
[转载]ASP.NET应用下基于SessionState的“状态编程框架”解决方案 – Artech – 博客园.
在一个基于ASP.NET的Web应用程序中,我们通常使用SessionState保存基于某个客户端的状态信息。但是这种单纯使用SessionState的编程方式具有很多局限,比如Session Item的Key值冲突,比如没有一个有效的SessionState清除机制会为Web Server带来内存压力。 为了实现对客户端状态的有效管理,并提高应用开发效率,在很多年前我们的开发框架体系中就具有相应的一个叫做State的编程框架。最近我开始对其进行升 级和重新设计,将实现原理和概要设计方面的东西写出来与大家共享,希望对各位有些启发。同时希望借此得到你们一些好的建议和意见,以便能够充实我们的框 架。于此同时,我写了一个简单的模拟程序实现了该设计思想,有兴趣的话可以通过这里下载该模拟程序。
一、单纯基于SessionState编程的局限性
SessionState对于ASP.NET的开发者在熟悉不过了,我们可以通过它来存储一些基于客户端的状态信息。从编程角度来说,SesssionState是依附和当前HttpContext的一个用于类似于字典的数据容器,我们通过键值对的方式进行Session Item的设置和获取。但是这种单纯地基于字典索引的编程方式,具有诸多局限:
- 首先,这种弱类型的编程方式不便于快速开发需求。放入SessionState的值是一个System.Object类型的对象,在获取的使用我们需要进行手工转型;而Session Item的Key是手工指定的字符串,如果没有对Key值进行有效的分配,在进行设置的时候很容易造成一个Key值得冲突,从而导致整个状态的混乱;在获取某个Session Item的时候,你指定的Key值可能和预先指定的不符。
- 其次,统一的SessionState的清除机制的缺乏导致服务端内存压力。 在默认的情况下(采用InProc会话模式),SessionState存储于服务端内存,如果过多、过大的Session Item常驻内存,势必会为服务端带来内存压力。实际上,基于客户端的所有的Session Item并不是在整个Session存续期间都是必须的,很多Session Item仅仅是在某几个少数的Web页面中使用。但是我们不能通过程序手工地将其从SessionState中删除,因为我们不能确定该Session Item在那一刻不再需要,因为这往往取决于UI交互的行为。如果太多的低频率使用的Session Item存在,并且它们还不小,服务端内存过多地被占用必要导致性能的下降。
- 最后,如果你采用State Server或者SQL Server会话管理模式,还会造成更多的性能问题。 这样的性能损失包括:Session Item的序列化和反序列化、序列化后的Session Item在Web Server和State Server或者SQL Server的网络传输、针对State Server或者SQL Server的数据存取(保存和提取)等。
实际上,我们的State框架还是建立在SessionState基础之上,但是它能够很好的解决上述的三大难题:
- 通过配置为所有使用到的状态项(状态属性名称、数据类型等)提供结构化的定义,并通过基于该结构化配置提供的代码生成使强类型编程成为可能。这比较类似于ASP.NET中Profile的配置和强类型编程的方式;
- 提供状态的后备存储(Backing Storing)机制将低频率使用的大对象从SessionState中移到相应的后备存储(比如文件、数据库)中,从而缓解服务端内存压力;
- 提供灵活的后备策略定义方 式以实现基于具体运行环境的最优配置。后备策略主要包括两方面的内容,其一是怎样的状态项需要被后备存储,其二采用怎样的方式进行后备存储。确定后备存储 状态项的因素包括:自最近一次被访问以来的超时时限(通过使用频率判断状态项再次被使用的可能性);需要被后备存储对象必须具有的最小字节数(后备存储小 对象毫无意义) ;以及状态项的作用域(很多状态项的作用范围仅仅限于某一个相关的Web页面,或者基于某个基地址)等。而具体采用的后备存储方式决定于配置的“后备存储 器”,比如在我提供的例子中采用的是基于文件的存储方式,你可以编写基于数据库的后备存储器。
二、通过状态后备存储机制解决Web Server内存的压力
状态的后备机制是整个状态编程框架的核心。通过对所有状态项的扫描,标记出所有需要进行后备存储的状态项。然后将它们进行序列化,并借助于指定的后备存储器将它们存储到相应的物理存储介质。最后,相应的状态会从SessionState中删除,从而缓解了Web Server的内存压力。除了将序列化的状态对象进行后备存储之前,后备存储器还负责从相应的存储介质中提取状态数据。
 简单起见,我们并没有在后台运行一个实施后备检测操作的引擎,而是直接通过事件注册的方式让每一个请求自动去触发基于本会话的后备存储,我们注册的事件是HttpApplication的PostRequestHandlerExecute。出于性能的考虑,当事件PostRequestHandlerExecute被触发的时候,并不是总是立即执行后备状态项的检查。而是设置一个相邻两次后备检查的间隔,只有超出这个间隔的情况下,才会进行真正地区检查那些状态向需要进行后备存储了。状态项的后备存储紧接着在后备对象的检查之后进行。
简单起见,我们并没有在后台运行一个实施后备检测操作的引擎,而是直接通过事件注册的方式让每一个请求自动去触发基于本会话的后备存储,我们注册的事件是HttpApplication的PostRequestHandlerExecute。出于性能的考虑,当事件PostRequestHandlerExecute被触发的时候,并不是总是立即执行后备状态项的检查。而是设置一个相邻两次后备检查的间隔,只有超出这个间隔的情况下,才会进行真正地区检查那些状态向需要进行后备存储了。状态项的后备存储紧接着在后备对象的检查之后进行。
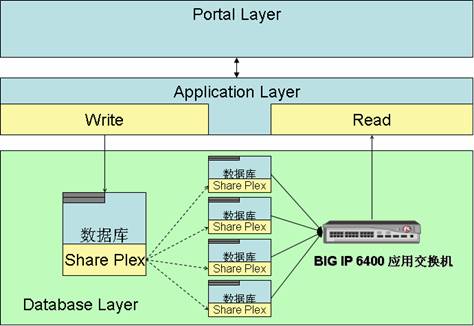
我们通过一个具体的例子来进一步说明后备存储的过程。如左图(点击看大图)所示,在Web Server的IIS进程中的SessionState中维持着三个状态项:Foo、Bar、Baz。当Web Server接收并执行来自浏览器的HTTP请求后,PostRequestHandlerExecute事件的处罚激活了我们的后备检查管理器,它发现状态项Baz最近一次被访问的时间到当前时间的间隔已经超出了设置的超时时限,并且计算出该对象的总字节数超过了设定的下限,就会将该对象标记为后备存储对象。在这种情况下,状态项Baz的值,同它的Key一并进行序列化并进行后备存储。最后将该Baz从SessionState中移除。
如果该Web应用使用Web Farm部署方式,并采用了Sate Server或者SQL Server的会话模式,在同步到Sate Server或者SQL Server的时候,由于SessionState中缺少了Baz这个大对象,也会因为少了对它序列化、网络传输和数据存取使性能得到相应的提升。
三、后备存储状态项的“复苏”
 被后备存储的状态项已经不再存储于SessionState中,但是并不意味着它已经是所谓的垃圾对象,它们依然可以被再次访问。在这种情况下,我们会通过我们指定的后备存储器将相应的状态值以字节数组的形式从存储介质中提取出来,进行反序列化后再次放到SessionState中,我个人将这种机制成为“后备对象的复苏”。
被后备存储的状态项已经不再存储于SessionState中,但是并不意味着它已经是所谓的垃圾对象,它们依然可以被再次访问。在这种情况下,我们会通过我们指定的后备存储器将相应的状态值以字节数组的形式从存储介质中提取出来,进行反序列化后再次放到SessionState中,我个人将这种机制成为“后备对象的复苏”。

在对后备对象的复苏机制进行进一步讲解之前,我们需要了解一个前提:框架始终维护着每一个状态项运行时信息,这些信息包括:状态项最后一次被访问的时间、状态项的使用范围、状态项当前的存储位置(SessionState或者BackingStore)、以及相关的后备策略信息等。这个列表放在SessionState中。
右 面所示的序列图(点击看大图)反映了当我们的程序获取某个状态项时,状态后备机制采用的处理流程:当接收到一个来自对某个状态项的请求时,根据Key值获 取该状态项当前的运行时信息。如果运行时信息反映它还存在于SessionState中(Location=Session),则直接从 SessionState中返回,并更新它的运行时信息(最后一次被访问时间)。
如果该状态项已经进行了背后存储 (Location=BackingStore),则借助相应的后备存储器从存储介质中对应的值以字节数组的形式提取出来。在完成反系列化后再次保存到 SessionState中,并更新相应运行时信息(最后一次访问时间和当前位置:BackingStore-〉Session)。最后返回反序列化后的 具体状态对象。
四、状态项后备策略的定义
判断一个存在于SessionState中的状态项是否应该被后备存储取决于以下三个方面,当同时满足条件1和2,或者2和3的状态项会被后备存储。
- 针对该状态项的最近一次访问的事件到当前时间的间隔超过了设定的超时时限;
- 状态项的总的字节数超过了设定的需要进行后备存储的下限;
- 当前的请求的URL是否超出了设定的状态作用的范围。
但是我们的状态后备策略并没有直接应用于单个的状态项,而是应用于一个较大的粒度:状态组——若干相关状态项的组合。状态组的结构和应用在它上面的后备策略通过配置进行定义,下面的XML体现的配置大体上的结构。
1: <?xml version="1.0" encoding="utf-8" ?>
2: <states>
3: <properties>
4: <property name="UserName" type="System.String"/>
5: <property name="Position" type="System.String"/>
6: </properties>
7: <group name="Profile" inactiveTimeout="00:10:00" minimunTotalBytes="1024" >
8: <property name="Age" type="System.Int32"/>
9: <property name="Address" type="System.String"/>
10: </group>
11: <group name="Product" inactiveTimeout="00:10:00" minimunTotalBytes="1024" scope="Page1, Page2,Page3" >
12: <property name="ProductId" type="System.String"/>
13: <property name="UnitPrice" type="System.Decimal"/>
14: </group>
15: </states>
在上面的XML片段中,我们定义两个全局的状态项(UserName和Position)和两个状态组(Profile和Product)。两个状态组中又包含各自的状态项,以及对应的后备策略。inactiveTimeout、minimumTotlaBytes和scope分别表示超时时限、序列化后的最下值和使用的范围。
五、通过代码生成机制帮助你以强类型的方式操作状态
既然所有的状态和数据类型(即可以是系统预定义类型,也可以是自定义类型)都能通过XML的形式表示出来,那么我们就能通过代码生成机制将它们通过代码的形式反映出来。你可以采用CodeDOM+Cutom Tool的方式[可以参考我的文章《从数据到代码》(上篇、下篇)],或者是直接使用T4模板[可以参考我的文章《创建代码生成器可以很简单:如何通过T4模板生成代码?》(上篇、下篇)]。比如说,你可以生成一个继承自Page的类型,比如PageBase,添加如下一个State的属性。(下面的代码仅仅代码大体的结构,并省略的具体的实现)
1: public class PageBase : Page
2: {
3: public ExtendedRootStateNode State { get; }
4: }
5: public class ExtendedRootStateNode : RootStateNode
6: {
7: public string UserName { get; set; }
8: public string Position { get; set; }
9: public ProfileGroupStateNode Profile { get; private set; }
10: public ProductGroupStateNode Product { get; private set; }
11: }
12: public class ProfileGroupStateNode : GroupStateNode
13: {
14: public int Age { get; set; }
15: public Gender Gender { get; set; }
16: public string Address { get; set; }
17: }
18: public class ProductGroupStateNode : GroupStateNode
19: {
20: public string ProductId { get; set; }
21: public string ProductName { get; set; }
22: }
如果让你的所有Web页面都继承自这个PageBase,你可以通过强类型的方式获取或者设置每个状态项了。

出处:http://artech.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。














 用户提供验证信息点击登录按钮,请求没有回置到站点
用户提供验证信息点击登录按钮,请求没有回置到站点




