,例如要调用两遍,对于同步的版本就会获得双倍的阻塞,即便两个请求是完全独立的。而在异步的情况下,我们可以快速地发出两个请求,这样便形成的并发,即便这里并没有使用额外的线程。于是便可以更快地得到结果,也能保证响应能力。
那么,如果我们要执行多个请求,例如要调用两遍,对于同步的版本就会获得双倍的阻塞,即便两个请求是完全独立的。而在异步的情况下,我们可以快速地发出两个请求,这样便形成的并发,即便这里并没有使用额外的线程。于是便可以更快地得到结果,也能保证响应能力。
有 人可能会说,我们可以利用后台线程来得到响应。没错,不过就引入了多线程模型,于是就要处理同步等线程安全问题。而且,在开发带有UI的应用程序时,我们 不能在后台线程里操作UI,这样又出现了其他的复杂情况。而在服务器应用中,我们又不希望创建更多的线程,因为这会给线程池带来压力,线程之间会有竞争, 就会降低请求的处理能力。
以上便是对异步编程的概述,您可能会问,既然异步有那么多好处,那么为什么不把所有的应用程序都写作异步的呢?那么现在我们就来看一下异步编程大概是什么样子的。
 这里有个简单的应用程序,输入年份,可以下载到那一年的电影。现在这个程序是同步的写法。在搜索的时候UI会失去响应,这样的结果显然无法令人接受,我们要做的更好。我们可以将其改写为异步的形式。
这里有个简单的应用程序,输入年份,可以下载到那一年的电影。现在这个程序是同步的写法。在搜索的时候UI会失去响应,这样的结果显然无法令人接受,我们要做的更好。我们可以将其改写为异步的形式。
同步的写法是这样的:
private void searchButton_Click(object sender, RoutedEventArgs e)
{
LoadMovies(Int32.Parse(textBox.Text));
}
void LoadMovies(int year)
{
resultsPanel.Children.Clear();
statusText.Text = "";
var pageSize = 10;
var imageCount = 0;
while (true)
{
var movies = QueryMovies(year, imageCount, pageSize);
if (movies.Length == 0) break;
DisplayMovies(movies);
imageCount += movies.Length;
}
statusText.Text = String.Format("{0} Titles", imageCount);
}
Movie[] QueryMovies(int year, int first, int count)
{
var client = new WebClient();
var url = String.Format(query, year, first, count);
var data = client.DownloadString(new Uri(url));
var movies =
from entry in XDocument.Parse(data).Desendanies(xs + "entry")
let properties = entry.Element(xm + "properties")
select new Movie
{
/* ... */
};
return movies.ToArray();
}
在点击按钮以后会调用LoadMovies方法,它会在一个循环中不断使用QueryMovies方法进行查询,在QueryMovies方法中我们使用WebClient下载一个XML,解析,构造Movie对象并返回,最终呈现在界面上。
下 载时我们使用DownloadString方法,这是个同步方法,我们要把它修改成异步的方式。事实上还真有个异步的方法,叫做 DownloadStringAsync,不过这就需要我们修改代码,例如要把QueryMovies中的大部分放入 DownloadStringCompleted事件的处理函数中。同时,异步编程的痛苦慢慢体现出现了,我们无法返回数据,而必须传递到某个地方,于是 QueryMovies方法则要返回void,并接受一个回调函数。
void QueryMovies(int year, int first, int count, Action<Movie[]> action)
{
var client = new WebClient();
var url = String.Format(query, year, first, count);
client.DownloadStringCompleted += (sender, e) =>
{
var data = e.Result;
var movies =
from entry in XDocument.Parse(data).Descendants(xs + "entry")
let properties = entry.Element(xm + "properties")
select new Movie
{
/* ... */
};
action(movies.ToArray());
};
client.DownloadStringAsync(new Uri(url));
}
然后我们还需要处理QueryMovies的调用者,这里实在麻烦到家了,因为我们使用了一个while循环来查询电影,那么我们又该如何反复调用一个异步方法?
void LoadMovies(int year)
{
resultsPanel.Children.Clear();
statusText.Text = "";
var pageSize = 10;
var imageCount = 0;
Action<Movie[]> action = null;
action = movies =>
{
if (movie.Length > 0)
{
DisplayMovie(movies);
imageCount += movies.Length;
QueryMovies(year, imageCount, pageSize, action);
}
else
{
statusText.Text = String.Format("{0} Titles", imageCount);
}
};
QueryMovies(year, imageCount, pageSize, action);
}
你一定已经发现了,现在的代码已经很难让人保持愉快了。不过它的确是异步的了,运行时界面响应良好。效果是有了,不过这代码变得乱七 八糟。想象一下,如果要加上异常处理该怎么做?我们可能要提供两个回调函数,一个处理正常情况,一个处理错误,还到处需要有try…catch,很快 麻烦就会接踵而来了。如果不想面对这些麻烦,你可能就要去启用后台线程,这样又有了线程方面的问题。
显然我们可以做的更好。首先让我们回到原来的同步代码,然后再用上我们为异步编程设计的新特性。
如 果要把QueryMovies变为异步,则先把它的返回值改为Task<Movie[]>,你如果了解.NET 4则一定已经知道这个类型是任务并行库的一部分。事实上Task类型只是表示一个“开始计算并在未来返回结果”的任务,因此Task<T>表 示一个会在将来返回T类型的计算任务,在科学计算领域这通常被称为Future或是Promise。现在方法的返回值是 Task<Movie[]>,而最后返回的是Movie[],这显然不匹配,但我们可以将其标记为一个async方法。对于async方法, 编译器会重写整个方法实现来表示一个异步任务,以后我们会来观察它是如何实现这点的。
async Task<Movie[]> QueryMoviesAsync(int year, int first, int count)
{
var client = new WebClient();
var url = String.Format(query, year, first, count);
var data = client.DownloadString(new Uri(url));
var movies =
from entry in XDocument.Parse(data).Descendants(xs + "entry")
let properties = entry.Element(xm + "properties")
select new Movie
{
/* ... */
};
return movies.ToArray();
}
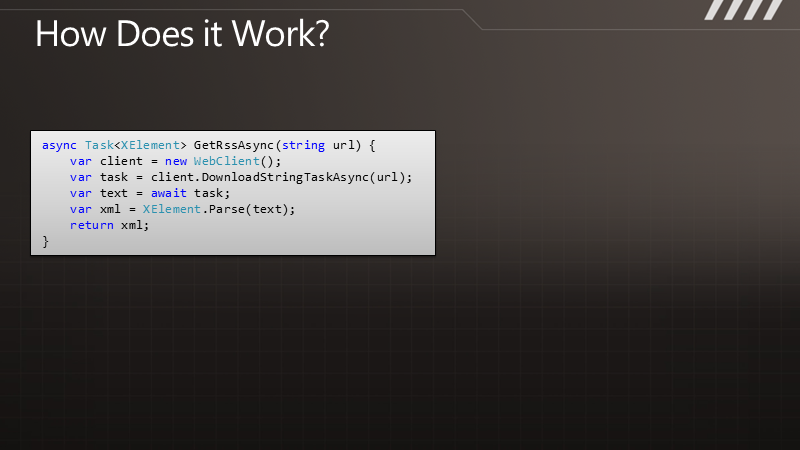
不过只做到这点还不够,我们的方法还没有异步化,这还是个同步任务。不过,如今在一个async方法中,我们有能力组合调用另一个 async方法,并异步地等待。这里使用了一个扩展方法DownloadStringTaskAsync,以后也会包含在框架中。这个方法返回 Task<string>类型,表示未来某一时刻将会得到一个string对象。于是在async方法中,我们使用一个新的await操作符 来等待其返回。
async Task<Movie[]> QueryMoviesAsync(int year, int first, int count)
{
var client = new WebClient();
var url = String.Format(query, year, first, count);
var data = await client.DownloadStringTaskAsync(new Uri(url));
var movies =
from entry in XDocument.Parse(data).Descendants(xs + "entry")
let properties = entry.Element(xm + "properties")
select new Movie
{
/* ... */
};
return movies.ToArray();
}
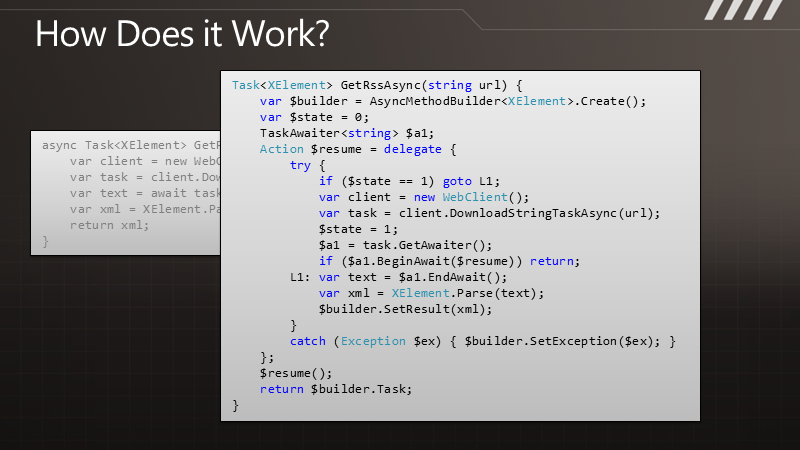
在执行时,方法会执行到await操作符这里,并确保接下来的代码是在一个回调函数/continuation中执行的。编译器会在这里重写这个方法,就像为yield重写迭代器那样,于是我们就不需要做其他事情了,任务结束后自然会执行await后面的代码。
这里的美妙之处在于可以任意组合,对于LoadMovies方法来说,我们也可以将其转化为async方法,并await之前的QueryMoviesAsync方法返回。
async void LoadMoviesAsync(int year)
{
resultsPanel.Children.Clear();
statusText.Text = "";
var pageSize = 10;
var imageCount = 0;
while (true)
{
var movies = await QueryMoviesAsync(year, imageCount, pageSize);
if (movies.Length == 0) break;
DisplayMovies(movies);
imageCount += movies.Length;
}
statusText.Text = String.Format("{0} Titles", imageCount);
}
于是异步实现就这么完成了,代码和之前几乎完全一致。您可以看出,这使得我们在执行异步代码时保留原本的逻辑实现。
那么再为应用程序添加一点功能吧。首先是异常处理:
async void LoadMoviesAsync(int year)
{
resultsPanel.Children.Clear();
statusText.Text = "";
var pageSize = 10;
var imageCount = 0;
try
{
while (true)
{
var movies = await QueryMoviesAsync(year, imageCount, pageSize);
if (movies.Length == 0) break;
DisplayMovies(movies);
imageCount += movies.Length;
}
statusText.Text = String.Format("{0} Titles", imageCount);
}
catch (XmlException)
{
statusText.Text = "Data Error";
}
}
我们无需分离代码或是逻辑,这一切都和同步代码完全一致。再来看看“取消(cancellation)”,对于async方法来说, 我们可以传递一个CancellationToken,表示任务需要监听这个对象的改变。如QueryMoviesAsync便可以增加一个参数:
async Task<Movie[]> QueryMoviesAsync(int year, int first, int count, CancellationToken ct)
{
var client = new WebClient();
var url = String.Format(query, year, first, count);
var data = await client.DownloadStringTaskAsync(new Uri(url), ct);
var movies =
from entry in XDocument.Parse(data).Descendants(xs + "entry")
let properties = entry.Element(xm + "properties")
select new Movie
{
/* ... */
};
return movies.ToArray();
}
这样便得到了一个可取消的async方法。对于逻辑流来说,取消操作就相当于一个异常,代码里需要处理一个TaskCanceledException:
CancellationTokenSource cts;
async void LoadMoviesAsync(int year)
{
resultsPanel.Children.Clear();
statusText.Text = "";
var pageSize = 10;
var imageCount = 0;
cts = new CancellationTokenSource();
try
{
while (true)
{
var movies = await QueryMoviesAsync(year, imageCount, pageSize, cts.Token);
if (movies.Length == 0) break;
DisplayMovies(movies);
imageCount += movies.Length;
}
statusText.Text = String.Format("{0} Titles", imageCount);
}
catch (TaskCanceledException) { }
cts = null;
}
private void cancelButton_Click(object sender, RoutedEventArgs e)
{
if (cts != null)
{
cts.Cancel();
statusText.Text = "Canceled";
}
}
那么超时又怎么说?超时其实就类似一段时间之后的取消。于是我们可以另写一个小方法来处理这个问题:
async void StartTimeoutAsync()
{
await TaskEx.Delay(5000);
if (cts != null)
{
cts.Cancel();
statusText.Text = "Timeout";
}
}
private void searchButton_Click(object sender, RoutedEventArgs e)
{
LoadMoviesAsync(Int32.Parse(textBox.Text));
StartTimeoutAsync();
}
第一步,我们先等待5秒钟,如果任务还在执行,那么我们就取消掉。所以无论是超时,取消还是错误处理,程序的逻辑结构都得以最大限度 的保留,就好比编写普通的代码一样。例如上面的Delay,看上去是顺序逻辑流,但实际上是异步的。为了表现出这点,我们可以为程序新加上一个有趣的功 能:
async void ShowDateTimeAsync()
{
while (true)
{
Title = "Movie Finder " + DateTime.Now;
await TaskEx.Delay(1000);
}
}
public MainWindow()
{
InitializeComponent();
textBox.Focus();
ShowDateTimeAsync();
}
于是在标题栏上便会每隔一秒刷新显示当前时间,与此同时搜索也好,超时也罢,在程序执行时UI都可以获得响应。
值得强 调的是,上面实现的这些功能都没有启用额外的线程,所有这些都在UI线程上执行。那么什么时候需要额外的线程呢?这便是计算密集型操作。例如这里我要执行 五千万次平方根计算,这需要耗费一段时间。不过这样的操作,对于UI线程来说,这也不过是一个异步操作,不是吗?启动操作,然后等待其完成,在它完成之后 再对结果做些处理:
async void ComputeStuffAsync()
{
double result = 0;
await TaskEx.Run(() =>
{
for (int i = 1; i < 500000000; i++)
{
result += Math.Sqrt(i);
}
});
MessageBox.Show("The result is " + result, "Background Task",
MessageBoxButton.OK, MessageBoxImage.Information);
}
private void searchButton_Click(object sender, RoutedEventArgs e)
{
LoadMoviesAsync(Int32.Parse(textBox.Text));
StartTimeoutAsync();
ComputeStuffAsync();
}
TaskEx.Run方法会构造一个后台线程,并返回异步操作,我们使用await等待其返回,这体现了绝佳的组合能力。启动后在任务管理器中便会发现CPU占用率明显上升。
 我在这里宣布,之前演示的技术预览版已经可以下载了。我们已经创建了C#和VB编译器的原型,并提供了一些示例。您可以在开发者中心下载,我在演讲最后会给出URL。
我在这里宣布,之前演示的技术预览版已经可以下载了。我们已经创建了C#和VB编译器的原型,并提供了一些示例。您可以在开发者中心下载,我在演讲最后会给出URL。