
[转载]也谈WEB打印(二):简单的分析一下IE的打印原理并实现简单的打印和预览 – 悼念死难同胞 – 博客园.
在《也谈WEB打印(–):目前的几种方式及我们的任务》中,分析了一下当前Web打印的几种方式以及我们所遇到的问题,并提出了我们的要求,本文简单的分析一下IE的打印原理,并实现简单的打印和预览功能。
首先,我们介绍一下IE架构:
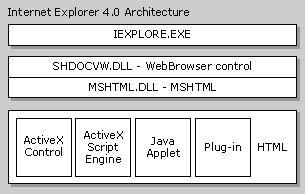
IExplore.exe位于最上层,他是一个很小的应用程序,当IE装载的时候他就被实例化。该可执行程序使用IE的各种组件来执行导航,历史记录维护,收藏夹维护,HTML解析和渲染等,同时为独立的浏览器提供工具栏和框架。IExplorer.exe是Shdocvw.dll 组件的直接宿主。
Shdocvw.dll依次寄宿Mshtml.dll,当有其他的活动文档组件(例如MS Office应用),当用户导航到这些特定的文档的时候,可以就地装入浏览器。Shdocvw.dll 提供这些和导航联系在一起的功能:就地链接、收藏夹和历史记录管理、PICS支持。该动态链接库也向其宿主暴露了一些接口,以允许这些宿主可以把他当作ActiveX控件而分别寄宿。
在Shdocvw.dll中有一个接口叫做IWebBrowser2,我们所见到的IE, 其实基本上就是对该接口的一个包装。他有一个很重要的成员函数“ExecWB”,其原型如下:
HRESULT ExecWB(
OLECMDID cmdID,
OLECMDEXECOPT cmdexecopt,
VARIANT *pvaIn,
VARIANT *pvaOut
);
通过给这个函数的cmdID和cmdexecopt参数指定适当的值,我们几乎可以做能够IE界面上所做的所有事情。下面举例说明如何在js中调用该函数:
在html页面中加 入如下语句:
<OBJECT classid=CLSID:8856F961-340A-11D0-A96B-00C04FD705A2 height=0 id=WebBrowser width=0></OBJECT>
<input type=”button” value=”直接打印” onclick=”browser.ExecWB(6,1);”/>
<input type=”button” value=”打印预览” onclick=”browser.ExecWB(7,1);”/>
<input type=”button” value=”页面设置” onclick=”browser.ExecWB(8,1);”/>
然后再单击3个Button,IE就会相应的执行打印,打印预览,页面设置3个动作。
关于ExecWB的 更多使用,在MSDN中有更多的描述,在此不再多说。该命令实际上就是调用IOleCommandTarget 接口的Exec函 数,该函数的原型如下:
HRESULT Exec(
const GUID *pguidCmdGroup, // Pointer to command group
DWORD nCmdID, // Identifier of command to execute
DWORD nCmdExecOpt, // Options for executing the command
VARIANTARG *pvaIn, // Pointer to input arguments
VARIANTARG *pvaOut // Pointer to command output
);
如果我们获得了一个IWebBrowser2的实例,并把他转换为IOleCommandTarget接口,然后给Exec函 数赋予适当的值,就可以实现我们的预期的功能了。MSDN上说必须用C++才能实现这些功能,实际上用Delphi,C#一样可以实现这些功能。下面我们就实现一个C#的简 单实例。
首先,我们新建一个WinForm项目,然后在窗体上添加加一个控件,使得主界面看起来像下图 所示:
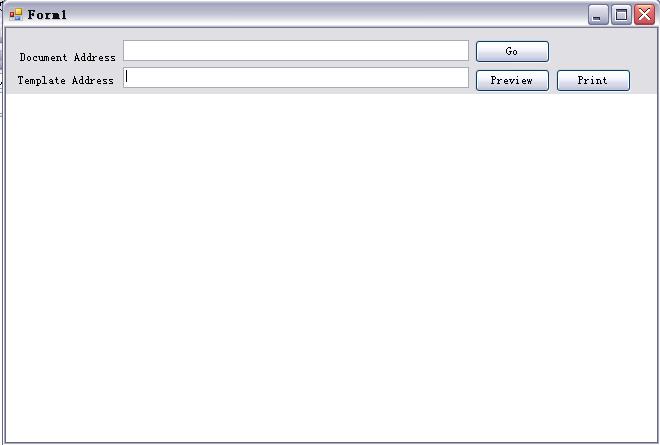
其中最下一个是System.Windows.Forms.WebBrowser控件,命名为Browser。
然后我们定义如下的Interface和Class:
using System;
using System.Runtime.InteropServices;
using System.Runtime.InteropServices.ComTypes;
[ComImport(), Guid(“B722BCCB-4E68-101B-A2BC-00AA00404770”),
InterfaceType(ComInterfaceType.InterfaceIsIUnknown)]
public interface IOleCommandTarget
{
[PreserveSig()]
int QueryStatus([In, MarshalAs(UnmanagedType.Struct)] ref Guid
pguidCmdGroup, [MarshalAs(UnmanagedType.U4)] int cCmds,
[In, Out] IntPtr prgCmds, [In, Out] IntPtr pCmdText);
[PreserveSig()]
int Exec(ref Guid pguidCmdGroup, uint nCmdID, uint nCmdExecOpt,
[In, MarshalAs(UnmanagedType.LPArray)] object[] pvaIn,
[In, Out, MarshalAs(UnmanagedType.LPArray)] object[] pvaOut);
}
public enum OLECMDEXECOPT
{
OLECMDEXECOPT_DODEFAULT,
OLECMDEXECOPT_PROMPTUSER,
OLECMDEXECOPT_DONTPROMPTUSER,
OLECMDEXECOPT_SHOWHELP
}
public static class GlobalConst
{
public const int MSOCMDEXECOPT_DONTPROMPTUSER = 2;
public const int IDM_PRINT = 0x1b;
public const int IDM_PRINTPREVIEW = 0x7d3;
public static readonly Guid CGID_MSHTML = new Guid(“DE4BA900-59CA-11CF-9592-444553540000”);
public static readonly Guid IID_OleCommandTarget = new Guid(“B722BCCB-4E68-101B-A2BC-00AA00404770”);
}
我们给“GO”按钮 添加Click事件处理代码:
this.Browser.Navigate(txtAddr.Text);
注意,txtAddr.Text所代表的地址必须存在,否则,在WebBrowser控件中会出现“无法显示网页”的错误。不过对于我们的演示并没有什么影响。
然后我们给“Preview”按钮添加Click事 件处理代码:
IOleCommandTarget pCmdTarg = Browser.ActiveXInstance as IOleCommandTarget;
Guid CGID_MSHTML = GlobalConst.CGID_MSHTML;
string vTemplatePath = txtTemplateAddr.Text;
pCmdTarg.Exec(ref CGID_MSHTML,
GlobalConst.IDM_PRINTPREVIEW,
(uint)OLECMDEXECOPT.OLECMDEXECOPT_PROMPTUSER,
null,
null);
上述代码中中的Browser.ActiveXInstance实际上就是一个IWebBrowser2接口的实现。
启动程序,在Document Address文本框中输入www.cnblogs.com,单击Go按钮, 然后单击Preview按钮,你看到了什么?
我这里效果如下图所示: 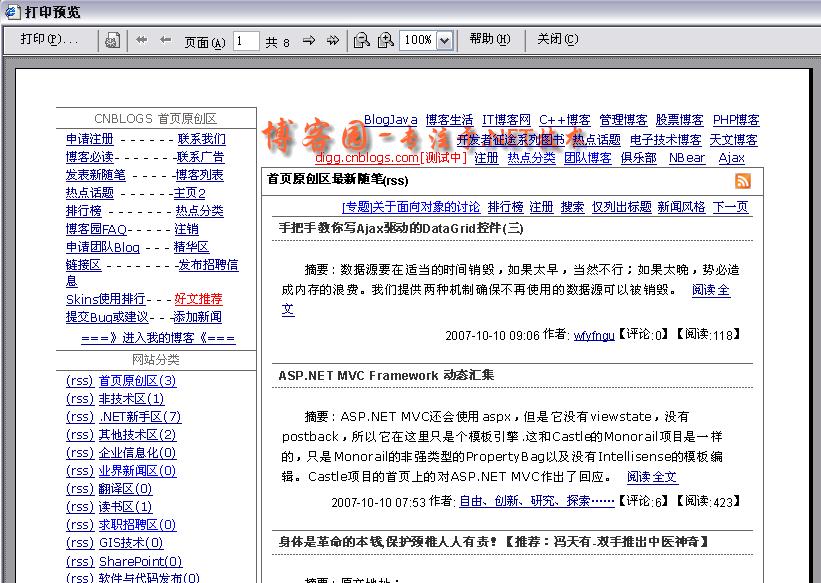
然后我们再给Print按钮添加Click事件的处理代码:
IOleCommandTarget pCmdTarg = Browser.ActiveXInstance as IOleCommandTarget;
Guid CGID_MSHTML = GlobalConst.CGID_MSHTML;
string vTemplatePath = txtTemplateAddr.Text;
pCmdTarg.Exec(ref CGID_MSHTML,
GlobalConst.IDM_PRINT,
(uint)OLECMDEXECOPT.OLECMDEXECOPT_PROMPTUSER,
null,
null);
启动程序,在Document Address文本框中输入www.cnblogs.com,单击Go按钮, 然后单击Print按钮,你看到了什么?
我这里效果如下图所示:
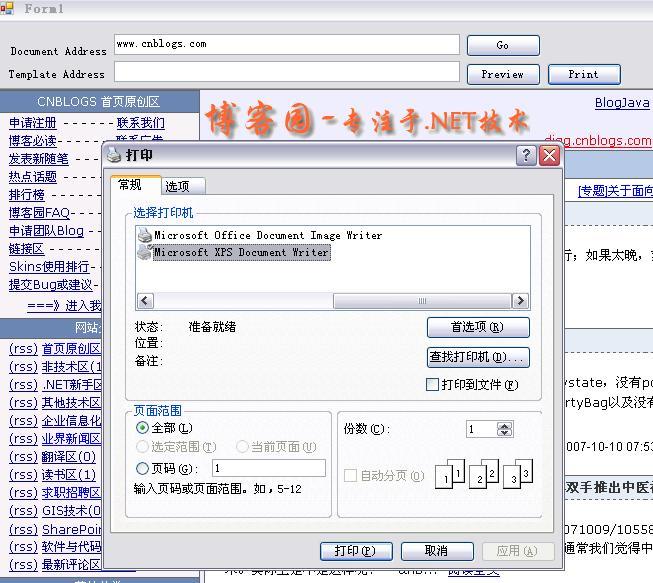
到现在为止,我们获取了一个IWebBrowser2的实例,并且可以操 作调用他的Print和Print Preview功能了。但是,我们还不能对如何打印进行控制。
那么我们如何对打印进行控制呢?关键就是IOleCommandTarget接口Exec函数的第4个参数,该参数指定了IWebBrowser2进行打印的模板,如果为NULL,那么IWebBrower2使用IE缺省的模板,如果指定的模板文件不存在,那么单击Preview的时候就会显示一个空的环境,什么都不显示,就像下图所示 的这样:
![]()
好了,今天就讲到这里,在下篇文章,我们继续讨论如何实现自己的打印模板。
欢迎大家拍砖。










