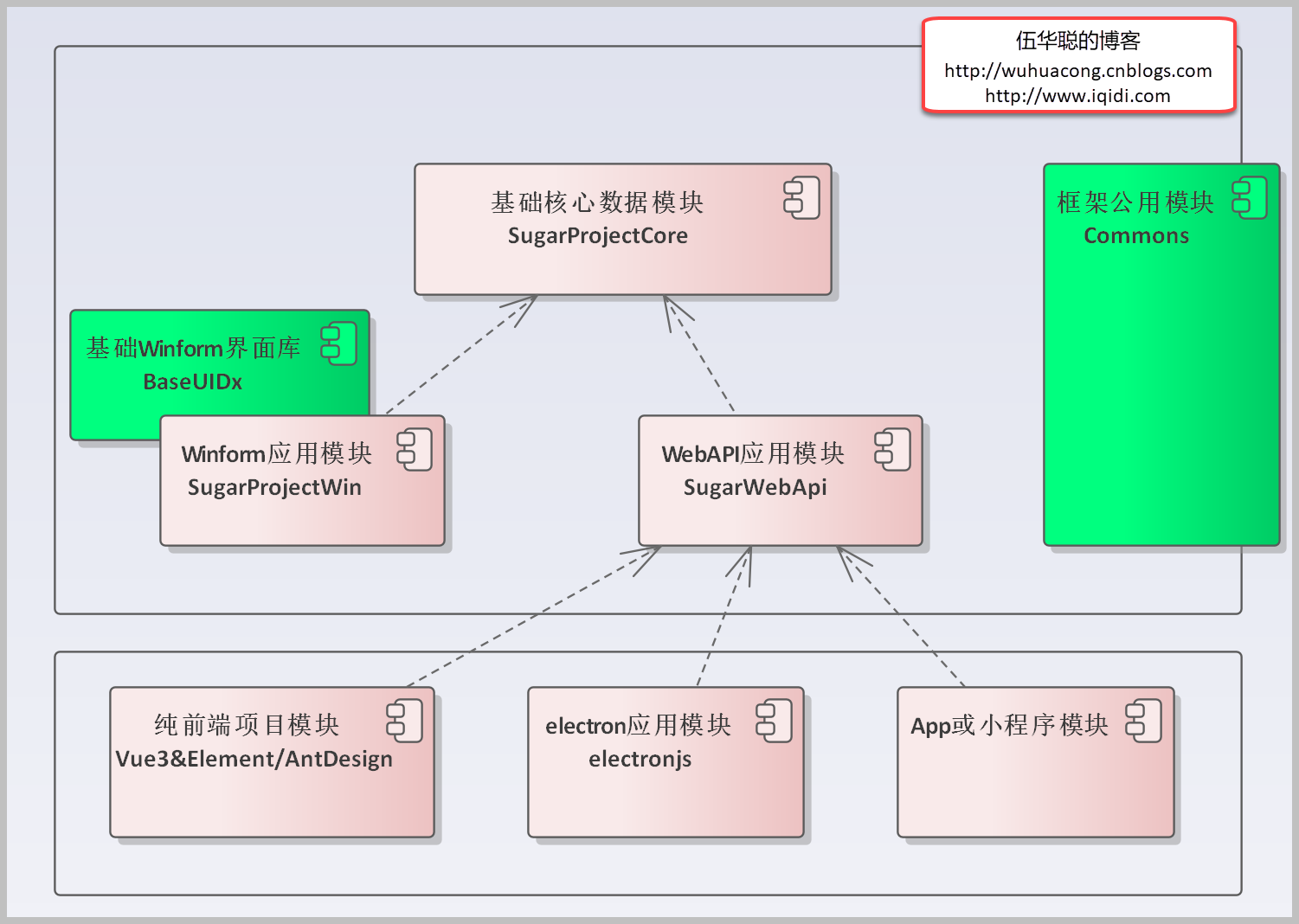
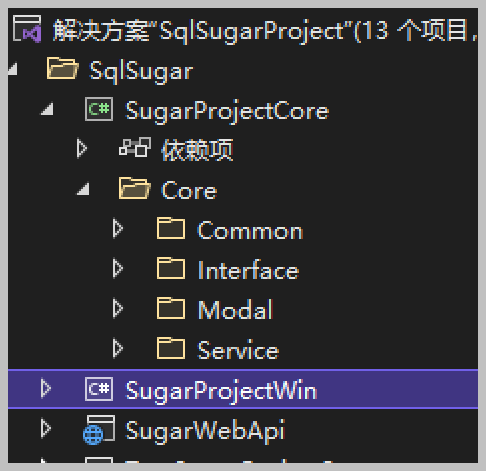
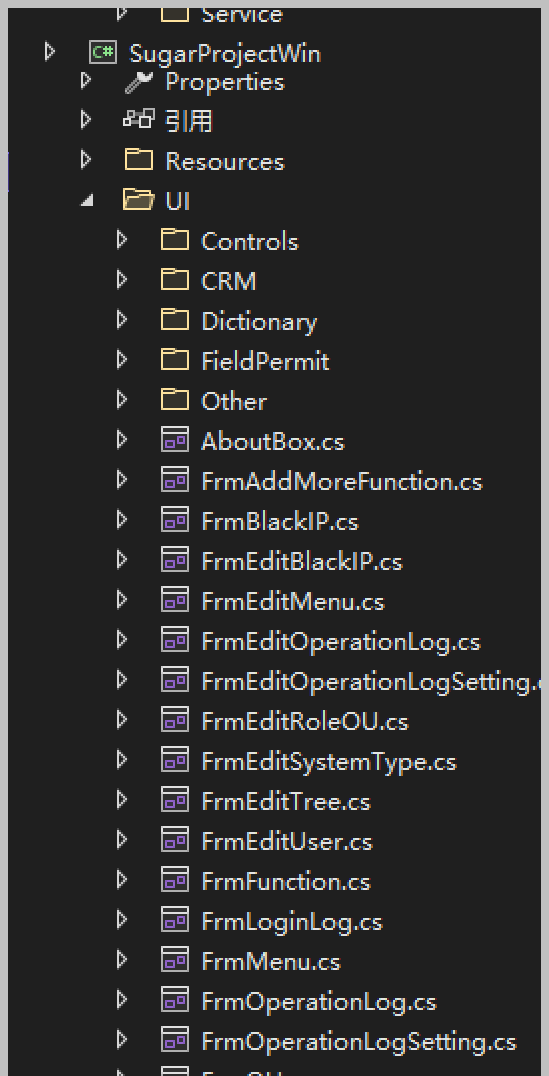
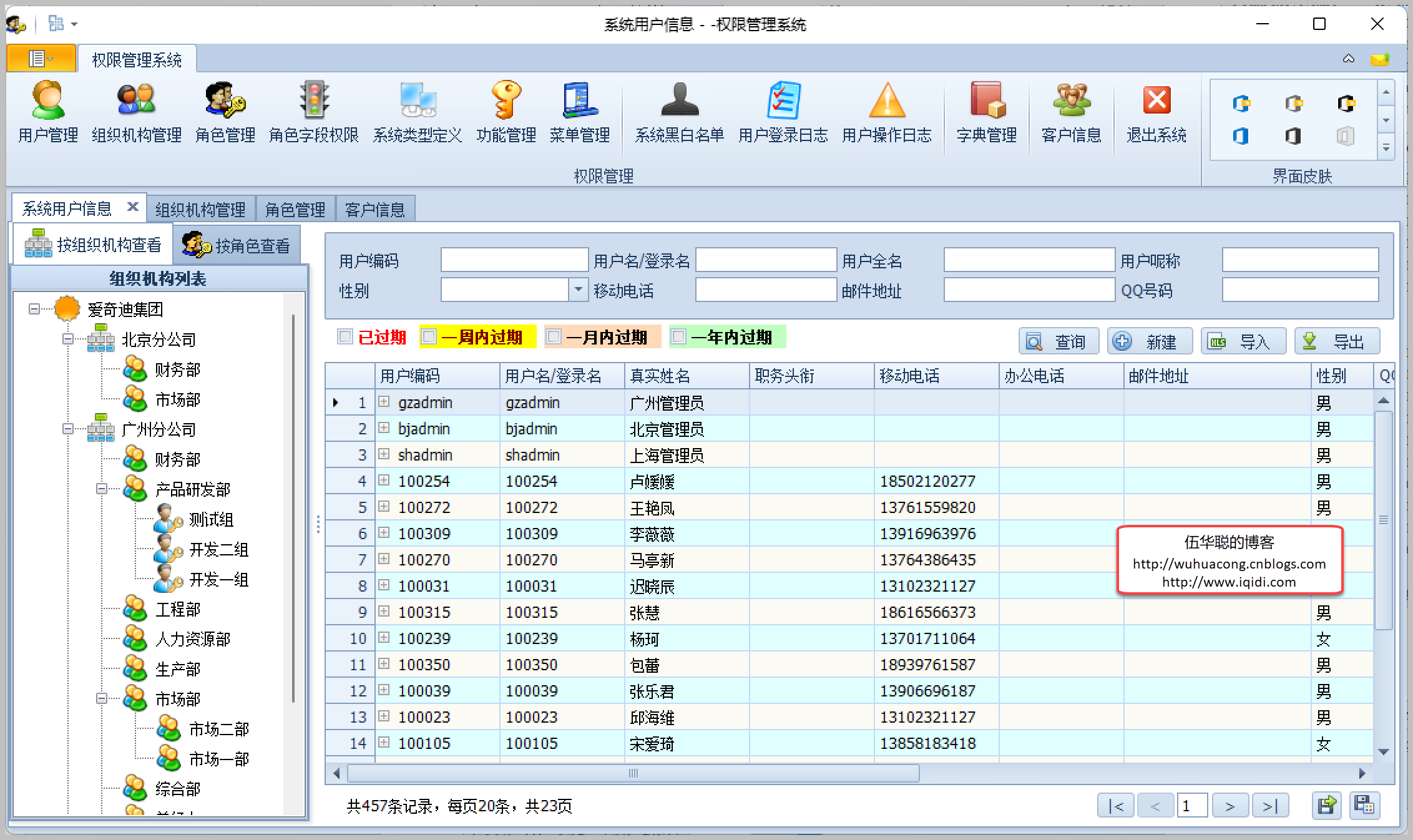
USE [YourSQLDba]
GO
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[Maint].[sp_who_blocking]') AND type in (N'P', N'PC'))
DROP PROCEDURE [Maint].[sp_who_blocking]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
--==================================================================================================================
-- ProcedureName : [Maint].[sp_who_blocking]
-- Author : Kerry http://www.cnblogs.com/kerrycode/
-- CreateDate : 2014-04-23
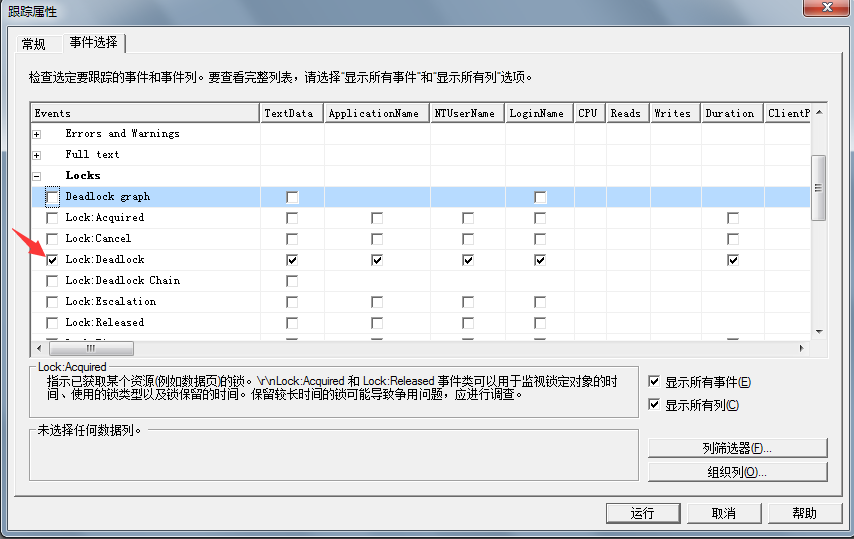
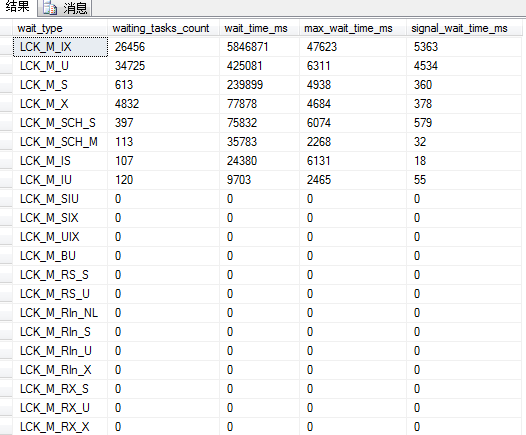
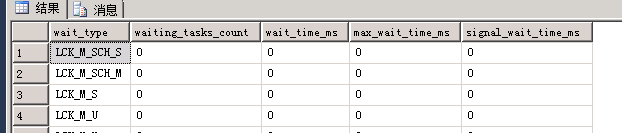
-- Description : 监控数据库阻塞情况,显示阻塞会话信息或收集阻塞会话信息或发送告警邮件
/******************************************************************************************************************
Parameters : 参数说明
********************************************************************************************************************
@OutType : 默认为输出阻塞会话信息,"Table", "Email"分别表示将阻塞信息写入表或邮件发送
@EmailSubject : 邮件主题.默认为Sql Blocking Alert,一般指定,例如“ServerName Sql Blocking Alert"
@ProfileName : @profile_name 默认值为YourSQLDba_EmailProfile
@RecipientsLst : 收件人列表
********************************************************************************************************************
Modified Date Modified User Version Modified Reason
********************************************************************************************************************
2014-04-23 Kerry V01.00.00 新建存储过程[Maint].[sp_who_blocking]
*******************************************************************************************************************/
--==================================================================================================================
CREATE PROCEDURE [Maint].[sp_who_blocking]
(
@OutType
VARCHAR(8) ='Default' ,
@EmailSubject
VARCHAR(120)='Sql Blocking Alert' ,
@ProfileName
sysname='YourSQLDba_EmailProfile' ,
@RecipientsLst
VARCHAR(MAX) = NULL
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @HtmlContent NVARCHAR(MAX) ;
IF @OutType NOT IN ('Default', 'Table','Email')
BEGIN
PRINT 'The parameter @OutType is not correct,please check it';
return;
END
IF @OutType ='Default'
BEGIN
SELECT db.name AS DatabaseName
,wt.blocking_session_id AS BlockingSessesionId
,sp.program_name AS ProgramName
,COALESCE(sp.LOGINAME, sp.nt_username) AS UserName
,ec1.client_net_address AS ClientIpAddress
,wt.wait_type AS WaitType
,ec1.connect_time AS BlockingStartTime
,wt.WAIT_DURATION_MS/1000 AS WaitDuration
,ec1.session_id AS BlockedSessionId
,h1.TEXT AS BlockedSQLText
,h2.TEXT AS BlockingSQLText
FROM sys.dm_tran_locks AS tl
INNER JOIN sys.databases db
ON db.database_id = tl.resource_database_id
INNER JOIN sys.dm_os_waiting_tasks AS wt
ON tl.lock_owner_address = wt.resource_address
INNER JOIN sys.dm_exec_connections ec1
ON ec1.session_id = tl.request_session_id
INNER JOIN sys.dm_exec_connections ec2
ON ec2.session_id = wt.blocking_session_id
LEFT OUTER JOIN master.dbo.sysprocesses sp
ON SP.spid = wt.blocking_session_id
CROSS APPLY sys.dm_exec_sql_text(ec1.most_recent_sql_handle) AS h1
CROSS APPLY sys.dm_exec_sql_text(ec2.most_recent_sql_handle) AS h2;
END
ELSE IF @OutType='Table'
BEGIN
INSERT INTO [Maint].[BlockingSQLHistory]
SELECT GETDATE() AS RecordTime
,db.name AS DatabaseName
,wt.blocking_session_id AS BlockingSessesionId
,sp.program_name AS ProgramName
,COALESCE(sp.LOGINAME, sp.nt_username) AS UserName
,ec1.client_net_address AS ClientIpAddress
,wt.wait_type AS WaitType
,ec1.connect_time AS BlockingStartTime
,wt.WAIT_DURATION_MS/1000 AS WaitDuration
,ec1.session_id AS BlockedSessionId
,h1.TEXT AS BlockedSQLText
,h2.TEXT AS BlockingSQLText
FROM sys.dm_tran_locks AS tl
INNER JOIN sys.databases db
ON db.database_id = tl.resource_database_id
INNER JOIN sys.dm_os_waiting_tasks AS wt
ON tl.lock_owner_address = wt.resource_address
INNER JOIN sys.dm_exec_connections ec1
ON ec1.session_id = tl.request_session_id
INNER JOIN sys.dm_exec_connections ec2
ON ec2.session_id = wt.blocking_session_id
LEFT OUTER JOIN master.dbo.sysprocesses sp
ON SP.spid = wt.blocking_session_id
CROSS APPLY sys.dm_exec_sql_text(ec1.most_recent_sql_handle) AS h1
CROSS APPLY sys.dm_exec_sql_text(ec2.most_recent_sql_handle) AS h2;
END
ELSE IF @OutType='Email'
BEGIN
SET @HtmlContent =
N'<head>'
+ N'<style type="text/css">h2, body {font-family: Arial, verdana;} table{font-size:11px; border-collapse:collapse;} td{background-color:#F1F1F1; border:1px solid black; padding:3px;} th{background-color:#99CCFF;}</style>'
+ N'<table border="1">'
+ N'<tr>
<th>DatabaseName</th>
<th>BlockingSessesionId</th>
<th>ProgramName</th>
<th>UserName</th>
<th>ClientIpAddress</th>
<th>WaitType</th>
<th>BlockingStartTime</th>
<th>WaitDuration</th>
<th>BlockedSessionId</th>
<th>BlockedSQLText</th>
<th>BlockingSQLText</th>
</tr>' +
CAST (
(SELECT db.name AS TD, ''
,wt.blocking_session_id AS TD, ''
,sp.program_name AS TD, ''
,COALESCE(sp.LOGINAME, sp.nt_username) AS TD, ''
,ec1.client_net_address AS TD, ''
,wt.wait_type AS TD, ''
,ec1.connect_time AS TD, ''
,wt.WAIT_DURATION_MS/1000 AS TD, ''
,ec1.session_id AS TD, ''
,h1.TEXT AS TD, ''
,h2.TEXT AS TD, ''
FROM sys.dm_tran_locks AS tl
INNER JOIN sys.databases db
ON db.database_id = tl.resource_database_id
INNER JOIN sys.dm_os_waiting_tasks AS wt
ON tl.lock_owner_address = wt.resource_address
INNER JOIN sys.dm_exec_connections ec1
ON ec1.session_id = tl.request_session_id
INNER JOIN sys.dm_exec_connections ec2
ON ec2.session_id = wt.blocking_session_id
LEFT OUTER JOIN master.dbo.sysprocesses sp
ON SP.spid = wt.blocking_session_id
CROSS APPLY sys.dm_exec_sql_text(ec1.most_recent_sql_handle) AS h1
CROSS APPLY sys.dm_exec_sql_text(ec2.most_recent_sql_handle) AS h2
FOR XML PATH('tr'), TYPE
) AS NVARCHAR(MAX) ) +
N'</table>'
IF @HtmlContent IS NOT NULL
BEGIN
EXEC msdb.dbo.sp_send_dbmail
@profile_name = @ProfileName ,
@recipients = @RecipientsLst ,
@subject = @EmailSubject ,
@body = @HtmlContent ,
@body_format = 'HTML' ;
END
END
END
GO












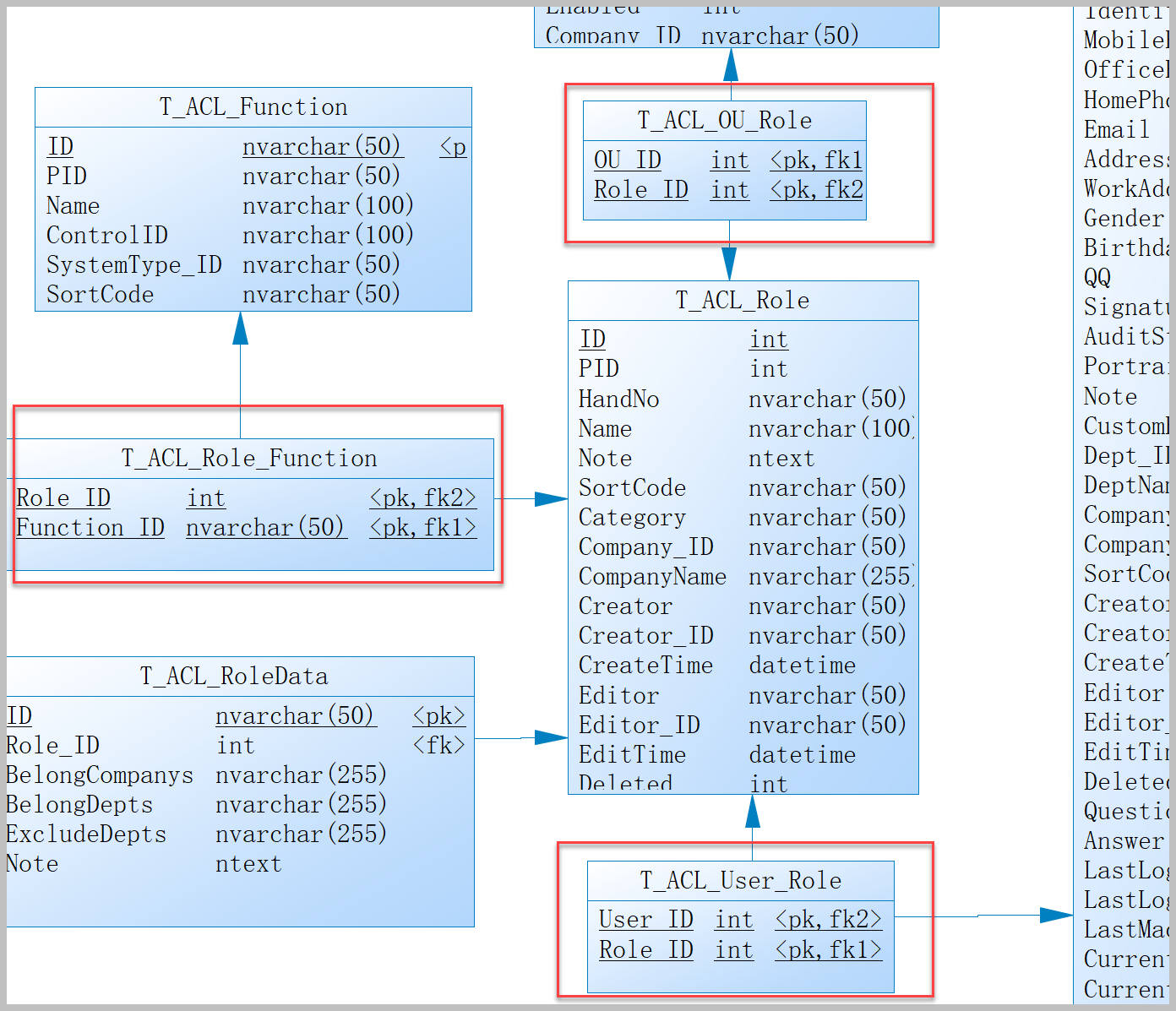
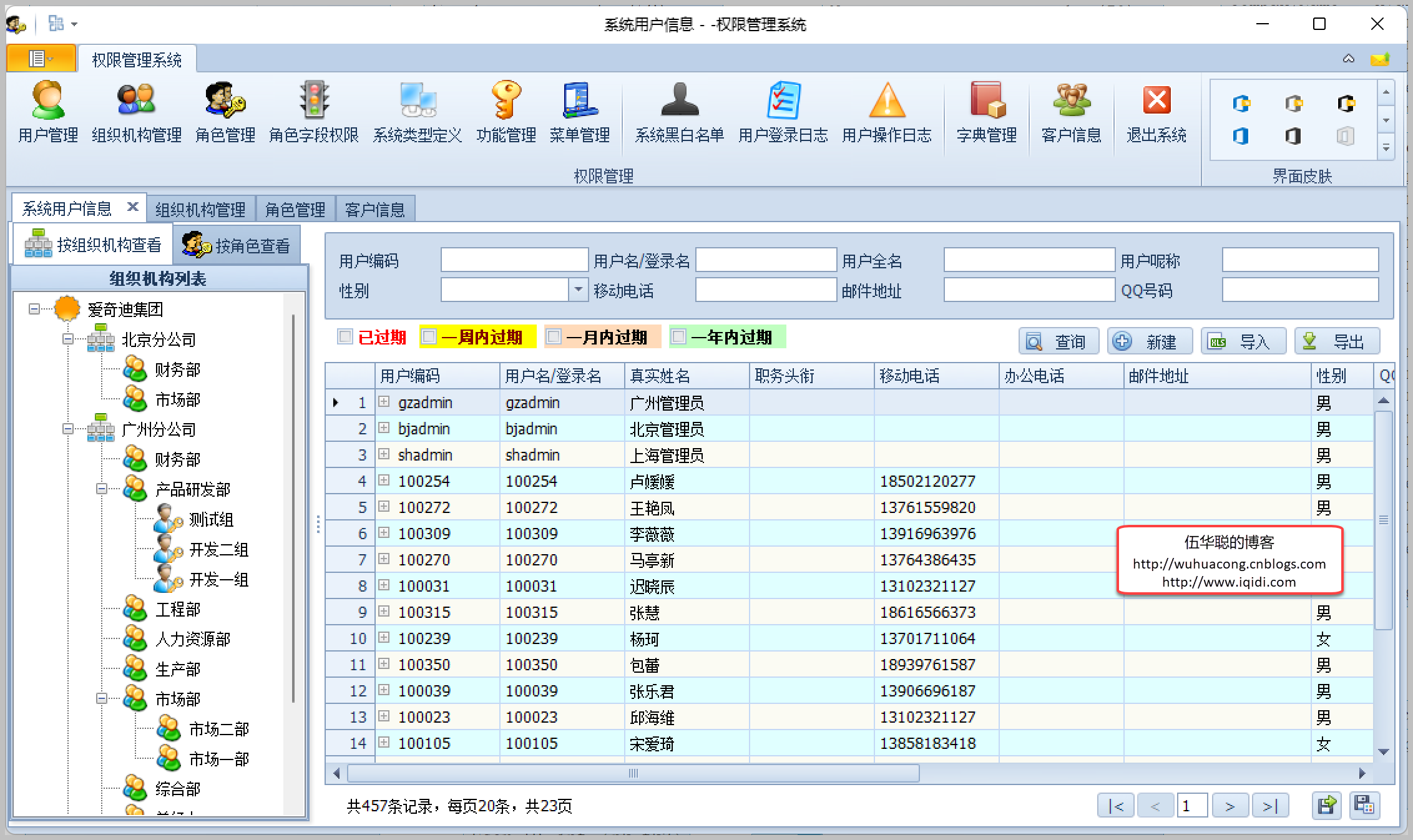
 主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发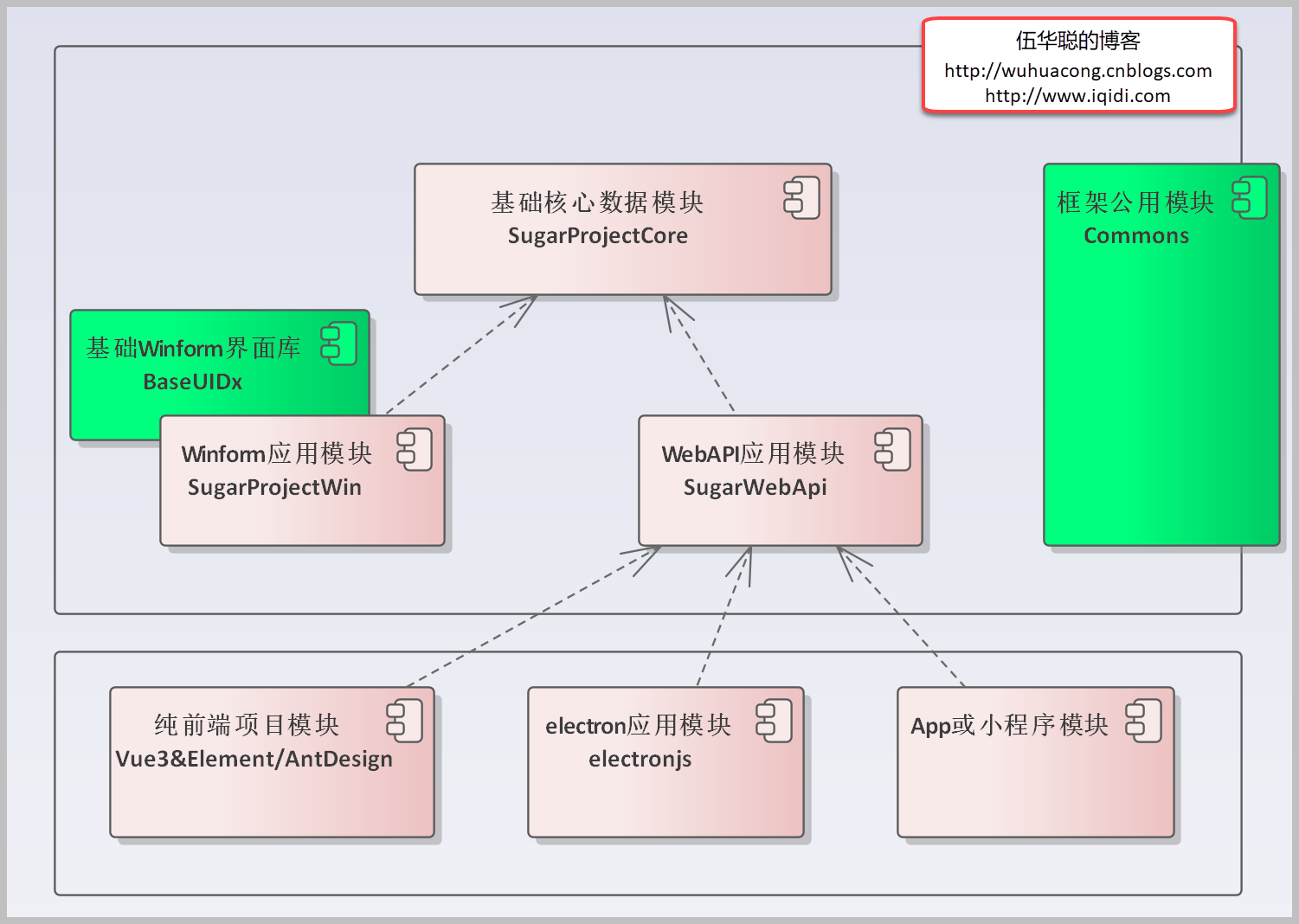

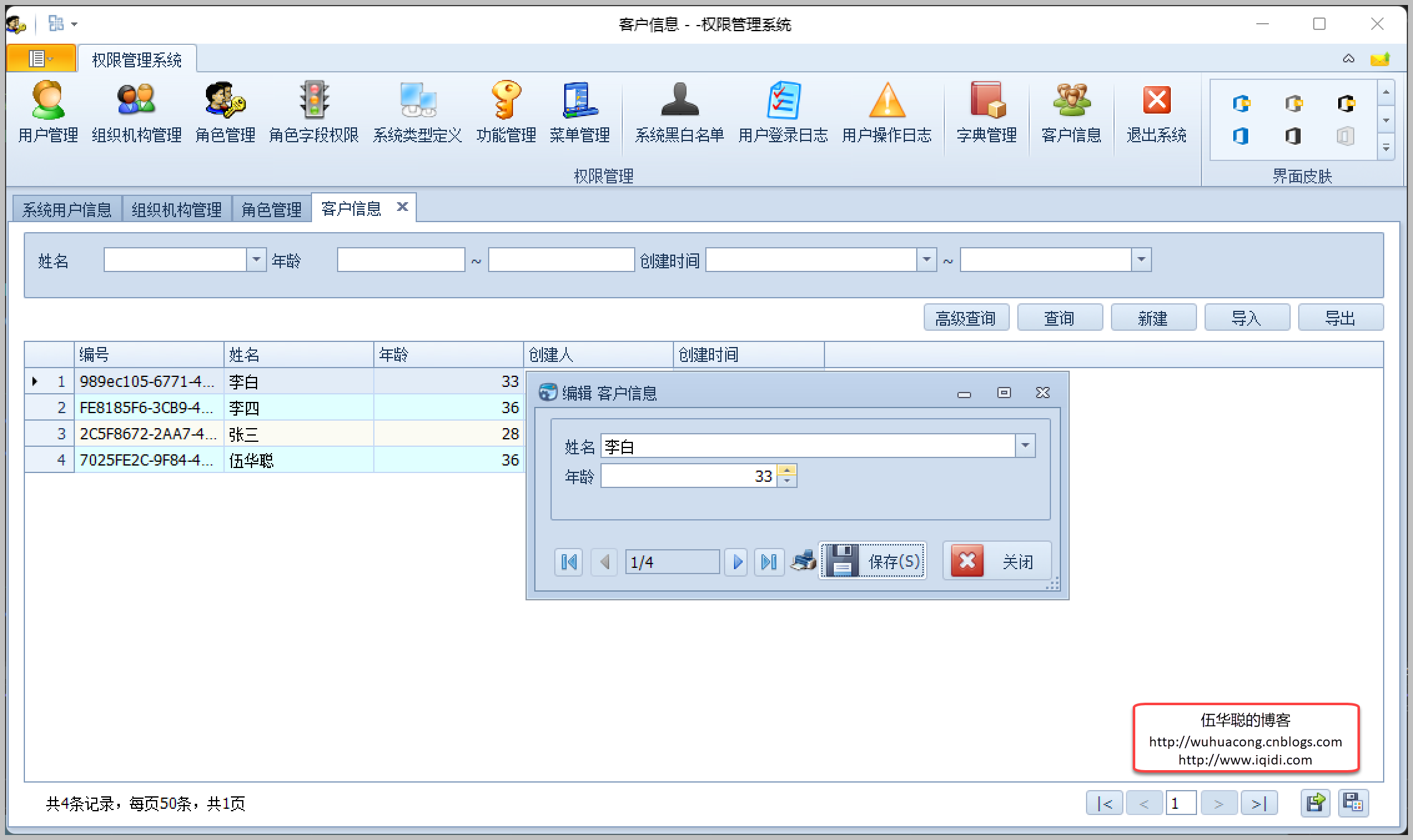
 主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发
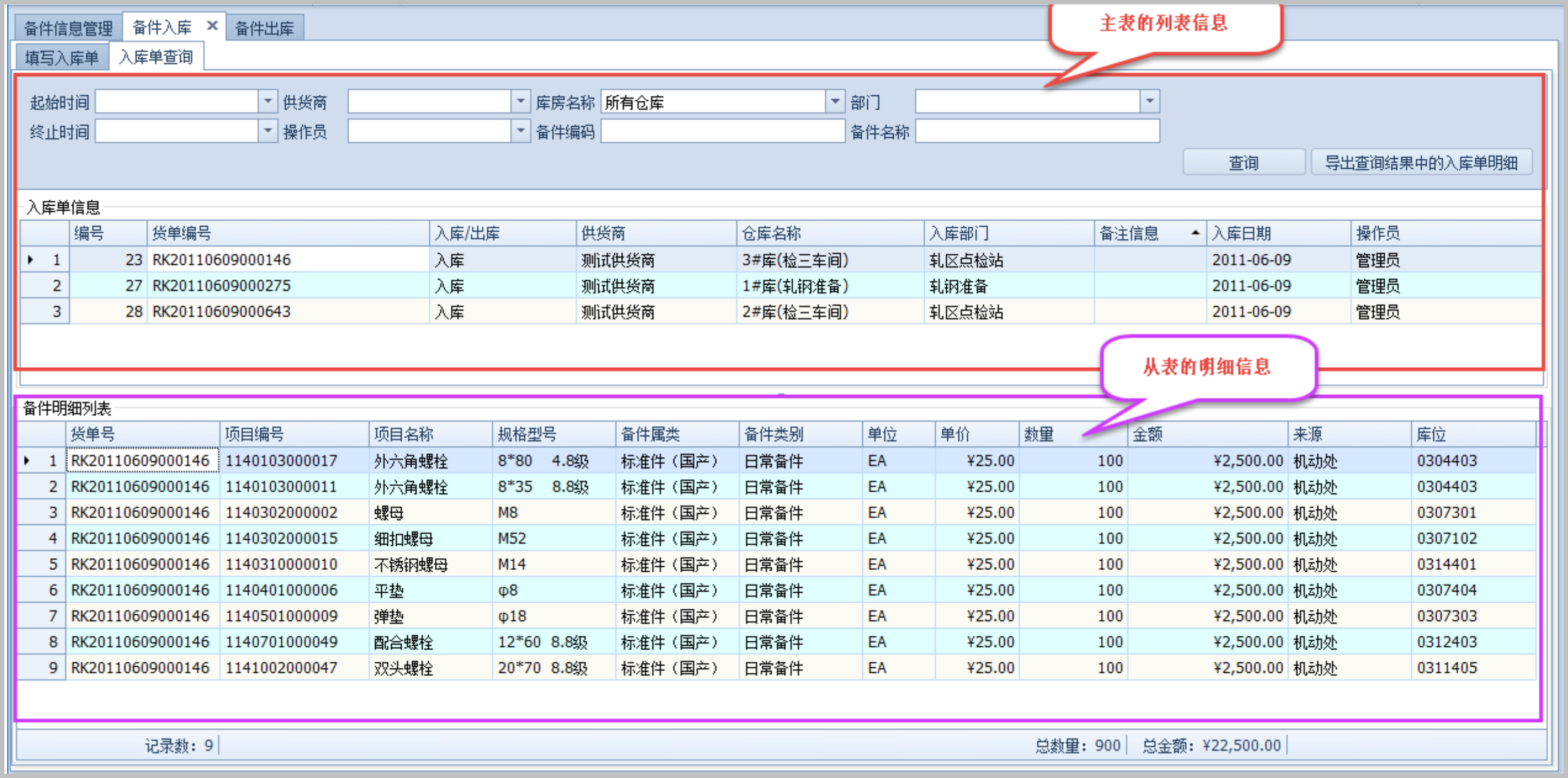
主要研究技术:代码生成工具、会员管理系统、客户关系管理软件、病人资料管理软件、Visio二次开发、酒店管理系统、仓库管理系统等共享软件开发