来源: sql server 锁与事务拨云见日(下) – 花阴偷移 – 博客园
在锁与事务系列里已经写完了上篇中篇,这次写完下篇。这个系列俺自认为是有条不紊的进行,但感觉锁与事务还是有多很细节没有讲到,温故而知新可以为师矣,也算是一次自我提高总结吧,也谢谢大伙的支持。在上一篇的末尾写了事务隔离级别的不同表现,还没写完,只写到了重复读的不同隔离表现,这篇继续写完序列化,快照的不同隔离表现,事务隔离级别的总结。最后讲下事务的死锁,事务的分布式,事务的并发检查。
一. 事务隔离不同表现
设置序列化
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
设置行版本控制已提交读
ALTER DATABASE Test SET READ_COMMITTED_SNAPSHOT on; SET TRANSACTION ISOLATION LEVEL READ COMMITTED
设置快照隔离
ALTER DATABASE Test SET ALLOW_SNAPSHOT_ISOLATION ON; SET TRANSACTION ISOLATION LEVEL SNAPSHOT
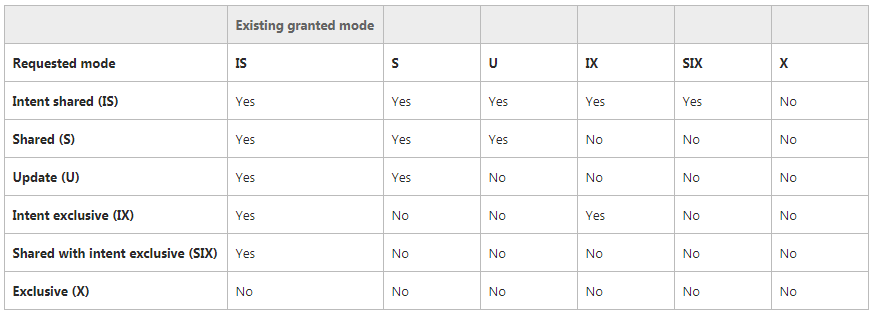
1.1 已重复读和序列化与其它事务并发,的区别如下表格:
| 可重复读 | 序列化 | 其它事务 |
| SET TRANSACTION ISOLATION
LEVEL REPEATABLE READ |
SET TRANSACTION ISOLATION
LEVEL SERIALIZABLE |
|
| begin tran
select count(*) from product where memberID=9708 这里显示500条数据,事务还没有结束 |
begin tran
select count(*) from product where memberID=9708 这里显示500条数据,事务还没有结束 |
|
| begin tran
insert into product values(‘test2’,9708) 其它事务里,想增加一条数据。 如果并发的事务是可重复读, 这条数据可以插入成功。 如果并发的事务是序列化, 这条数据插入是阻塞的。 |
||
| select count(*) from product
where memberID=9708 在事务里再次查询时,发现显示501条数据 |
select count(*) from productwhere memberID=9708
在事务再次查询时,还是显示500条数据 |
|
| commit tran
在一个事务里,对批数据多次读取,符合条件 的行数会不一样。 |
commit tran
事务结束 |
如果并发是可序列化并且commit,
其它事务新增阻塞消失,插入开始执行。 |
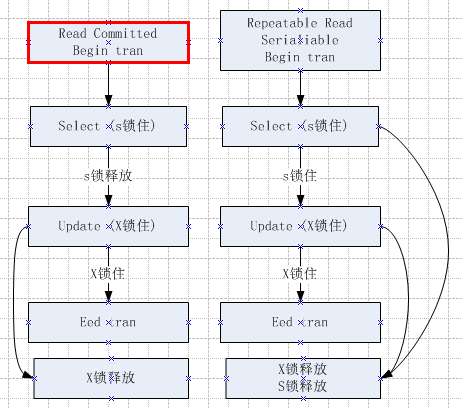
1.2 已提交读、行版本控制已提交读、快照隔离,与其它事务并发,的区别如下表格:
| 已提交读 | 行版本控制已提交读 | 快照隔离 | 其它事务 |
| SET TRANSACTION ISOLATION
LEVEL READ COMMITTED |
ALTER DATABASE Test SET READ_COMMITTED_SNAPSHOT ON; SET TRANSACTION ISOLATION |
ALTER DATABASE TEST SET ALLOW_SNAPSHOT_ISOLATION ON; SET TRANSACTION ISOLATION |
|
| begin tran
select model from product 得到值为test |
begin tran
select model from product 得到值为test |
begin tran
select model from product 得到值为test |
|
| begin tran update product set model=’test1′ where sid=1 |
|||
| select model from product where sid=9708 事务里再次查询 阻塞 |
select model from product where sid=9708 事务里再次查询值为test, 读到行版本 |
select model from product where sid=9708 事务里再次查询值为test,读到行版本 |
|
| 阻塞解除,再次查询返回 test1 | 再次查询 test1 其它事务提交后,这里读到的是新 (修改后的)数据 |
再次查询 test
其它事务提交后,这里读取还是旧数据 |
commit tran |
| 事务里updaate修改 修改成功 | 事务里updaate修改 修改成功 | 事务里updaate修改, 修改失败报错 |
二. 事务总结
2.1 事务不同隔离级别的优缺点,以及使用场景 如下表格:
| 隔离级别 | 优点 | 缺点 | 使用场景 |
| 未提交读 | 读数据的时候,不申请共享锁,所以不会被阻塞 | 读到的数据,可能会脏读,不一致。 | 如做年度,月度统计报表,数据不一定要非常精确 |
| 已提交读 | 比较折中,而且是推荐的默认设置 | 有可能会阻塞,在一个事务里,多次读取相同的数据行,得到的结果可能不同。 | 一般业务都是使用此场景 |
| 可重复读 | 在一个事务里,多次读取相同的数据行,得到的结果可保证一致、 | 更严重的阻塞,在一个事务里,读取符合某查询的行数,会有变化(这是因为事务里允许新增) | 如当我们在事务里需要,多次统计查询范围条件行数, 做精确逻辑运算时,需要考虑逻辑是否会前后不一致. |
| 可序列化 | 最严重格的数据保护,读取符合某查询的行数,不会有变化(不允许新增)。 | 其它事务的增,删,改,查 范围内都会阻塞 | 如当我们在写事务时,不用考虑新增数据带来的逻辑错误。 |
| 行版本控制已提交读 | 阻塞大大减少(读与读不阻塞,读与写不阻塞)
阻塞减少,能读到新数据 |
写与写还是会阻塞,行版本是存放在tempdb里,数据修改的越多,需要
存储的信息越多,维护行版本就 需要越多的的开销 |
如果默认方式阻塞比较严重,推荐用行版本控制已提交读,改善性能 |
| 快照隔离 | 阻塞大大减少(读与读不阻塞,读与写不阻塞)
阻塞减少,有可能读到旧数据 |
维护行版本需要额外开销,且可能读到旧的数据 | 允许读取稍微比较旧版本信息的情况下 |
2.2 锁的隔离级别(补充)
了解了事务的隔离级别,锁也是有隔离级别的,只是它针对是单独的SQL查询。下面包括显示如下
select COUNT(1) from dbo.product(HOLDLOCK)
| HOLDLOCK | 在该表上保持共享锁,直到整个事务结束,而不是在语句执行完立即释放所添加的锁。
与SERIALIZABLE一样 |
| NOLOCK | 不添加共享锁和排它锁,仅应用于SELECT语句
与READ UNCOMMITTED一样 |
| PAGLOCK | 指定添加页锁(否则通常可能添加表锁)。 |
| READPAST | 跳过已经加锁的数据行, 仅应用于READ COMMITTED隔离性级别下事务操作中的SELECT语句操作 |
| ROWLOCK | 使用行级锁,而不使用粒度更粗的页级锁和表级锁
建议中用在UPDATE和DELETE语句中。 |
| TABLOCKX | 表上使用排它锁, 这个锁可以阻止其他事务读或更新这个表的数据 |
| UPDLOCK | 指定在读表中数据时设置更新锁(update lock)而不是设置共享锁,作用是允许用户先读取数据(而且不阻塞其他用户读数据),并且保证在后来再更新数据时,这一段时间内这些数据没有被其他用户修改 |
五.分布式事务
分布式事务是跨越两个或多个称为资源管理器的服务器。 称为事务管理器的服务器组件必须在资源管理器之间协调事务管理。在 .NET Framework 中,分布式事务通过 System.Transactions 命名空间中的 API 进行管理。 如果涉及多个永久资源管理器,System.Transactions API 会将分布式事务处理委托给事务监视器,例如 Microsoft 分布式事务协调程序 (MS DTC),在Windows服务里该服务叫Distributed Transaction Coordinator 默认未启动。
在SQL server里 分布式是通过BEGIN DISTRIBUTED TRANSACTION 的T-SQL来实现,是分布式事务处理协调器 (MS DTC) 管理的 Microsoft 分布式事务的起点。执行 BEGIN DISTRIBUTED TRANSACTION 语句的 SQL Server 数据库引擎的实例是事务创建者。并控制事务的完成。 当为会话发出后续 COMMIT TRANSACTION 或 ROLLBACK TRANSACTION 语句时,控制事务实例请求 MS DTC 在所涉及的所有实例间管理分布式事务的完成(事务级别的快照隔离不支持分布式事务)。
在执行T-sql里 查询多个数据库主要是通过引用链接服务器的分布式查询,下面添加了RemoteServer链接服务器

USE AdventureWorks2012;
GO
BEGIN DISTRIBUTED TRANSACTION;
-- Delete candidate from local instance.
DELETE AdventureWorks2012.HumanResources.JobCandidate
WHERE JobCandidateID = 13;
-- Delete candidate from remote instance.
DELETE RemoteServer.AdventureWorks2012.HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT TRANSACTION;
GO
六.事务死锁
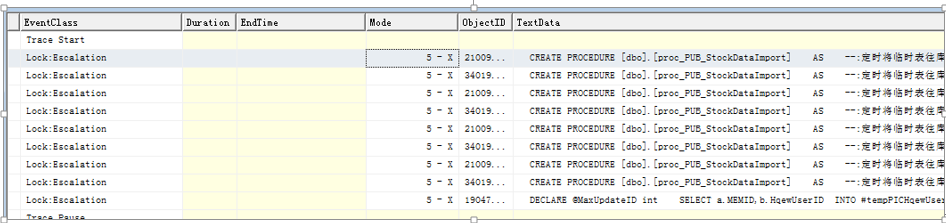
6.1 在关系型数据库里都有死锁的概念,在并发访问量高时,事务里或者T-sql大批量操作(特别是修改删除结果集),都有可能导致死锁。死锁是由两个互相阻塞的线程组成也称为抱死。sql server死锁监视器进程会定期检查死锁,默认间隔为5秒,会自动判断将回滚开销影响最少的事务作为死锁牺牲者,并收到1025 错误,消息模板来自master.dbo.sysmessages表的where error=1205。当发生死锁时要了解两方进程的sessionid各是多少, 各会话的查询语句,冲突资源是什么。请查看死锁的分析排查。
会产生死锁的资源主要是:锁 (就是上篇讲的数据行,页,表等资源),其它的死锁包括如:1. 工作者线程调度程序或CLR同步对象。2.两个线程需要更多内存,但获得授权前一个必须等待另一个。3.同一个查询的并行线程。4.多动态结果集(MARS)资源线程内部冲突。这四种很少出现死锁,重点只要关注锁资源带来的死锁。
6.2 下面事务锁资源产生死锁的原理:
1. 事务T1和事务T2 分别占用共享锁RID第1行和共享锁RID第2行。
2. 事务T1更新RID2试图获取X阻塞,事务T2更新RID2试图获取X阻塞。
3. 事务各自占有共享锁未释放,而要申请对方X锁会排斥一切锁

6.3 死锁与阻塞的区别
阻塞是指:当一个事务请求一个资源尝试获取锁时,被其它事务锁定,请求的事务会一直等待,直到其它事务把该锁释放,这就发生了阻塞,默认情况SQLServer会一直等下去。所以阻塞往往能持续很长时间,这对程序的并发性能影响很大。
死锁是两个或多个进程之间的相互等待,一般在5秒就会检测出来,消除死锁。并发性能不像阻塞那么严重。
阻塞是单向的,互相阻塞就变成了死锁。
6.3 尽量避免死锁的方法
按同一顺序访问对象
避免事务中的用户交互
保持事务简短
合理使用隔离级别
调整语句的执行计划,减少锁的申请数目。
七.事务并发检查
在检查并发方面,有很多种方式像原来的如sp_who,sp_who2等系统存储过程,perfmon计数器,sql Trace/profiler工具等,检测和分析并发问题,还包括sql server 2005以及以上的:
DMV 特别是sys.dm_os_wait_stats和sys.dm_os_waiting_tasks ,这里简单讲下并发检查
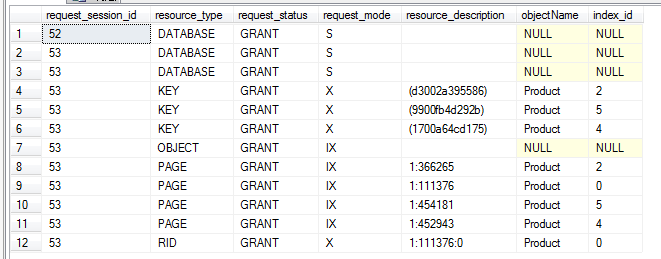
例如:查询用户会话的相关信息
SELECT blocking_session_id FROM sys.dm_os_waiting_tasks WHERE session_id>50
blocking_session_id 阻塞会话值有时为负数:
-2 :被阻塞资源属于孤立分布式事务。
-3: 被阻塞资源属于递延恢复事务。
-4: 对于锁存器等待,内锁存器状态转换阻止了session的识别。
例如:下面查询阻塞超5秒的等待
SELECT blocking_session_id FROM sys.dm_os_waiting_tasks WHERE wait_duration_ms>5000
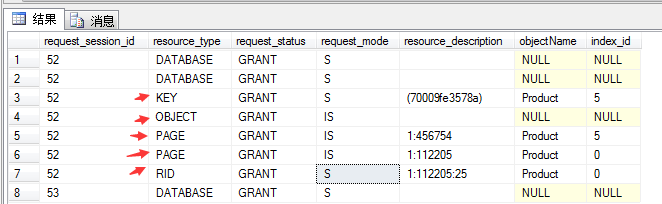
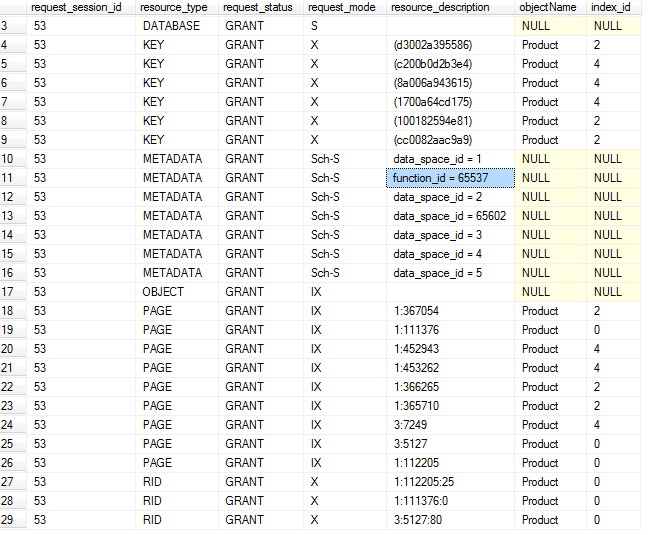
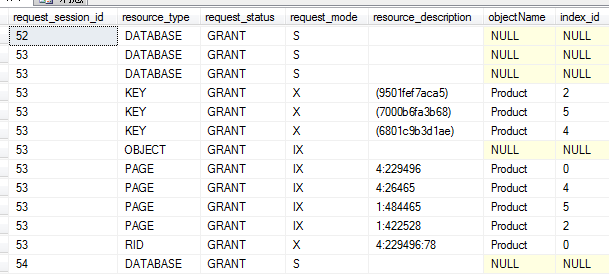
例如:只关注锁的阻塞,可以查看sys.dm_tran_locks
SELECT * FROM sys.dm_tran_locks WHERE request_status=’wait’
通过sys.dm_exec_requests查看用户请求
通过sqlDiag.exe收集运行系统的信息
通过errorlog里打开跟踪标识1222 来分析死锁
通过sys.sysprocess 检测阻塞。