大小站长一直在喊:”内容为王!“可真正又有多少人注重过用户体验才是网站的根本,即使内容再多,不能让访问者简单、轻松、快速的获得信息,再好的内容也只能埋没在”深巷“,现在已经是”酒香就怕巷子深“的时代了。
不妨各位站长扪心自问几个问题来测试一下自己的站的用户体验吧!
1.用户第一次访问你的网站,用户会不会知道这个网站是做什么的?
2.用户能明白各栏目的含义吗?
3.用户想找到感兴趣的信息需要几次操作?
4.注册用户会不会使用提供的功能?
5.用户不会用功能,是否提供了帮助说明?
这是我本人浏览网站时比较注意的几个问题,每个人可能浏览习惯不一样,可能对网站的体验评定标准不一样,但是如果上述几点不满足,相信大部分用户都不会第二次再访问你的网站了。
网站作为一种展示信息的媒体,不是做给自己看的,做站之前最好先考虑一下用户的感受,不要老盯着百度排行,再高的排名,给访问的人的感受很差,甚至是愤怒!相信你的站也只能是昙花一现,不要为做站而做站,既然做就踏踏实实的做个能让人浏览的站而不是蜘蛛浏览的站。

[转载]SqlServer性能优化——Slide Window
[转载]SqlServer性能优化——Slide Window – smjack – 博客园.
虽然对数据库进行分区本身就能提高查询的性能,结合压缩,也能减少每次查询的IO。但如果数据持续增长,过于久远的历史数据就成了一个包袱,它们从 来不在查询结果中出现,却或多或少的影响着每次查询的时间,成了一个挥之不去的阴影。此外,由于一个分区表的分区是有上限的(在2005中这一上限是 1000),我们也并不能在一张表上一直分区下去。所以在这种情况下,我们一般需要同时拥有两张表,一张保存了最近的数据,用来应付所有 的查询,这张表要足够精简,在其上的查询要足够敏捷;同时有另一张表,保存所有过时的数据——我们并不能把过时的数据一删了事。
这里面的关键问题是,既然数据是随着时间持续增长的,那么当下有用的数据可能在几天后就过时了,那么怎样将这一部分过时的数据 从活动表迁移到存档表,而且要保证迁移过程的快速、平稳呢?如果采用常规的Select、Insert、Delete来进行数据迁移, 会有如下问题:
- IO过大,效率必然较低。
- 迁移过程表被锁住,所有查询都会被搁置。
- 恢复困难,如果想将移出的数据再移回来,需要进行同样的操作,IO和锁表的问题同样存在。
那么很容易 想到,利用之前提到的分区的Switch操作来解决迁移的问题,将整个分区而不是数据在活动表和存档表中迁移。由于 Switch的元数据操作属性,这一几乎没有什么IO的操作效率极高,而且也不会锁表。基于以上方法进行的周期性自动化的数据迁移,就是Slide Window的基础。
原理图
假设我们已经有一张活动表,分了四个区,分别对应去年,今年一 月、二月以及三月以后的数据:

同时我们有另外一个存档表,分成了两个区, 第一个区对应今年以前的数据,另外一个分区的范围是今年之后:

注意,活动表的第一个分区、存 档表中的第二个分区是没有数据的,这是进行Slide Window的前提条件。
现在,我们考虑将活动表中的一月份 的数据放入存档表中,而且我们还要保证在迁移之后,两张表保持和迁移前相似的状态。
那么我们可以采用如下的步骤:
1. 在存档表中建立新分区:

2.将活动表的第二个分区挪到存档表的第二个分 区中:

迁移的结果如下:
至此,我们已经完成了数据的迁移,但为了恢复两 张表到之前的状态,我们还需要以下两个步骤:
3.合并存档表的第一和第二个分区。
4.拆分活动表的第三个分区。
最后的结果,活动表:
 存档表:
存档表:
 我们可以看到迁移过后,两张表的分区数量没有变,而且存档表的第二个 分区依然是空的。当需要迁移二月份的数据时,我们可以采用和上面完全一样的步骤进行迁移。而这一过程,类似在时间轴上开了一个窗口,将当前数据在活动表上 展示,随着时间推移,窗口不断向前滑动(活动表的边界前移),而且窗口大小(活动表的分区数)始终保持不变,这就是Slide Window(滑动窗口)这一名称的来源。
我们可以看到迁移过后,两张表的分区数量没有变,而且存档表的第二个 分区依然是空的。当需要迁移二月份的数据时,我们可以采用和上面完全一样的步骤进行迁移。而这一过程,类似在时间轴上开了一个窗口,将当前数据在活动表上 展示,随着时间推移,窗口不断向前滑动(活动表的边界前移),而且窗口大小(活动表的分区数)始终保持不变,这就是Slide Window(滑动窗口)这一名称的来源。
建立存档表
建立存档表最简单的方法是选中分好区的活动表,在 Storage菜单中选择“Manage Partition”,然后选择“Create a stagin table for partition switching”。建议将“Staging table name”改成固定的没有数字后缀的名字,之后随便选择一个“Switch Parition”,最后生成创建存档表的脚本。

由于指定了待切换的分区,所以这里脚本中会添 加对应的约束,由于我们要创建的存档表并不应该有边界限定,所以应当把脚本中添加边界约束的部分删除,运行,生成存档表。
接下来要对存 档表进行分区,一般来说,存档表分成两个区就可以应对任意分区数量的活动表了,当然,分的更多也没有问题。存档表的分区边界要和活动表的对应边界一致,也 就是存档表的第一个分区和第二个分区的边界等于活动表的第一个分区和第二个分区的边界。
此时存档表中并没有数据,我们可以用
ALTER TABLE [STable] SWITCH PARTITION 1 TO [DTable] PARTITION 1
将活动表的第一个分区迁移到存档表的第一个分区中。这样活动表的第一个分区、存档表的第二个分区为空,也就达成了前文所述的执行Slide Window的前提条件。
自动执行
有了存档表,就可以进行滑动窗口了。以用时间类型字段做分区依据的表为例,这里我把执行脚本存到一个存储过程里:
CREATE PROCEDURE [dbo].[sp_SlideWindow] @SplitRange SMALLDATETIME -- 指定活动表新增分区的边界 AS BEGIN DECLARE @SwitchRange SMALLDATETIME DECLARE @MergeRange SMALLDATETIME --获得活动表、存档表合并分区以及存档表的新分区的边界 SELECT @MergeRange=CONVERT(SMALLDATETIME,value) FROM sys.partition_range_values, sys.partition_functions WHERE sys.partition_functions.function_id = sys.partition_range_values.function_id AND sys.partition_functions.name = 'E_Alive_Partition_Func' AND boundary_id = 1 SELECT @SwitchRange=CONVERT(SMALLDATETIME,value) FROM sys.partition_range_values, sys.partition_functions WHERE sys.partition_functions.function_id = sys.partition_range_values.function_id AND sys.partition_functions.name = 'E_Alive_Partition_Func' AND boundary_id = 2 BEGIN TRANSACTION ALTER PARTITION SCHEME [E_Alive_Partition_Schema] NEXT USED [PRIMARY] ALTER PARTITION SCHEME [E_Staging_Partition_Schema] NEXT USED [PRIMARY] --在活动表中新增分区 ALTER PARTITION FUNCTION [E_Alive_Partition_Func]()SPLIT RANGE(CONVERT(NVARCHAR,@SplitRange,120)) --在存档表中新增分区 ALTER PARTITION FUNCTION [E_Staging_Partition_Func]()SPLIT RANGE(CONVERT(NVARCHAR,@SwitchRange ,120)) --切换分区 ALTER TABLE [Alive_Table] SWITCH PARTITION 2 TO [Staging_Table] PARTITION 2 --合并活动表分区与存档表分区 ALTER PARTITION FUNCTION [E_Alive_Partition_Func]() MERGE RANGE(CONVERT(NVARCHAR,@MergeRange,120)) ALTER PARTITION FUNCTION [E_Staging_Partition_Func]() MERGE RANGE(CONVERT(NVARCHAR,@MergeRange,120)) COMMIT TRANSACTION END
在整个滑动窗口的操作过程中,活动表和存档表分别合并和拆分了两次,有四个相关边界值。而由于活动表的合并边界值和存档表的合并边界值是一样的,所 以实际有三个边界值。其中合并边界就是第一个分区和第二个分区的边界,而存档表的拆分边界就是活动表的第二个分区和第三个分区的边界,这些都可以通过 sys.partition_range_values, sys.partition_functions表获得。所以这个存储过程只 需要输入一个变量,即活动表新拆分出的分区的边界。
注意
- 由于新拆分的分区中非聚集索引不会应用原来的压缩方式,所以如有需要,应当在存储过程中补充对相应索引做压缩的操作。
- 之所以在存储过程中先进行分区的拆分,再进行分区切换,最后进行分区合并,是考虑对空的分区(切换前的存档表的第二分区、切换后的活动表的 一、二分区)进行拆分或者合并效率比较高。
- 以上只是Slide Window的一种方式,事实上,如果对历史数据不那么在意,我们依然可以用分区切换的方式,将旧的数据移出然后删除。或者使用多个存档表,每次都将活动 表的最后一个分区移到新的存档表中,这样省去了合并存档表分区的性能消耗,但多个存档表可能在管理上会比较麻烦。
后记:
关于数据库的“压缩”、“分区”、“滑动窗口”,这里就算告一段落了。虽然题目是“SQLServer性能优化”,其实这里提到的仅仅是关 于性能优化比较偏门的一小部分,最常用的类似“索引”、“查询结构”之类的性能优化技巧并没有涉及。
而即使是这一小部分,也是诚惶诚恐。虽然这些技巧都在实际应用中实践过,但真要写出来,却还是有些力不从心,写博的过程基本就是重新学习的 过程,其间翻阅了很多资料,不求有功,但求无过,不至于误人子弟。但毕竟百密一疏,而且即使看的资料,也不敢保证来源真确。所以来往过客,如有个中高手, 能指点出文中瑕疵疏漏,不至于谬误流传,小弟不胜感激。
[转载]批量发布Flash文件
我现在主要的工作是负责做多媒体动画了,我不会绘画,也不懂设计,不过我会写程序。好呆也是做过.net编程的。
大家Flash动画做了上千个,要发布产品了,于是研发主管招唤大家一起发布,可我是个懒人,首先就想,有没有批量发布的程序。
网上搜了一下,还真有。是用jsfl写的。
代码看懂了,又找了些jsfl的教程看了看,于是决定扩展一下功能,写个flash插件出来,至少带个操作界面,用时方便,毕竟这个东东不只是我 用。
这个flash插件功能很简单,能够批量发布一个或多个文件夹下的fla文件,包括其子目录下的;设定好,让它慢慢发布就行了,还算实用,至少能满 足我现在的工作。
首先是一个UI。
文件名,就是PublishBatUI.xml。
然后就是Jsfl代码了。
文件名保存为“批量发布Fla.jsfl”
将两个文件放置到如下目录下:
如果是Flash8,放到C:\Documents and Settings\Administrator\Local Settings\Application Data\Macromedia\Flash 8\zh_cn\Configuration\Commands
如果是Flash CS3,放到C:\Documents and Settings\Administrator\Local Settings\Application Data\Adobe\Flash CS3\zh_cn\Configuration\Commands
重新打开Flash,不管是flash8还是flash cs3,在其主菜单“命令”中,都会看到“批量发布fla”的命令。
[转载]游标与事物与错误消息机制
[转载]游标与事物与错误消息机制 – 交流空间 – 博客园.
一、游标概念: 将某一结果集作为一个集合处理,且每次处理数据集的一行或一行的某些字段。
建立游标结构如下:
1. 定义游标,将游标与Transact-SQL语句的结果集相关联。
Declare @bookid int, @bname varchar(50),@bindex int
Declare book_cursor cursor for
Select bookid,bookname,bookIndex from Bas_bookList
2. 执行Transact-SQL语句数据集填充游标即打开游标
Open book_cursor
3. 从游标中检索到第一行,并提取第一行或第一行的某些字段。
Fetch next from book_cursor into @bookid,@bname,@bindex
4. 根据需要对当前行进行操作
@@Fetch_status包括三种状态 0,-1,-2。以此来判断游标执行是否正确。
0则游标执行正确,-1 游标中出现错误,-2 找到空行
While @@fetch_status=0
Begin
Delete update insert 等等
Fetch next from book_cursor into @bookid,@bname,@bindex 选取下一行数据
End
4. 关闭游标
Close book_cursor
Deallocate book_cursor
说明: 客户端游标,被odbc所支持,在使用时会有一些限制,只能使用只进和静态游标,它是把结果缓存到客户端,所有游标的操作都由客户端高速缓存下来。并不在 服务器端执行,一般情况下都不这样使用, 只是对一些服务端不支持的Transact-SQL和批处理才使用。
这小段只是我对客户端游标的理解,仅作参考。
二、事物,用起来很简单这里就不在详细介绍了。
1. 在存储过程中使用事物
语句结构:
事务起始点: Begin transaction
提交事物,完成自事物起始点开始的数据操作变化,释放事务所占用的资源:Commit TranSaction
如果事务出现错误,回滚:Rollback
在事务起始点,begin transaction tran1 使@@TRANCOUNT 按 1 递增
执行事务,commit ttansaction tran1 使@@TRANCOUNT 按1 递减,直到减少到0
回滚是到事务的起点或事务的某个保存点也就是定义点。
2. 在C#程序中也可以使用事物
Using(System.Data.SqlClient.SqlConnection conn=new System.Data.SqlClient.SqlConnection(“数据库连接字符串”))
{
conn.open();
using (System.Data.SqlClient.SqlTransaction trans=conn.BeginTransaction())
{
Try
{
sql语句 ;
Trans.Commit();
}
Catch
{
Trans.Rollback();
}
}
}
三、Transact-SQL实现类似于C#语言中的异常处理。Transact-SQL语句组可以包含在TRY块中,如果TRY块内部发生错误, 则会将事件处理转到Catch块中。
语句结构
BEGIN TRY
Transact-SQL语句
END TRY
BEGIN CATCH
错误处理机制
END CATCH
其实以上讲述的基础知识。刚开始从事开发工作就知道明白,会用了。
此文只是系统地总结一下。供大家参考。算不上精辟。
我在实际的应用中发现一个问题,对于一个复杂的存储过程,把上面三种用法综合到一起,会提高不少的执行效率。一是为了找到错误点,回滚事物,把 try和 transaction组合到一起,如果大量数据要处理,可能会用到游标,有时候在想,事物当执行commit的时候才会永久地处理数据,是不是在用游标 的时候也这样,把游标写到事物里,把所有的游标都执行完毕,再进行事物处理,如果异常则回滚。试了一下,果然快很多。而且在Transact-Sql里同 一存储过程定义的变量,在整个运行周期都是有效的,这就很好将整个构想实现了。例如:
SET NOCOUNT ON;
BEGIN TRY
BEGIN TRANSACTION tran1
DECLARE @proarageid BIGINT,@procomid BIGINT,@proagentid BIGINT,@progropid BIGINT
—语句
DECLARE acursor CURSOR
FOR SELECT id,provicename,cityname FROM Ass_ArrearageTemporary
OPEN acursor
FETCH NEXT FROM acursor INTO @proarageid,@procomid,@proagentid WHILE @@FETCH_STATUS = 0
BEGIN
—语句
FETCH NEXT FROM acursor INTO @proarageid,@procomid,@proagentid
END
COMMIT TRANSACTION tran1
CLOSE acursor
DEALLOCATE acursor
END TRY
begin CATCH
IF @@TRANCOUNT > 0
BEGIN
CLOSE acursor
DEALLOCATE acursor
ROLLBACK TRANSACTION tran1
return
END
END CATCH
虽不是含量很高,但也是笔者的心血。
[转载]ASP.NET MVC 环境配置,从1.0到2.0的转换和学习资源等
[转载]ASP.NET MVC 环境配置,从1.0到2.0的转换和学习资源等 – 凭海观澜 – 博客园.
一、下载地址:
在4.12号发布的vs 2010正式版,Visual Web Developer 2010正式版中将会置对ASP.NET mvc2的支持.
在页面底部有三个文件下载ASP.NET-MVC-2-RTM-Release-Notes.doc、AspNetMVC2_VS2008.exe 和mvc2-ms-pl.zip。下载完后安装AspNetMVC2_VS2008.exe即可,
注意:前提是你必须安装了vs2008sp1:
二、从1.0到2.0的转换
在Download下面点链接下载
The app is a single executable: Download MvcAppConverter.zip (220 KB).
解压缩后选择对应的MVC1.0的solution进行转换即可
三、已安装vs2010beta时的解决办法:
在ASP.NET-MVC-2-RTM-Release-Notes.doc中有这样的说明:
Note :
Because Visual Studio 2008 and Visual Studio 2010 RC share a component of ASP.NET MVC 2, installing the ASP.NET MVC 2 RTM release on a computer where Visual Studio 2010 RC is also installed is not supported.
也就是说在安装完vs2010beta后,再安装AspNetMVC2_VS2008.exe会提示已经安装完成,但是vs2008缺没有对应的 MVC2,如果打开包含MVC2的Project,会报如下的错误:
The project type is not support by this installation.
我的解决方法是:
在不卸载2010的情况只需要从添加、删除程序里面把
Microsoft ASP.NET MVC2和Microsoft ASP.NET MVC2-visual studio 2010 tools卸载,然后再装AspNetMVC2_VS2008.exe即可。
四、学习资源:
[转载]淘宝API开发系列--商家的绑定
[转载]淘宝API开发系列–商家的绑定 – wuhuacong(伍华聪)的专栏 – 博客园.
在上篇《淘宝API开发系列 –开篇概述》介绍了下淘宝API平台的一些基本知识,由于一直有事情忙,就没有及时跟进随笔的更新,本篇继续讨论淘宝API的开 发知识,主要介绍商家的绑定操作。上篇我们说过,淘宝就是基于应用程序键来控制用户的访问频率和流量的,另外可 以通过应用程序键,让使用者登陆确认,获取到相关的授权码,然后获取SessionKey,作为访问使用者淘宝资源(如买入卖出等私人记录的信息)。
我们再看看 SessionKey是如何获取的(下面是淘宝关于正式环境下SessionKey的说明):
正式环境下获取SessionKey
注意:web插件平台应用和web其它应用在正式环境下是同样的获取 方法
1、WEB应用
例如回调URL 为:http://localhost
访问 http://container.open.taobao.com/container?appkey={appkey},页面会跳转到回调URL,地 址类似如下:
http://localhost/?top_appkey={appkey} &top_parameters=xxx&top_session=xxx&top_sign=xxx
回 调url上的top_session参数即为SessionKey
2、客户端应用
访 问 http://auth.open.taobao.com/?appkey={appkey},即可获得授权码
通 过http方式访问 http://container.open.taobao.com/container?authcode={授权码},会得到类似如下的字符串
top_appkey=1142&top_parameters=xxx&top_session=xxx&top_sign=xxx
字符串里面的top_session值即为SessionKey。
由 于本篇文章主要是介绍C/S客户的应用,因此客户端的应用就不能通过回调Url方式获得用户的验证,我们可以通过在Winform中的 WebBrowser控件,显示一个登陆验证及访问确认的操作界面给客户,当客户确认的时候并返回Session Key的内容界面的时候,我们取出Session Key保存并关闭浏览器窗口即可,今后把该SessionKey作为参数来访问相关需要Session Key的API即可。
另外,由于SessionKey的间隔时间比较短,如果API调用间隔时间比较长,那么SessionKey有可能 失效的,但是我们注意到,如果API调用的时候,SesionKey过期 那么会抛出TopException(其中ErrorCode为26或者27是SessionKey过期),里面有关于与TopException的部分 说明如下:
| 26 | Missing Session | 缺少 SessionKey参数 |
| 27 | Invalid Session | 无效的SessionKey参数 |
我 们先看看具体实现的界面,然后分析其中的实现逻辑吧。
1、首次需要登录的时候,使用一个Winform嵌套一个WebBrowser控件, 实现网页登录。
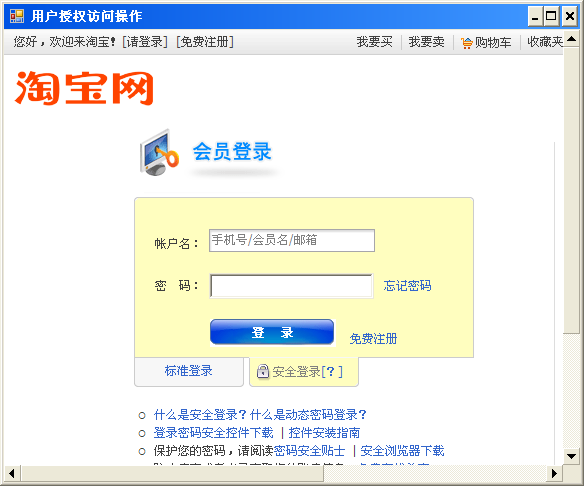
2、商家用户输入账号密码后,确认是否授权程序访问相关资源。
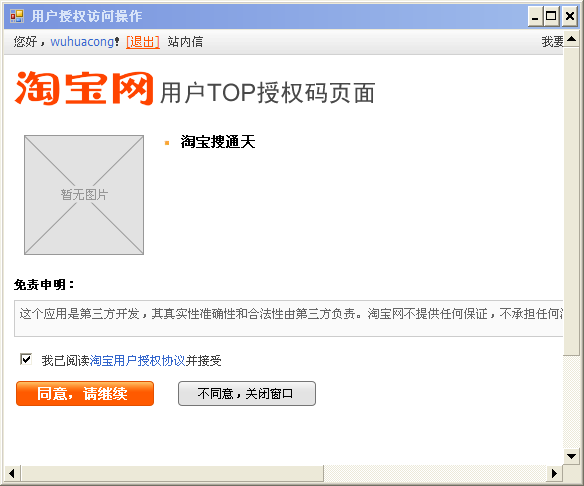
3、确认后生成SessionKey,这个Key正是我们的程序需要的关键内容,因此需要自动获取出来。
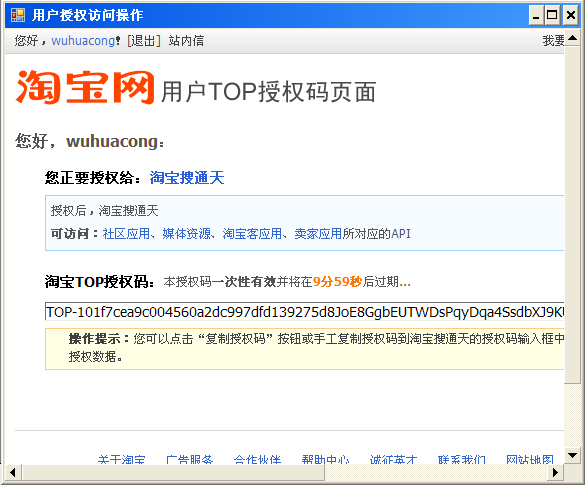
4、程序拿到该Session Key后,把它作为参数来访问淘宝API获取相关的信息,这里获取交易API的购买信息,需要SessionKey的。
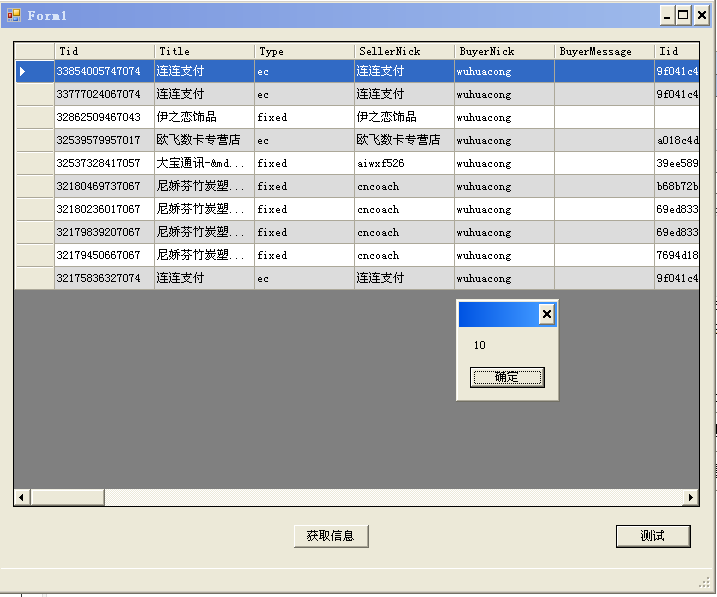
以上就是使用SessionKey的API工作流程界面,我们下面介绍一下相关的实现代码。
1) 主窗体主要的操作代码:

 代码
代码
public partial class Form1 : Form
{
private TopJsonRestClient jsonClient;
private TopContext context; private void Form1_Load(object sender, EventArgs e)
{
this.winGridView1.ProgressBar = this.toolStripProgressBar1.ProgressBar;
this.winGridView1.AppendedMenu = this.contextMenuStrip1;
xmlClient = new TopXmlRestClient(“http://gw.api.taobao.com/router/rest“, “12033411“, “你的密钥“”);
} /// <summary>
/// 判断是 否顺利获取SessionKey
/// </summary>
/// <returns></returns>
private bool GetAuthorizeCode()
{
string authorizeCode = “”;
FrmAuthorized dlg = new FrmAuthorized();
if (dlg.ShowDialog() == DialogResult.OK)
{
authorizeCode = dlg.AuthrizeCode;
}
if (string.IsNullOrEmpty(authorizeCode)) return false;
if (context == null) return false; return true;
} private void BindData()
{
if (context == null)
{
bool flag = GetAuthorizeCode();
if (!flag) return;
} string sessionKey = context.SessionKey; ////获取用户信息
//UserGetRequest request = new UserGetRequest();
//request.Fields = “user_id,nick,sex,created,location,alipay_account,birthday”;
//request.Nick = “wuhuacong”;
//User user = client.Execute(request, new UserJsonParser());
//MessageBox.Show(ReflectionUtil.GetProperties(user));
try
{
//买入交易
TradesBoughtGetRequest req = new TradesBoughtGetRequest();
req.Fields = “tid,title,price,type,iid,seller_nick,buyer_nick,status,orders“;
req.PageNo = 1;
req.PageSize = 10;
ResponseList<Trade> rsp = jsonClient.GetBoughtTrades(req, sessionKey);
this.winGridView1.DataSource = rsp.Content;
MessageBox.Show(rsp.Content.Count.ToString()); //卖出交易
TradesSoldGetRequest soldReq = new TradesSoldGetRequest();
soldReq.Fields = “tid,title,price,type,iid,seller_nick,buyer_nick,status,orders“;
soldReq.PageNo = 1;
soldReq.PageSize = 10;
ResponseList<Trade> soldRsp = jsonClient.GetSoldTrades(soldReq, sessionKey);
this.winGridView1.DataSource = soldRsp.Content;
MessageBox.Show(soldRsp.Content.Count.ToString());
}
catch (TopException ex)
{
if (ex.ErrorCode == 26 || ex.ErrorCode == 27)
{
if (MessageUtil.ShowYesNoAndError(“SessionKey过期,您是否需要 重新认证“) == DialogResult.Yes)
{
bool flag = GetAuthorizeCode();
if (!flag) return;
}
else
{
return;
}
}
}
} private void btnTest_Click(object sender, EventArgs e)
{
BindData();
}
{
private TopJsonRestClient jsonClient;
private TopContext context; private void Form1_Load(object sender, EventArgs e)
{
this.winGridView1.ProgressBar = this.toolStripProgressBar1.ProgressBar;
this.winGridView1.AppendedMenu = this.contextMenuStrip1;
jsonClient
= new TopJsonRestClient(“http://gw.api.taobao.com/router/rest“, “12033411“, “你的密钥“);client
= GetProductTopClient(“json“);xmlClient = new TopXmlRestClient(“http://gw.api.taobao.com/router/rest“, “12033411“, “你的密钥“”);
} /// <summary>
/// 判断是 否顺利获取SessionKey
/// </summary>
/// <returns></returns>
private bool GetAuthorizeCode()
{
string authorizeCode = “”;
FrmAuthorized dlg = new FrmAuthorized();
if (dlg.ShowDialog() == DialogResult.OK)
{
authorizeCode = dlg.AuthrizeCode;
}
if (string.IsNullOrEmpty(authorizeCode)) return false;
context
= SysUtils.GetTopContext(authorizeCode);if (context == null) return false; return true;
} private void BindData()
{
if (context == null)
{
bool flag = GetAuthorizeCode();
if (!flag) return;
} string sessionKey = context.SessionKey; ////获取用户信息
//UserGetRequest request = new UserGetRequest();
//request.Fields = “user_id,nick,sex,created,location,alipay_account,birthday”;
//request.Nick = “wuhuacong”;
//User user = client.Execute(request, new UserJsonParser());
//MessageBox.Show(ReflectionUtil.GetProperties(user));
try
{
//买入交易
TradesBoughtGetRequest req = new TradesBoughtGetRequest();
req.Fields = “tid,title,price,type,iid,seller_nick,buyer_nick,status,orders“;
req.PageNo = 1;
req.PageSize = 10;
ResponseList<Trade> rsp = jsonClient.GetBoughtTrades(req, sessionKey);
this.winGridView1.DataSource = rsp.Content;
MessageBox.Show(rsp.Content.Count.ToString()); //卖出交易
TradesSoldGetRequest soldReq = new TradesSoldGetRequest();
soldReq.Fields = “tid,title,price,type,iid,seller_nick,buyer_nick,status,orders“;
soldReq.PageNo = 1;
soldReq.PageSize = 10;
ResponseList<Trade> soldRsp = jsonClient.GetSoldTrades(soldReq, sessionKey);
this.winGridView1.DataSource = soldRsp.Content;
MessageBox.Show(soldRsp.Content.Count.ToString());
}
catch (TopException ex)
{
if (ex.ErrorCode == 26 || ex.ErrorCode == 27)
{
if (MessageUtil.ShowYesNoAndError(“SessionKey过期,您是否需要 重新认证“) == DialogResult.Yes)
{
bool flag = GetAuthorizeCode();
if (!flag) return;
BindData();
//重新刷新}
else
{
return;
}
}
}
} private void btnTest_Click(object sender, EventArgs e)
{
BindData();
}
2、 用户登陆的窗体,就是一个form窗体加上一个WebBrowser控件,窗体代码如下:
代码
public partial class FrmAuthorized : Form
{
/// <summary>
/// 授权码
/// </summary>
public string AuthrizeCode = “”;
private string url = “http://open.taobao.com/authorize/?appkey=12033411“; public FrmAuthorized()
{
InitializeComponent();
} /// <summary>
/// 获取 HTML页面内制定Key的Value内容
/// </summary>
/// <param name=”html”></param>
/// <param name=”key”></param>
/// <returns></returns>
public string GetHiddenKeyValue(string html, string key)
{
string str = html.Substring(html.IndexOf(key));
str = str.Substring(str.IndexOf(“value“) + 7);
int eindex1 = str.IndexOf(“‘“);
int eindex2 = str.IndexOf(“\“”);
int eindex = eindex2;
if (eindex1 >= 0 && eindex1 < eindex2)
{
eindex = eindex1;
}
return str.Substring(0, eindex);
} private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
if (e.Url.AbsoluteUri == url)
{
AuthrizeCode = GetHiddenKeyValue(this.webBrowser1.DocumentText, “autoInput“);
if (!string.IsNullOrEmpty(AuthrizeCode) && AuthrizeCode.IndexOf(“TOP-“) >= 0)
{
this.DialogResult = DialogResult.OK;
this.Close();
}
}
} private void FrmAuthorized_Load(object sender, EventArgs e)
{
webBrowser1.Navigate(url);
}
}
{
/// <summary>
/// 授权码
/// </summary>
public string AuthrizeCode = “”;
private string url = “http://open.taobao.com/authorize/?appkey=12033411“; public FrmAuthorized()
{
InitializeComponent();
} /// <summary>
/// 获取 HTML页面内制定Key的Value内容
/// </summary>
/// <param name=”html”></param>
/// <param name=”key”></param>
/// <returns></returns>
public string GetHiddenKeyValue(string html, string key)
{
string str = html.Substring(html.IndexOf(key));
str = str.Substring(str.IndexOf(“value“) + 7);
int eindex1 = str.IndexOf(“‘“);
int eindex2 = str.IndexOf(“\“”);
int eindex = eindex2;
if (eindex1 >= 0 && eindex1 < eindex2)
{
eindex = eindex1;
}
return str.Substring(0, eindex);
} private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
if (e.Url.AbsoluteUri == url)
{
AuthrizeCode = GetHiddenKeyValue(this.webBrowser1.DocumentText, “autoInput“);
if (!string.IsNullOrEmpty(AuthrizeCode) && AuthrizeCode.IndexOf(“TOP-“) >= 0)
{
this.DialogResult = DialogResult.OK;
this.Close();
}
}
} private void FrmAuthorized_Load(object sender, EventArgs e)
{
webBrowser1.Navigate(url);
}
}
这 样我们就可以在首次使用API或者SessionKey失效的时候,让商家用户输入账号密码并确认即可,其他使用即可顺利无阻。
是不是有点 意思呢,赶快试试吧,说不定带来一些意想不到的收获及创意哦。
 主要研究技术:代码生成工具、Visio二次开发
主要研究技术:代码生成工具、Visio二次开发[转载]网站测试自动化系统—系统应该有的功能 - Killmyday - 博客园
[转载]网站测试自动化系统—系统应该有的功能 – Killmyday – 博客园.
在前面几篇文章网站测试自动化系统—基于Selenium和VSTT、数据驱动测试、在测试代码中硬编码测试数据里,大概介绍了编写测试代码的过程。然而光把代码写完了是不够的,自动化测试不仅仅是将原本手工执 行的测试用例通过编码的方式自动化。一个完整的自动化测试过程应该包括如下几个过程:
1. 在实验室里面自动选择机器来执行测试过程,比如说为了测试一个软件产品,以Office举例。因为微软已经为Windows发布了很多的版本,Windows XP, Windows Vista, Windows 7等,而每一个版本的Windows还有不同的变种,例如Vista有企业版,旗舰版,专业版等等,每个变种提供的功能有一点的差别。另外,还要考虑在64位和32位操作系 统上安装,还有国际化测试等等。这样一来,为了完全测试Office,测 试矩阵肯定非常大,也许需要测试几百个平台,即使以每个平台需要一台测试机估计的话,也需要几百台机器。如果是纯粹人工来管理这些机器的话,不仅费时费 力,而且出错的几率会很大—比如说你不能找一台32位处理器的机器安装64位的操作系统。因此,一般来说,一个大的软件产品团队都会使用或者自己编写工具来管理测试机。
测试网站 也是一样的,需要考虑到浏览器之间的兼容性,不同测试类型需要不同的测试机器,以及国际化等方面的因素,同样会要求不少的机器执行测试。因为这个软件的制 作涉及到分布式开发的一些理念,所以我不会在这系列的文章里讲解如何实现这种系统。
2. 自动准备测试环境,既然机器已经从测试机集群中挑选出来了,下一步就是准备测试环境,例如重装系统 (当然啦,Ghost还原也行),安装产品所依赖的软件,以及安装最新版 本的产品(每日编译完成以后生成的新版本),将自动化测试用例程序拷贝到测试机,准备测试数据等等。
3. 执行自动化测试用例。这一过程,包括我们通常理解的将需要手工执行的测试用例使用编码的方式使之自动 运行。另外,这一过程还包括一些可选的子过程:
a) 自动生成测试用例所需要的测试数据,生成随机的合法的测试数据不是一件容易的工作。虽然你可以random()之类的函数生成随机数据,但是采用这种简单的方法很难生成合法的数据。比如说,为了测试网站的用户 登录系统,大部分网站都是要求用户名不能包括特殊字符,这样你就需要在随机生成数据的过程中添加一些限制条件。
一般来 说,软件产品在接受用户输入的时候,都会有一些不同的限制条件;因此提供一个生成随机但又合法的测试数据的通用代码库不是一件容易的事情。这也是为什么, 我在这系列文章里面,介绍数据驱动测试的原因。
b) 自动生成自动化测试用例。这一步骤并不是说录制测试步骤,根据测试步骤生成C#或者其他语言的代码。这里说的是,软件自动生成测试用例,并生成对应的自动化测试代码。比如说,单 元测试一般就是根据函数的参数,设计对应的测试用例;在程序中,参数类型一般来说都是有限的,要么就是编程语言自带的固定类型,要么就是程序员自定义的类 型。这样我们是有机会根据参数类型,自动生成测试用例的,微软的Pex就是一个这个领域很好的例子。
又比如, 测试人员可以设计产品的模型,即描述产品应该实现的功能,然后通过特定的软件分析这个模型生成测试用例,微软的Spec Explorer就是这方面的例 子。
再比如, 如果你是在测试一个函数库,例如.NET Framework。一般来 说,用户(程序员)使用函数库的时候无非就是一些API的排列组合。我们 可以先针对每个公开的API设计单元测试代码,然后编写一个程序将这些单 元测试用例随机组合,生成新的测试用例。举个例子,假设要测试数据库连接方面的API,先单独根据Open, ReadData, Close等 函数编写好单元测试用例,然后由程序将这些用例随机排列成一些新的用例。当然,随机排列的问题就是会生成非法的调用序列,比如Close, ReadData, Open这个序列的就是非法的。因此测试用例随机产生程序的一个 很重要的工作就是在测试工程师的配合下,移除掉这些非法的序列。
4. 测试结果收集自动化,因为是同时在多台机器上执行测试用例,要求测试人员手工收集测试结果是一个很麻 烦的过程;所以这一部分由程序自动完成是非常必要的, 一般来说,测试用 例执行完毕以后,自动化测试脚本会将测试结果自动发布到一个中心数据库上。项目管理团队会通过一些报表服务—例如SQL Server Reporting Services等系统来评估以下几个内容:
a) 产品哪些组件的风险比较高,即容易出错或者没有完整地测试过。
b) 产品的健壮程度。
c) 是否可以发布产品,或者延期发布?
这篇文章大致总结 了自动化测试系统应该完成的任务,本来应该当作绪论写的。不过我觉得可能很多人对纯理论的东西不感兴趣,因此将一些实现细节放在前面先写了。
未完待续……
[转载]网站测试自动化系统—执行测试用例 - Killmyday - 博客园
[转载]网站测试自动化系统—执行测试用例 – Killmyday – 博客园.
在前面几篇文章网站测试自动化系统—基于Selenium和VSTT、数据驱动测试、在测试代码中硬编码测试数据里,已经编写了一部分测试用例的代码了。我在文章自动化系统该有的功 能里,也提到了,自动化测试用例代码应该能够被系统自动执行起来。我们总不能要求测试人员每天下班之前 把最新的测试代码下载到自己本机,用VSTS打开,然后选择要批次执行的 测试用例。这种重复机械的劳动是应该要被程序消灭的,毕竟机器的成本要比人工的成本低多了。
首先先分解一下执 行测试用例的步骤,编码实现每一个步骤,然后使用批处理的形式将工作流串起来:(当然啦,我们也可以使用.NET里面的Workflow来实现,只不过那样的话我们需要格外添加一个命令—安装.NET Framework 3.0。)
1. 安装最新版本的产品,在这次测试过程中,由于开发团队没有使用什么自动化每日编译系统,所有的程序员 都是从代码服务器下载最新的代码,在 Visual Studio里面编 写调试网站。所以我们测试团队也是直接下载最新的代码,使用Visual Studio编译产品代码 。
当然啦, 在自动化测试系统里面,不可能要求有一个专人按什么“F5”之类的按钮编 译整个网站的。幸好Visual Studio只是一个集成开发环境(IDE),它编译程序的实际工作是由MSBUILD这个程序完成的,Msbuild这个程序类似于Ant和Make等软件。你只要提供代码的解决方案文件(.sln文件)或者项目文件(.csproj文件),Msbuild自己会根据项目之间的依赖关系编译代码。因此安装最新版本产品的工作就被分解成:
1.1 下载最新的源代码,所有的文件版本服务器的客户端程序都提供了这个功能。我们这个项目使用的是hg,这个命令获取最新的代码:
hg.exe update
1.2 编译代码:
Msbuild /nologo productcode.sln
1.3 发布编译好的网站,或者使用xcopy命令更新网站文件夹,或者在IIS里面将网站的根目录直接指向产品代码的文件夹。
2. 下载并且编译最新的测试代码,这个步骤跟第1步类似,所以就省略相关命令了。
3. 运行所有的自动化测试用例。VSTT提供了一个叫做用例列表(Test List)的功能,因为是SCRUM的第一个Spring,所以我们在工作时,将所有自动化好了的 测试用例都归档到一个叫做Automation的用例列表(Test List)里。
当自动化 测试工程师在VSTT批量执行测试用例的时候,通常的步骤是通过执行下面 这些步骤实现的:
a) 在VSTT里面打开 测试工程文件。
b) 点击Visual studio菜单里的“测试(Test)”—> “窗口(Windows)”—> “Test List Editor”。
c) 展开“Lists of Tests”,勾上“Automation”这个用例列表(Test List),这样就选择了所有自 动化的测试用例。如下图所示:
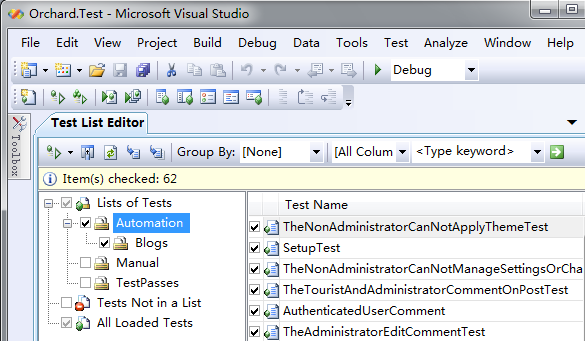
d) 最后点击Visual studio菜单里的“测试(Test)”—> “运行(Run)”—> “Tests in Current Context”,就可以运行所有的用例了。
前面已 经讲到过,Visual Studio只不过是一个集成开发环境,基本上 所有界面上的操作都可以使用命令行工具完成,例如编译程序可以使用msbuild.exe,调试程序可以使用mdbg.exe(当然Visual Studio的调试器是窗体程序,不是命令行程序),执行测试用例是通过Mstest.exe完成的。上面a,b,c,d四个步骤,可以使用下面这个命令实现:
mstest /runconfig:TestRunConfig.testrunconfig /testmetadata:Test.vsmdi /testlist:Automation /resultsfile: \TestResults\%SELENIUMHOST%_%ORCHARDSERVICE%_%1.trx
下表列 出了上面的命令里使用的参数的意义。
|
参数名 |
说明 |
|
Runconfig |
当你在Visual Studio里创建了一个测试工程(Test Project),VS会自动在你的项目解决方案添加一个.testrunconfig文件。这个文件是用来配置执行一遍测试过程(Test Run)所需要准备的环境的。例如:
l 测试用例是在本机执行,还是在其他机器上执行。 l 要拷贝的测试数据。 l 在所有测试用例执行前后要运行的命令—用来准备测试环境。 l 是否要进行代码覆盖率统计。 l 等等。
使用.testrunconfig的过程我会在后面讲到。 |
|
Testmetadata |
VS除了添加一个.testurnconfig文件以外,它还会添加一个叫做测试用例元数据(test meta data)的.vsmdi文件。这个文件嘛,就像是所有元数据所标榜的那样,用来描述测试用例的信息。例如测试用例属于哪一个用例列表(test list)啦,测试用例的负责人(Owner)是谁啦等等。
.vsmdi文件的详细信息我也会在后面的文章中讲解。 |
|
testlist |
用例列表,通过这个参数,可以指定要执行的测试用例列表,用例列表是一个树形结构,即用例列表可以包含其他用例列表,具体的示例请看上 图。 |
|
resultsfile |
测试用例执行完毕以后,测试结果文件保存的位置。 |
备注:mstest.exe的其他参数请参考MSDN文档:
http://msdn.microsoft.com/zh-cn/library/ms182489%28VS.80%29.aspx
4. 收集测试结果,这一步骤的详细描述放在下一篇文章中讲解。
既然已经知道替代 每一个步骤所使用的命令,剩下的工作,无非就是用PowerShell, 或者WMI,或者批处理将这些命令结合起来运行罢了。
未完待续……
[转载]ASP.NET Web Game 构架设计3--业务逻辑服务器之计时器
[转载]ASP.NET Web Game 构架设计3–业务逻辑服务器之计时器 – warensoft专注于.NET – 博客园.
ASP.NET Web Game 构架设计3—业务逻辑服务器之计时器
业务逻辑服务器里主要包括以下四个模块
u 计时服务器
u 资源服务器
u 其他逻辑服务
u 对外的WCF接口模块/Socket接口模块
1. 计时服务器
计 时服务器的作用是给需要长耗时的功能提供一个延时管理模块,比较典型的应用如“种 菜”的计时, 武将升级的计时,科技升级的计时,建筑升级的计时等。计时服务器主要由四个元素组成:
u 用于保存计时队列的数据表
u 添加计时的函数接口
u 删除计时的函数接口
u 用于加速的函数接口
u 定时机制
u 可以动态扩展的计时过期处理程序
用于保存计时队列的数据表
先 来说一下存储结构,计时的存储大体上有两种方案:1.基 于内存;2.基于数据库。首 先要说明的,从经验角度出发,本人更青睐于第二个方案。下面对这两个存储方案进行评比:
基于内存的优点:
操 作速度快
基于内存的缺点:
如 果服务器停电,所有用户的队列数据将全部消失!(客服的灾难)
基于数据库的优点:
不 怕服务器掉电,只要服务程序启动,就可以处理过期的队列
基于数据库的缺点:
读 取数据的速度较慢,
基 于上面的比较,以及我的基 本原则—“不让客服的电话被打爆!”, 得到的结论就是:使用数据库来存储计时队列。计时队列的表结构如下图所示:
我 们可以看到,计时队列的存储,是由两张表来实现的,一张主表(PrimaryQueue), 一张辅表(SecondaryQueue)。
每 一次添加一个新计时队列的时候,我们要先在PrimaryQueue中 添加一条记录,在该记录里要包括,这个队列什么时候开始,多长时间结束,以及非常重要的队列类型名。读者会对两件事儿产生疑问:1.为 什么记录的是时长,而不是结束时间。答案是:为了方便计时的加速操作,为了方便界面上的倒计时显示。2.队 列类型名(QueueTypeName) 字段是干什么的。答案是:每一个队列都要有一个标记,该标记通过字符串形式告诉应用程序,当该队列过期后,应该找哪个函数,或者哪个类来处理相关数据。
仅 仅在PrimaryQueue中 添加一条记录是不够的,因为我们还不知道当这个队列过期后,有哪些要处理的数 据是相关的,为此我们还要在Secondary表 中添加对应的记录,PrimaryQueueID是 外部键,当然在SecondaryQueue中 最重要的是ForeignID字 段,该字段存储的是相关逻辑表中,和本队列有关的那条记录的ID, 根据此ForeignID, 我们可以在对应的计时过期处理程序中对相关记录做处理(这儿说的很别扭,当然也不太好表达,请读者注意理解!)。
呵 呵,看到这里,很多读者又会产生一个疑问,为什么要两张表,上面说的那点儿事儿,一个表不就搞定了吗?答案是:一个表是搞不定的,因为在很多情况下,在一 个队列里,可能处理的是多个元素的计时,这个时候可能会出现的情况是,在PrimaryQueue中 有一个记录,表示是一条队列,并且这个队列中的数据要作的事儿都一样,开始时间也一样,过期时间也一样, 在SecondaryQueue里 对应的是本次队列的多个计时元素。举例说明,在 用户的一次操作中要为该基地建造5只 船,因为每只船都有自己独立的状态,所以每只船的数据都存储在基地表和船只列表的关系表中(每只船一条记录),此时, 我们的队列表中的数据是:有一条记录在PrimaryQueue中, 记录着这些操作的开始时间以及时长,另外,对应主表中这个新的队列,在SecondaryQueue表 中会存在5条子记录,每个记录的ForeignID字 段的值就是每一只船的ID(基地表和船只列表的关系表的ID)。 现在应该明白使用两个表的原因了吧!
添加计时的函数接口以 及删除计时函数接口
这 两个功能相对来讲是比较简单的,无非就是将数据添加到数据表中,以及从数据表中删除。
用于加速的函数接口
加 速的函数接口,主要实现两点功能:1.直 接将加速的时间从TimeLengthSeconds字 段上减下去;2.计费作用,因为一般的游戏中,加速是要收费 的,这时候,在加速之前就要检测用户费用是否充足,在加速完毕后,将相应的费用扣除到。
定时机制
我 们如何才能知道哪些数据已经过期了呢?这时我们需要利用Thread编 写一个Timer,这个Timer每 间隔一定时长就Sleep一次(比如60秒), 每一次Timer启动时,就去找出已经过期的队列(now-StartTime>TimeLength),并 将其中的记录按QueueTypeName字 段的值进行分类(即:功能相同的计时放到一组),然后将每一类记录的集合都提交到ThreadPool中 进行异步处理,基本代码如下所示:
var queueTable = Monitor.GetExpiredQueuesTable();
var groups = queueTable.AsEnumerable().GroupBy(row => row[“QueueTypeName“]);
foreach (var item in groups)
{
ThreadPool.QueueUserWorkItem(obj =>
{
IGrouping<object, DataRow> items = (IGrouping<object, DataRow>)obj;
foreach (var row in items)
{
//deal with the row
}
},item);
}
可以动态扩展的计时过期处理程序
前 面我们已经将过期的队列取出来,并对其进行了分类,那么我们如何对每一类队列中的记录进行处理呢?另外,随着应用程序规模的不断扩大,处理程序的数量也不 会断增加,那么,我们又应当如何保证处理程序的可扩展性呢?
其 实,我们可以很容易发现,不同的处理程序中的函数的名称和参数列表应 该是一样的,只不过是该函数所处的文件或者类不同,并且逻辑不同而 已。大家会问题,为什么不同的处理程序的函数名和参数列表也要相同呢?其实想法也很简单,因为我 们需要通过一个统一的调用接口实现函数调用过程。
为 了达到可扩展并且方便修改的的目,我的处理程序可以利用IronPython脚 本来实现,使用脚本语言来实现一些逻辑是游戏编程中常常用到的(当然用C#写 成DLL,并动态加载也可以)。我们要做的 是,在应用程序所在的目录中添加一个处理程序的脚本目录,在这个脚本目录中添加若干个IronPython脚 本,每个脚本的文件名应该对应着每一类队列的分类名(QueueTypeName), 在这些脚本中都提供一个名称相同,而逻辑不同的函数,在队列服务程序加载的时候,可以建立一个Dictionary, 应用程序可以去扫描脚本目录,并将脚本名以及脚本中的函数以键值对的形式添加到Dictionary中。 发现已过期的队列后,就可以根据队列所处的分类名,在Dictionary中 查找相应的函数并调用即可。
使 用脚本的好处:语法简单;可以直接修改脚本文件并保存,不用重新编译;处理程序经常会出现Bug, 并且处理程序的需求会经常发生改变,写成脚本方便修改;当添加了新的处理程序时,也不用重新编译服务器代码,只要重新Load一 次脚本就可以实现计时服务的可扩展性了。
使 用脚本语言的速度如何?速度肯定会慢一点点,但是你绝对感觉不出来!
总 结,根据上面的描述,我们可以得到一个流程图,如下所示:
今 天先聊到这儿,下次我们要谈一下资源服务的实现,有问题或需要技术支援,请给我发Email:warensoft@foxmail.com
[转载]ASP.NET Web Game 构架设计2--数据库设计
[转载]ASP.NET Web Game 构架设计2–数据库设计 – warensoft专注于.NET – 博客园.
前一篇Blog对WebGame服 务器的物理结构做了一个简要说明,下面我们对各个组成元素进行详细说明。
首先来看一下数据库设计。
游戏的数据库设计是项目基础设计中很重要的一个环节,下面将说明以下几个要点:
u 为什么选用SQLServer
u 基本原则
u 表关系的设置
u 数据的冗余设计
u 什么时候使用存储过程
u 什么时候使用EntityFramework什么时候使用ADO.NET
1. 为什么先用SQL Server
首 先,不要对SQL Server的 性能表示怀疑。作为WebGame应 用来讲,它的吞吐能力,承载能力完全够用。
第 二,如果服务代码是使用C#来编写的,那么SQL Server2005/2008能得到最好的C#/Visual Studio兼容性。最重要的是C#中 很多组件都是为SQL Server设 计的,并且做了很多优化,例如:EntityFramework,SQL CLR等。
第 三,SQL Server中 支持SQL CLR功能,即可以使用C#/VB.NET来 编写自定义函数,存储过程等,对于熟悉C#的 开发人员来讲是一个福音,不仅仅是代码编写规则熟悉,而且可以使用一部分.NET类 库来实现想要的功能,比如说基本.NET类 型,数学运算,WCF等功能。
第 四,可能很多人都觉得使用SQL CLR是 因为T-SQL用的不精,其实不然,SQL CLR实际上是利用C#写 好DLL文件,然后被SQL Server调用,本质上利用了.NET来 提高SQL Server的 性能,在某些情况下SQL CLR的 效率要高于T-SQL。
2. 基本原则
在 设计游戏数据库时千万别怕表多,在一个常规的网页游戏中,数据表的数量应该大于150。 因为一个游戏项目,细分起来,是由少则10几 个,多则几十个子系统组织起来的,每个系统都有若干张表来辅助存储。
另 外,游戏系统的数据库可以按状态分为:配置数据存储表(如基本数值配置),状态数据存储表(如计时),以及数据极不稳定的用来表示某个物件所属的中间关系 数据表(如某个用户招募了某一个军官)。总之,要事无巨细,将90%的 数据以数据库的形式存储起来。这么作的原因在于,游戏中很多的数据都是敏感数据,如金币,某个物件的数量等,如果将过多的数据存储于内存中,一旦服务掉 电,丢失的数据将无法挽回,客服的电话会被打爆的。
当 然,如果将大多数数据存储在数据库,反复读写所带来速度问题,也是不可以忽略的,解决方法如下:
u 客户端在加载的时候,就把常用的只读配置数据存储到客户端。
u 客户端要修改数据时,先修改客户端的数据,然后立即显示出来,最后再异步调用服务器的接口,去修改数据。
u 如果客户端一定要等待服务器的处理结果,那么就直接利用异步方式调用服务器接口,但是一定要给用户提示,防止误操作的产生。
u 服务器一定要将常用的数值计算的操作数和结果储存在内存中,以提高响应速度,例如:游戏中常常用到Pow函数,那就在内存中建立一个Pow的函数值表,每次调用时,就直接从表中取出来。
3. 表关系的设计
一 个游戏中会存在很多个子系统,如:用户系统、道具系统、商城系统、社交系统、邮件系统、武将系统、建筑系统、资源系统、计时系统等,除了计时系统比较独 立,其他系统大多数都要用户系统以及用户相关的家系统(基地,城池等)相关联,这样复杂的结构如何设计呢?
首 先,一定要把握住ER的思想,哪些是实体表,哪些是关系表,实体 和实体之间一定要通过关系相联,最好不出现直接的主表–子表关系。 同时,在各个关系中一定不要使用级联操作(级联更新,级联删除), 当然,这个约束在表关联比较多的时候就会自动加入。之所以要不存在“主表–子 表”关系以及级联操作,是因为整个游戏系统就是一个小型的社会,一旦存在级联,很容易产生“雪崩”效应,修改或删除顶级表的某一条数据中,就有可能影响到N多 个子表,这种影响是的复杂程度是程序员根本无法控制的。比较合理的作法是如果要修改或删除某一个数据,就要从关联关系中的最底层表作起,手动的逐级向上进 行修改或删除。表面上看起来会比较麻烦,但是这种作法带来的好处也是显而易见的,手动控制,可以明确到底哪些数据该删除,哪些数据不该删除(有很多数据是 要用来做统计的,是不能删除的),同时,在这些数据表之间进行导航,可以让程序更清楚数据的存储结构,更清楚自己在做什么。
4. 数据的冗余设计
在 设计数据库时千万别想着什么精简字段,减少冗余,通过关系查找等所谓的优化手段,经过失败经验的证明,数据库设计的冗余越少,精简度越高,在数据查找时的 速度就会越慢,代码的复杂度就会越高。
下 面以常见的武将系统为例说明如何通过冗余设计来提高系统性能。
首 先,我们来明确一下基本功能。武将系统中一定会存在三张有关系的表,一,是可选武将的列表,这个表是一张配置表;二,用户表;三,是用户所招募到的武将 表。比较精简表结构如下所示:
对 于关系表UserOwnedMilitaryOfficers来 讲,只需要存储对应的武将ID即可,如果想知道这个武将的详细信息,可以 通过关系进行想找,此种情况的EntityFramework查 询如下所示:
testModel.testEntities2 context = new testModel.testEntities2();
var myuid=“warensoft”;
var myMilitaryOfficers = context.UserOwnedMilitaryOfficers.
Where(mo => mo.Users.uid == myuid).
Select(mo => new
{
Name=mo.MilitaryOfficers .Name ,
Life=mo.MilitaryOfficers .Life ,
Exp=mo.MilitaryOfficers .Exp
});
//do something else…
不 难发现,上面代码中的查询是由两个函数组成的,首先要根据用户的ID找 到所有该用户所拥有的武将ID(使用Where函 数),然后,根据所找到的武将ID, 再反过来到武将表中找到对应的名字(Select函 数),生命以及初始经验。特点:两个函数查询,访问了两张表。
如 果我们在UserOwnedMilitaryOfficers表 中添加一些冗余数据的话,虽然存储量会增加,但是控制难度会大大下降,对该表进行修改,如下所示:
修 改后的关系表,是将一些冗余数据加了进来,对于这样的关系结构来讲,查询语句如下所示:
testModel.testEntities2 context = new testModel.testEntities2();
var myuid=“warensoft”;
var myMilitaryOfficers = context.UserOwnedMilitaryOfficers.
Where(mo => mo.Users.uid == myuid).
Select(mo => new
{
Name=mo .Name ,
Life=mo .Life ,
Exp=mo .Exp
});
//do something else…
对 于新版本的查询代码来讲,首先,从关系表中找到该用户所拥有的武将,这一点是不变的,但是在执行Select函 数的时候确不用再通过关系查找武将到,而直接对已经选出的数据进行组织,取出想到的字段而已。特点:两个函 数,一次查询。这种修改仅仅是添加了一些冗余,但是查询次数却减少了50%。
5. 什么时候使用存储过程
存 储过程的使用是需要仔细考虑的,我们不应该走极端(要么所有数据访问逻辑都使用存储过程,要么所有数据访问逻辑都不使用存储过程),原则上来讲,是否使用 存储过程,取决于这个功能的调用密集程度和数据访问的密集程度。
如 果某一个功能的非数据访问逻辑很多又会被很频繁地调用,将这个功能写成存储过程的话,会导致SQL Server占用较多的资源,这 样作并没有真正的利用好SQL Server, 同时还会影响其他数据访问操作的执行。在遇到这种情况时,应该考虑使用EntityFramework和ADO.NET, 可以在应用程序中通过SQL语句对数据库进行外部调用。
如 果一个操作中,大部分的功能是访问各个表,并添加修改删除数据,其他的非数据访问逻辑很少,那么将这个功能写成存储过程,就是比较合理的,因为这样会大大 减少SQL语句在应用程序和数据库之间的传递次数。
6. 什么时候使用EntityFramework, 什么时候使用ADO.NET
首 先,要说明的是绝对不要对EntityFramework的 性能有所怀疑,经验证明,在大多数情况下EntityFramework的 性能都与ADO.NET不相上下。
使用EntityFramework的优点:
EntityFramework使 用类之间的关系进行导航,这样可以不去编写大量的级联SQL, 以操作类的形式代替了字符串形式的SQL操 作,我们的开发效率以及编码的正确率都会有大幅度的提高。
使用EntityFramework的缺点:
当 然使用EF也有不少问题,比如说,在指定的数据表中作 大量记录的相同修改,或者指删除,如果使用EF就 要先遍历一次所有的记录,然后再保存,最后SQL Server再 执行操作,数据里一大,数据的同步就存在问题。同时EF对 存储过程的调用也不方便。
使用ADO.NET的优点:
万 能的操作!没有什么数据库操作功能是ADO.NET作 不了的,而且操作起来更为灵活,速度也非常快。EF的 底层实现也大量的使用ADO.NET。
使用ADO.NET的缺点:
显 而易见,使用ADO.NET,是要直接编写SQL语 句的,SQL语句是通过字符串体现的,没有智能感知,没 有语法检测,只有在运行时才能知道正确与否,这样的开发效率比较低。另外,ADO.NET是 较为底层的数据访问技术,在业务逻辑比较复杂的情况下,开发难度(事务控制,同步控制)比较高。
组合比例:
通 过已有经验,我们发现在60%的逻辑中使用EntityFramework, 另外20%的逻辑使用ADO.NET, 还有20%的逻辑是利用ADO.NET编 写的SQL CLR代码,这样的比例也许会比较合适(当然这 样的比例也要和具体的需要相匹配)。
今 天就写到这儿,如何大家需要技术支援,请给我发Email:warensoft@foxmail.com