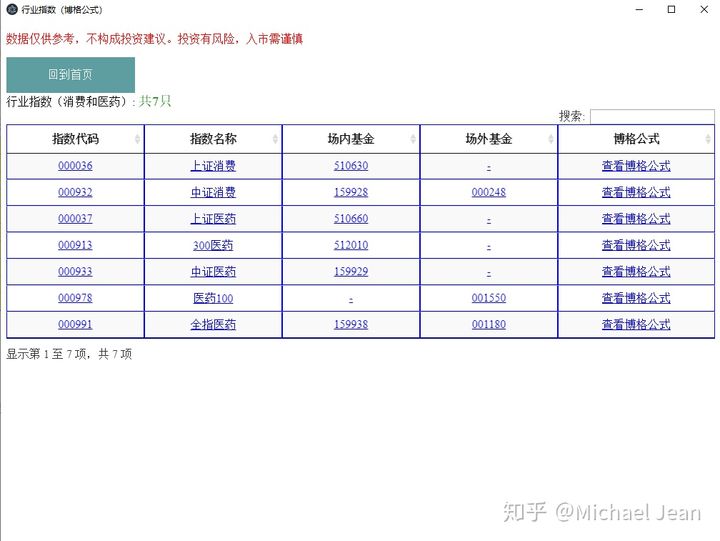
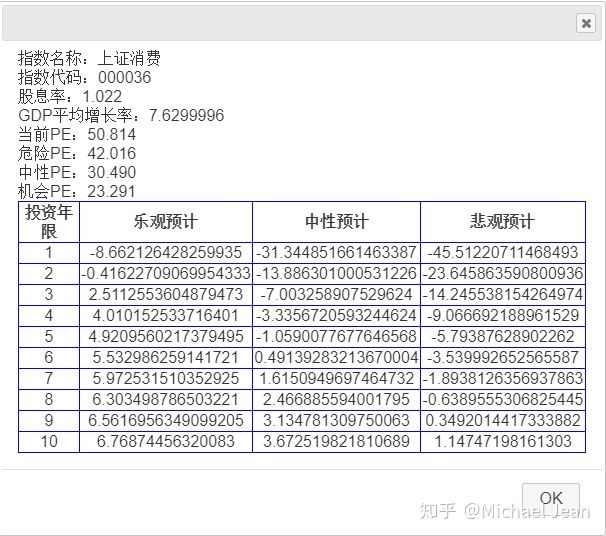
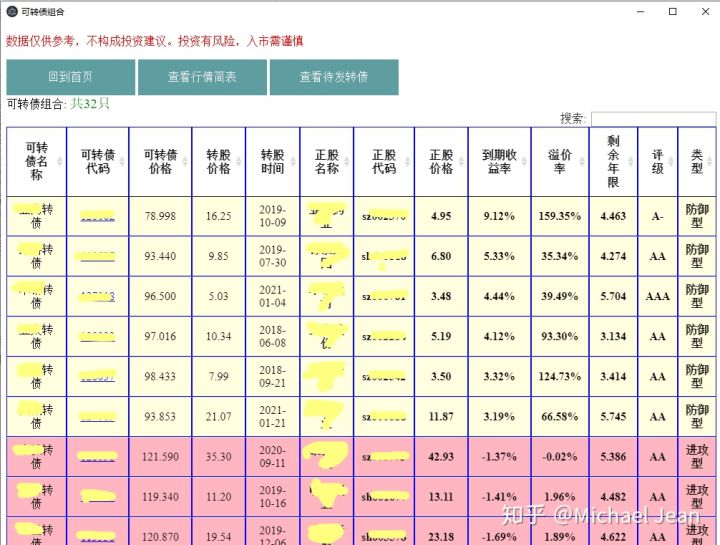
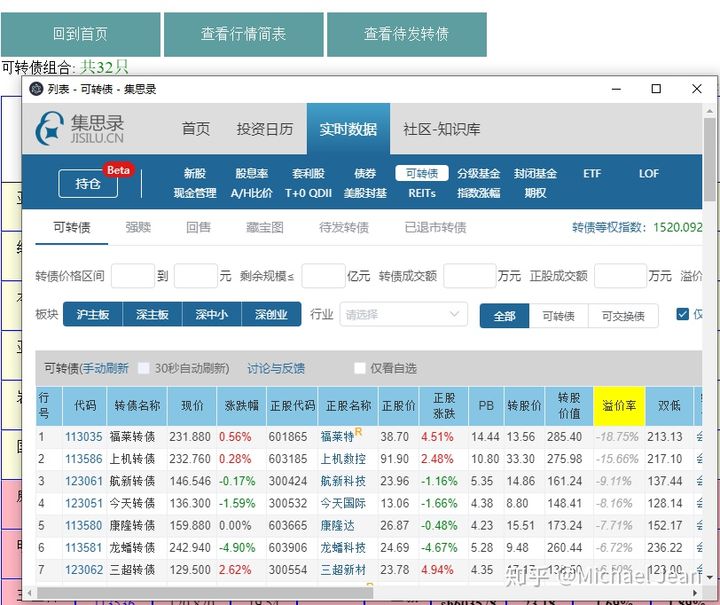
来源: 秒杀系统优化方案(下)吐血整理 – 开拖拉机的蜡笔小新 – 博客园
3. 深入优化设计
3.1 初始方案问题分析
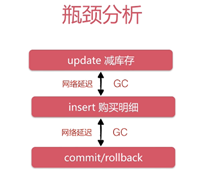
在前面针对数据库的优化中,由于数据库行级锁存在竞争造成大量的串行阻塞,我们使用了存储过程(或者触发器)等技术绑定操作,整个事务在MySQL端完成,把整个热点执行放在一个过程当中一次性完成,可以屏蔽掉网络延迟时间,减少行级锁持有时间,提高事务并发访问速度。
可是问题时并发的流量实际上都是直接穿透让MYSQL自己去抗,比如说库存是否卖完以及用户是否重复秒杀都完全是靠查询数据库去判断,造成数据库不必要的负担非常大,然而这些都可以放在缓存做一个标记在服务层进行拦截,对于中小规模的并发还可以,但是真正的超高并发,显然这个还不完善。
3.2 优化的方向和思路
方向:将请求尽量拦截在系统上游
传统秒杀系统之所以挂,请求都压倒了后端数据层,数据读写锁冲突严重,并发高响应慢,几乎所有请求都超时,流量虽大,下单成功的有效流量甚小【一趟火车其实只有2000张票,200w个人来买,基本没有人能买成功,请求有效率为0】
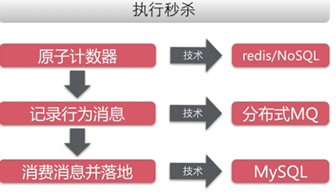
思路:限流和削峰
限流:屏蔽掉无用的流量,允许少部分流量流向后端。
削峰:瞬时大流量峰值容易压垮系统,解决这个问题是重中之重。常用的消峰方法有异步处理、缓存和消息中间件等技术。
异步处理:秒杀系统是一个高并发系统,采用异步处理模式可以极大地提高系统并发量,其实异步处理就是削峰的一种实现方式。
缓存:秒杀系统本身是一个典型的读多写少的应用场景【一趟火车其实只有2000张票,200w个人来买,最多2000个人下单成功,其他人都是查询库存,写比例只有0.1%,读比例占99.9%】,非常适合使用缓存。
消息队列:消息队列可以削峰,将拦截大量并发请求,这也是一个异步处理过程,后台业务根据自己的处理能力,从消息队列中主动的拉取请求消息进行业务处理。
3.3 前端优化
3.3.1 静态资源缓存
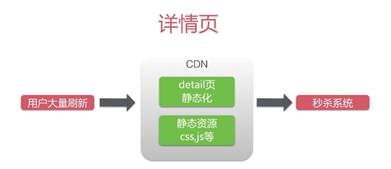
1. 页面静态化
对商品详情和订单详情进行页面静态化处理,页面是存在html,动态数据是通过接口从服务端获取,实现前后端分离,静态页面无需连接数据库打开速度较动态页面会有明显提高。
2.页面缓存
通过CDN缓存静态资源,来抗峰值。不使用CDN的话也可以通过在手动渲染得到的html页面缓存到redis。
3.3.2 限流手段
1. 使用数学公式验证码
描述:点击秒杀前,先让用户输入数学公式验证码,验证正确才能进行秒杀。
好处:
1)防止恶意的机器人和爬虫
2)分散用户的请求
实现:
1)前端通过把商品id作为参数调用服务端创建验证码接口
2)服务端根据前端传过来的商品id和用户id生成验证码,并将商品id+用户id作为key,生成的验证码作为value存入redis,同时将生成的验证码输入图片写入imageIO让前端展示。
3)将用户输入的验证码与根据商品id+用户id从redis查询到的验证码对比,相同就返回验证成功,进入秒杀;不同或从redis查询的验证码为空都返回验证失败,刷新验证码重试
2. 禁止重复提交
用户提交之后按钮置灰,禁止重复提交
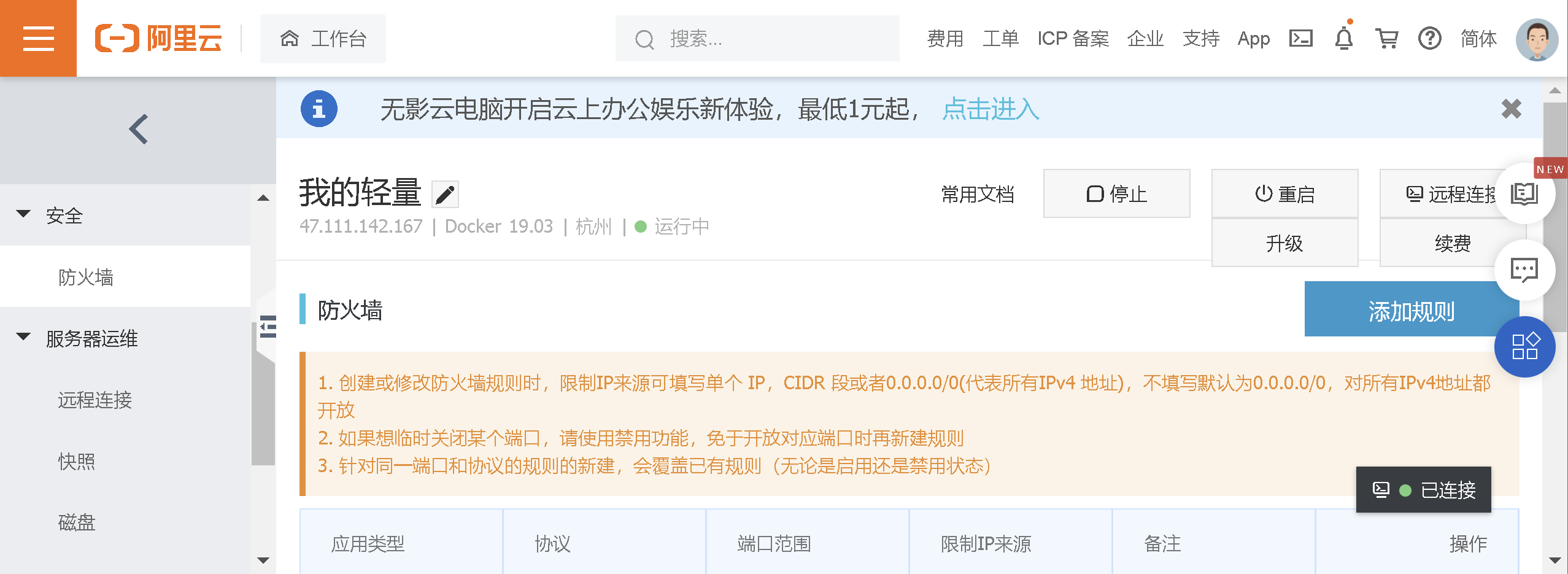
3.4 中间代理层
可利用负载均衡(例如反响代理Nginx等)使用多个服务器并发处理请求,减小服务器压力。
3.5 后端优化
3.5.1 控制层(网关层)
限制同一UserID访问频率:尽量拦截浏览器请求,但针对某些恶意攻击或其它插件,在服务端控制层需要针对同一个访问uid,限制访问频率。
1. 利用缓存
设置缓存有效时间,在缓存中计数,如果在缓存的有效时间内请求的次数超了的话,就返回请求访问太频繁。
2. 利用RateLimiter
RateLimiter是guava提供的基于令牌桶算法的限流实现类,通过调整生成token的速率来限制用户频繁访问秒杀页面,从而达到防止超大流量冲垮系统。(令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
3.5.2 服务层
当用户量非常大的时候,拦截流量后的请求访问量还是非常大,此时仍需进一步优化。
1. 业务分离:将秒杀业务系统和其他业务分离,单独放在高配服务器上,可以集中资源对访问请求抗压。——应用的拆分
2. 采用消息队列缓存请求:将大流量请求写到消息队列缓存,利用服务器根据自己的处理能力主动到消息缓存队列中抓取任务处理请求,数据库层订阅消息减库存,减库存成功的请求返回秒杀成功,失败的返回秒杀结束。
3. 利用缓存应对读请求:对于读多写少业务,大部分请求是查询请求,所以可以读写分离,利用缓存分担数据库压力。
4. 利用缓存应对写请求:缓存也是可以应对写请求的,可把数据库中的库存数据转移到Redis缓存中,所有减库存操作都在Redis中进行,然后再通过后台进程把Redis中的用户秒杀请求同步到数据库中。
可以将缓存和消息中间件 组合起来,缓存系统负责接收记录用户请求,消息中间件负责将缓存中的请求同步到数据库。
方案:本地标记 + redis预处理 + RabbitMQ异步下单 + 客户端轮询
描述:通过三级缓冲保护,1、本地标记 2、redis预处理 3、RabbitMQ异步下单,最后才会访问数据库,这样做是为了最大力度减少对数据库的访问。
实现:
- 在秒杀阶段使用本地标记对用户秒杀过的商品做标记,若被标记过直接返回重复秒杀,未被标记才查询redis,通过本地标记来减少对redis的访问
- 抢购开始前,将商品和库存数据同步到redis中,所有的抢购操作都在redis中进行处理,通过Redis预减少库存减少数据库访问
- 为了保护系统不受高流量的冲击而导致系统崩溃的问题,使用RabbitMQ用异步队列处理下单,实际做了一层缓冲保护,做了一个窗口模型,窗口模型会实时的刷新用户秒杀的状态。
- client端用js轮询一个接口,用来获取处理状态
3.5.3 数据库层
数据库层是最脆弱的一层,一般在应用设计时在上游就需要把请求拦截掉,数据库层只承担“能力范围内”的访问请求。所以,上面通过在服务层引入队列和缓存,让最底层的数据库高枕无忧。但依然可以进行如下方向的优化:
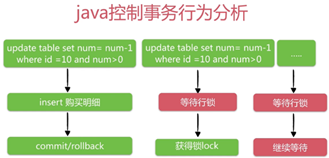
对于秒杀系统,直接访问数据库的话,存在一个【事务竞争优化】问题,可使用存储过程(或者触发器)等技术绑定操作,整个事务在MySQL端完成,把整个热点执行放在一个过程当中一次性完成,可以屏蔽掉网络延迟时间,减少行级锁持有时间,提高事务并发访问速度。
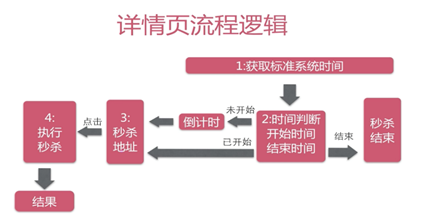
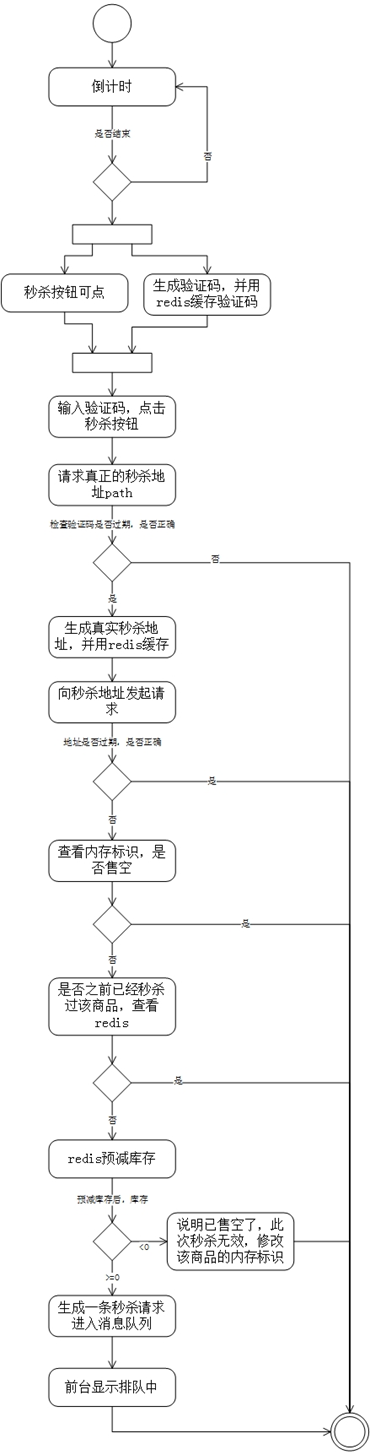
3.7 优化秒杀流程
- 秒杀活动开始之前有个活动倒计时,时间到了则会放开秒杀的权限,并生成一个验证码展示在前面页面,并把验证结果存在redis中,这里利用redis有过期时间的特性,也给验证码的缓存加了个过期时间。这里的redis缓存用的是redis的string类型。
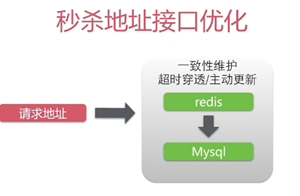
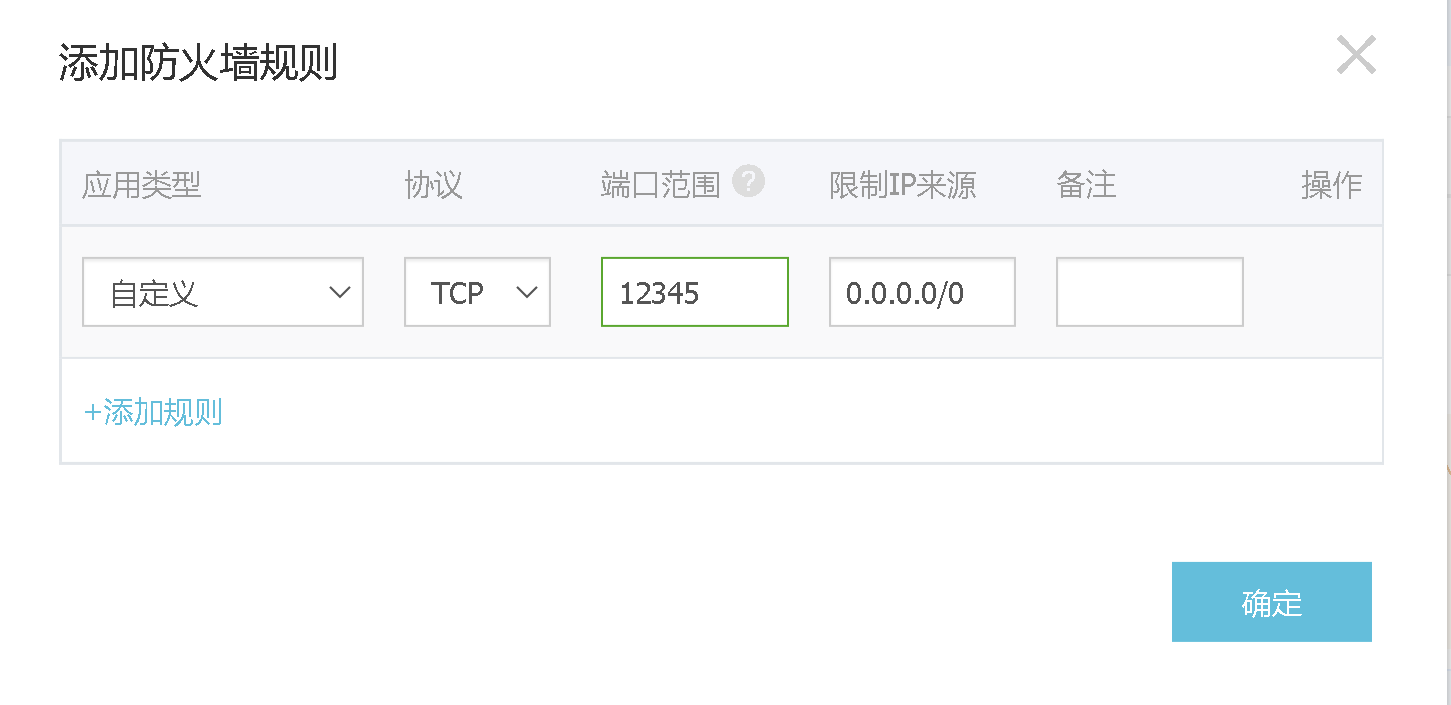
- 在秒杀之前先要填一个验证码verifyCode,点击秒杀按钮时,先发送ajax请求到后台获取真实的秒杀地址path,这里秒杀地址是隐藏的,目的是防止有人恶意刷秒杀接口。所谓隐藏地址,其实是在请求地址中加一段随机字符串,这段字符串是变化的,因此秒杀请求地址是动态的;
- 先说下如何获取真实的秒杀地址,后台先访问redis,验证一下这个验证码有没有过期以及这个verifyCode是不是正确,验证码验证通过后,先删除这个验证码缓存,然后生成真实地址;
- 真实地址随机字符串由uuid以及md5加密生成,并且保存在redis中,并且设置了有效期;
- 从浏览器端向秒杀地址发起请求,带上path参数去后台调用真正的秒杀接口,下面是秒杀接口的逻辑;
- 访问redis,验证path有没有过期,以及是不是正确。这里验证path以及上面的校验验证码,都是用userId对应生成的一个key值去取redis中的数据;
- path验证通过后,先访问内存标识,看秒杀的这个商品有没有卖完,减少对redis的不必要访问。每一种参与秒杀活动的商品都在内存里用HashMap设置了一个标识,标识某个商品id商品是否卖完了。这里的是否卖完的内存标识设置以及每种参与秒杀商品的库存存入redis是在系统启动时做的;
- 如果内存标识中这个商品没有卖完,则要看这个用户在这次活动中是否重复秒杀,因为我们的秒杀规则是一个用户id对于某个商品id的商品只能秒杀一件。如何判断该用户有没有秒杀过这件商品呢,秒杀记录也保存在redis缓存中;
- 如果判断秒杀过则返回提示,如果没有秒杀过,继续;
- 上面说过系统加载时redis中保存了各商品对应的库存,这里用到redis的原子操作的方法decr,将对应商品的库存减1,此时数据库时的库存还没有减,因此是预减库存;
- desc方法返回该商品此时的库存,如果小于0,说明商品已经卖完了,此次秒杀无效,并且设置该商品的内存标识为true,表示已卖完;
- 正确地预减库存后,然后就要真正操作数据库了,数据库一般是性能瓶颈,比较耗时,因此决定用异步方式处理。对于每一条秒杀请求存入消息队列RabbitMQ中,消息体中要包含哪个用户秒杀哪个商品的信息,这里是封装了一个消息体类,这样一个秒杀请求就进入了消息队列,一个秒杀请求还没有完成,真正的秒杀请求的完成得要持久化到数据库,生成订单,减了数据库的库存才能算数,这时在客户端显示的一般是排队中,比如以前在抢购小米手机时,我就看到这样的展示,过一会再刷新页面就显示没抢到;
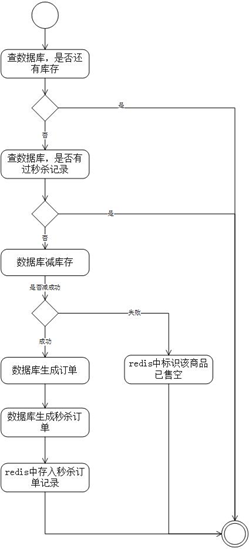
- 消息队列处理秒杀请求。先从消息体中解析出用户id和商品id,查数据库看这个商品是否卖完了,查数据库看该用户对于这个商品是否有过秒杀记录;数据库减库存,数据库生成订单,这两项持久化地写数据库操作放在同一个事务中,要么都执行成功,要么都失败。并把秒杀记录对象,包括秒杀单号、订单号、用户id、商品id,存入redis中。如果数据库减库存失败,表明商品卖完了,则要在redis中设置该商品已卖完的标识。消息队列处理秒杀请求。先从消息体中解析出用户id和商品id,查数据库看这个商品是否卖完了,查数据库看该用户对于这个商品是否有过秒杀记录;
- 数据库减库存,数据库生成订单,这两项持久化地写数据库操作放在同一个事务中,要么都执行成功,要么都失败。并把秒杀记录对象,包括秒杀单号、订单号、用户id、商品id,存入redis中。如果数据库减库存失败,表明商品卖完了,则要在redis中设置该商品已卖完的标识。
- ajax发起秒杀请求,秒杀请求的处理逻辑最后也只是把这条请求放入消息队列,并不能返回是否秒杀成功的结果。因此,当秒杀请求正确响应后,即请求放入消息队列后,需要另外一个请求去轮询秒杀结果,秒杀成功的标志是生成秒杀订单,并把秒杀订单对象放入redis中。所以轮询秒杀结果,只用去轮询redis中是否有对应于该用户的该商品的秒杀订单对象,如果有,则表明秒杀成功,并在前台给出提示。
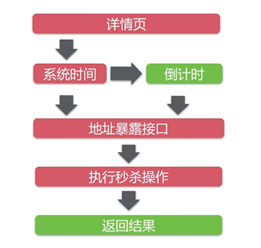
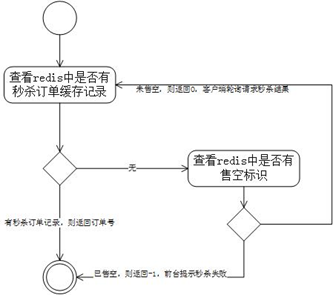
上面的秒杀流程对应的流程图如下:
步骤1到12,主体是redis预减库存,生成消息队列:
步骤13到14是处理消息队列:
步骤15,是客户端请求秒杀结果:
4. 问题解析
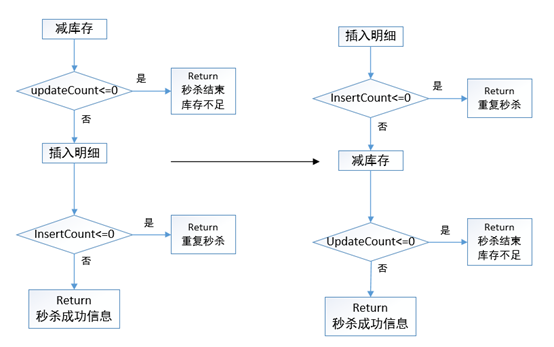
1. 如何解决库存的超卖问题?
卖超原因:
(1)一个用户同时发出了多个请求,如果库存足够,没加限制,用户就可以下多个订单。(2)减库存的sql上没有加库存数量的判断,并发的时候也会导致把库存减成负数。
解决办法:
(1):在后端的秒杀表中,对user_id和goods_id加唯一索引,确保一个用户对一个商品绝对不会生成两个订单。
(2):我们的减库存的sql上应该加上库存数量的判断
数据库自身是有行级锁的,每次减库存的时候判断count>0,它实际上是串行的执行update的,因此绝对不会卖超!。
UPDATE seckill
SET number = number-1
WHERE seckill_id=#{seckillId}
AND start_time <#{killTime}
AND end_time >= #{killTime}
AND number > 0;
2. 如何解决少卖问题—Redis预减成功而DB扣库存失败?
前面的方案中会出现一个少卖的问题。Redis在预减库存的时候,在初始化的时候就放置库存的大小,redis的原子减操作保证了多少库存就会减多少,也就会在消息队列中放多少。
现在考虑两种情况:
1)数据库那边出现非库存原因比如网络等造成减库存失败,而这时redis已经减了。
2)万一一个用户发出多个请求,而且这些请求恰巧比别的请求更早到达服务器,如果库存足够,redis就会减多次,redis提前进入卖空状态,并拒绝。不过这两种情况出现的概率都是非常低的。
两种情况都会出现少卖的问题,实际上也是缓存和数据库出现不一致的问题!
但是我们不是非得解决不一致的问题,本身使用缓存就难以保证强一致性:
在redis中设置库存比真实库存多一些就行。
3. 秒杀过程中怎么保证redis缓存和数据库的一致性?
在其他一般读大于写的场景,一般处理的原则是:缓存只做失效,不做更新。
采用Cache-Aside pattern:
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
更新:先把数据存到数据库中,成功后,再让缓存失效。
4. Redis中的库存如何与DB中的库存保持一致?
Redis中的数量不是库存,它的作用仅仅时候只是为了阻挡多余的请求透传到db,起到一个保护DB的作用。因为秒杀商品的数量是有限的,比如只有10个,让1万个请求去访问DB是没有意义的,因为最多只有10个请求会下单成功,剩余的9990个请求都是无效的,是可以不用去访问db而直接失败的。
因此,这是一个伪问题,我们是不需要保持一致的。
5. 为什么要隐藏秒杀接口?
html是可以被右键->查看源代码,如果秒杀地址写死在源文件中,是很容易就被恶意用户拿到的,就可以被机器人利用来刷接口,这对于其他用户来说是不公平的,我们也不希望看到这种情况。所以我们可以控制让用户在没有到秒杀时间的时候不能获取到秒杀地址,只返回秒杀的开始时间。
当到秒杀时间的时候才返回秒杀地址即seckill_id以及根据seckill_id和salt加密的MD5,前端再次拿着seckill_id和MD5才能执行秒杀。假如用户在秒杀开始前猜测到秒杀地址seckill_id去请求秒杀,也是不会成功的,因为它拿不到需要验证的MD5。这里的MD5相当于是用户进行秒杀的凭证。
6. 一个秒杀系统,500用户同时登陆访问服务器A,服务器B如何快速利用登录名(假设是电话号码或者邮箱)做其他查询?
主从复制,读写分离