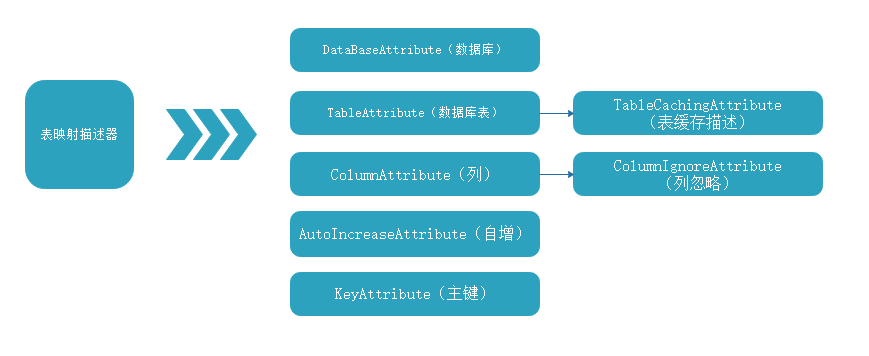
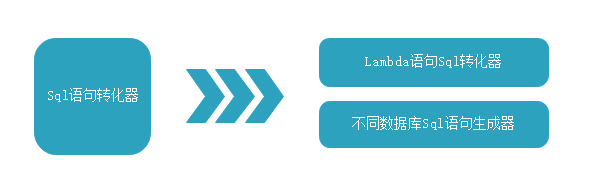
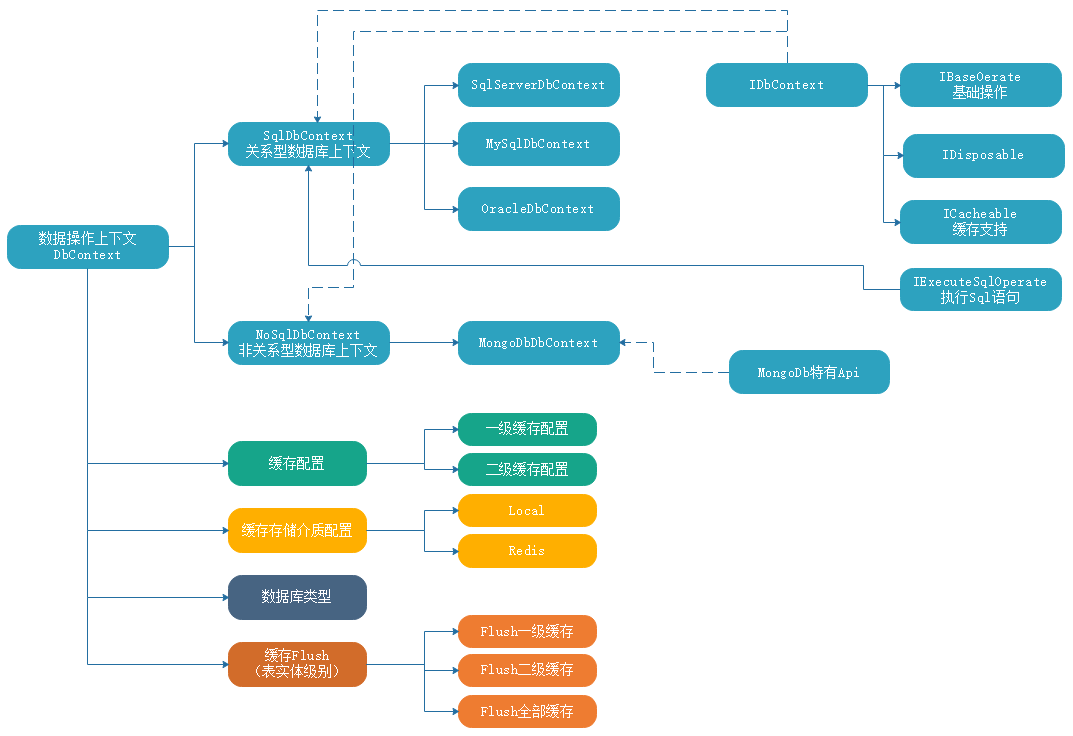
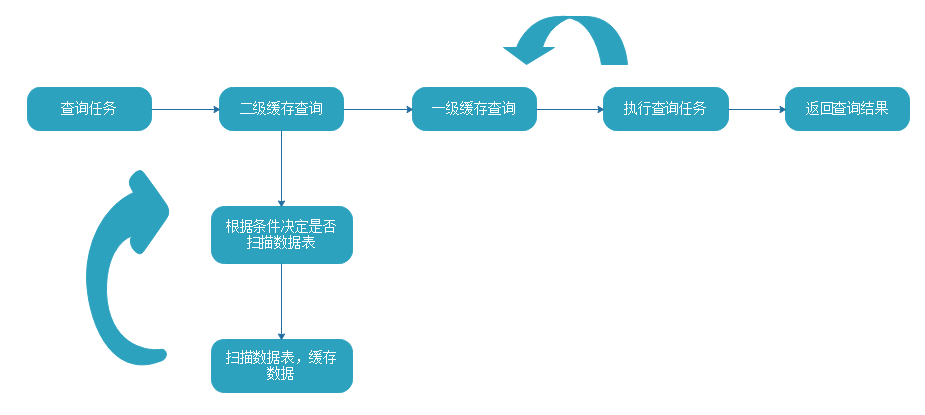
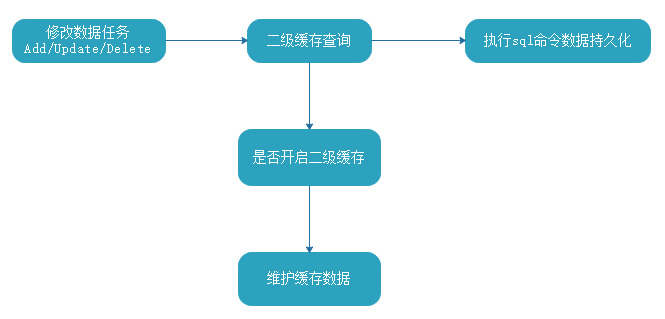
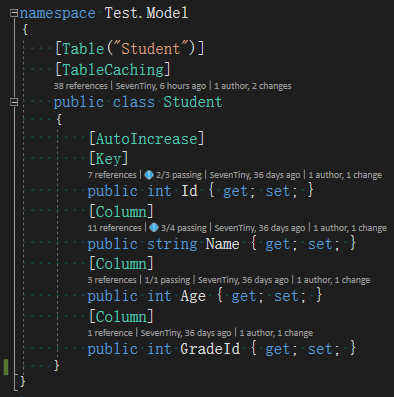
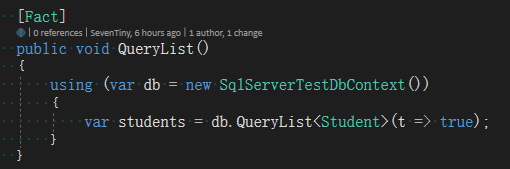
1 /*********************************************************
2 * CopyRight: 7TINY CODE BUILDER.
3 * Version: 5.0.0
4 * Author: 7tiny
5 * Address: Earth
6 * Create: 2018-04-19 21:34:01
7 * Modify: 2018-04-19 21:34:01
8 * E-mail: dong@7tiny.com | sevenTiny@foxmail.com
9 * GitHub: https://github.com/sevenTiny
10 * Personal web site: http://www.7tiny.com
11 * Technical WebSit: http://www.cnblogs.com/7tiny/
12 * Description:
13 * Thx , Best Regards ~
14 *********************************************************/
15 using MySql.Data.MySqlClient;
16 using System;
17 using System.Collections.Generic;
18 using System.ComponentModel;
19 using System.Data;
20 using System.Data.Common;
21 using System.Data.SqlClient;
22 using System.Linq;
23 using System.Linq.Expressions;
24 using System.Reflection;
25 using System.Threading.Tasks;
26
27 namespace SevenTiny.Bantina.Bankinate
28 {
29 public enum DataBaseType
30 {
31 SqlServer,
32 MySql,
33 Oracle,
34 MongoDB
35 }
36 public abstract class DbHelper
37 {
38 #region ConnString 链接字符串声明
39
40 /// <summary>
41 /// 连接字符串 ConnString_Default 默认,且赋值时会直接覆盖掉读写
42 /// </summary>
43 private static string _connString;
44 public static string ConnString_Default
45 {
46 get { return _connString; }
47 set
48 {
49 _connString = value;
50 ConnString_RW = _connString;
51 ConnString_R = _connString;
52 }
53 }
54 /// <summary>
55 /// 连接字符串 ConnString_RW 读写数据库使用
56 /// </summary>
57 public static string ConnString_RW { get; set; } = _connString;
58 /// <summary>
59 /// 连接字符串 ConnString_R 读数据库使用
60 /// </summary>
61 public static string ConnString_R { get; set; } = _connString;
62 /// <summary>
63 /// DataBaseType Select default:mysql
64 /// </summary>
65 public static DataBaseType DbType { get; set; } = DataBaseType.MySql;
66
67 #endregion
68
69 #region ExcuteNonQuery 执行sql语句或者存储过程,返回影响的行数---ExcuteNonQuery
70 public static int ExecuteNonQuery(string commandTextOrSpName, CommandType commandType = CommandType.Text)
71 {
72 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_RW))
73 {
74 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
75 {
76 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType);
77 return cmd.DbCommand.ExecuteNonQuery();
78 }
79 }
80 }
81 public static int ExecuteNonQuery(string commandTextOrSpName, CommandType commandType, IDictionary<string, object> dictionary)
82 {
83 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_RW))
84 {
85 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
86 {
87 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType, dictionary);//参数增加了commandType 可以自己编辑执行方式
88 return cmd.DbCommand.ExecuteNonQuery();
89 }
90 }
91 }
92 public static void BatchExecuteNonQuery(IEnumerable<BatchExecuteModel> batchExecuteModels)
93 {
94 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_RW))
95 {
96 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
97 {
98 foreach (var item in batchExecuteModels)
99 {
100 PreparCommand(conn.DbConnection, cmd.DbCommand, item.CommandTextOrSpName, item.CommandType, item.ParamsDic);
101 cmd.DbCommand.ExecuteNonQuery();
102 }
103 }
104 }
105 }
106 public static Task<int> ExecuteNonQueryAsync(string commandTextOrSpName, CommandType commandType = CommandType.Text)
107 {
108 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_RW))
109 {
110 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
111 {
112 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType);
113 return cmd.DbCommand.ExecuteNonQueryAsync();
114 }
115 }
116 }
117 public static Task<int> ExecuteNonQueryAsync(string commandTextOrSpName, CommandType commandType, IDictionary<string, object> dictionary)
118 {
119 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_RW))
120 {
121 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
122 {
123 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType, dictionary);//参数增加了commandType 可以自己编辑执行方式
124 return cmd.DbCommand.ExecuteNonQueryAsync();
125 }
126 }
127 }
128 public static void BatchExecuteNonQueryAsync(IEnumerable<BatchExecuteModel> batchExecuteModels)
129 {
130 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_RW))
131 {
132 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
133 {
134 foreach (var item in batchExecuteModels)
135 {
136 PreparCommand(conn.DbConnection, cmd.DbCommand, item.CommandTextOrSpName, item.CommandType, item.ParamsDic);
137 cmd.DbCommand.ExecuteNonQueryAsync();
138 }
139 }
140 }
141 }
142 #endregion
143
144 #region ExecuteScalar 执行sql语句或者存储过程,执行单条语句,返回单个结果---ScalarExecuteScalar
145 public static object ExecuteScalar(string commandTextOrSpName, CommandType commandType = CommandType.Text)
146 {
147 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_R, ConnString_RW))
148 {
149 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
150 {
151 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType);
152 return cmd.DbCommand.ExecuteScalar();
153 }
154 }
155 }
156 public static object ExecuteScalar(string commandTextOrSpName, CommandType commandType, IDictionary<string, object> dictionary)
157 {
158 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_R, ConnString_RW))
159 {
160 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
161 {
162 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType, dictionary);
163 return cmd.DbCommand.ExecuteScalar();
164 }
165
166 }
167 }
168 public static Task<object> ExecuteScalarAsync(string commandTextOrSpName, CommandType commandType = CommandType.Text)
169 {
170 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_R, ConnString_RW))
171 {
172 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
173 {
174 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType);
175 return cmd.DbCommand.ExecuteScalarAsync();
176 }
177 }
178 }
179 public static Task<object> ExecuteScalarAsync(string commandTextOrSpName, CommandType commandType, IDictionary<string, object> dictionary)
180 {
181 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_R, ConnString_RW))
182 {
183 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
184 {
185 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType, dictionary);
186 return cmd.DbCommand.ExecuteScalarAsync();
187 }
188
189 }
190 }
191 #endregion
192
193 #region ExecuteReader 执行sql语句或者存储过程,返回DataReader---DataReader
194 public static DbDataReader ExecuteReader(string commandTextOrSpName, CommandType commandType = CommandType.Text)
195 {
196 //sqlDataReader不能用using 会关闭conn 导致不能获取到返回值。注意:DataReader获取值时必须保持连接状态
197 SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_R, ConnString_RW);
198 DbCommandCommon cmd = new DbCommandCommon(DbType);
199 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType);
200 return cmd.DbCommand.ExecuteReader(CommandBehavior.CloseConnection);
201 }
202 public static DbDataReader ExecuteReader(string commandTextOrSpName, CommandType commandType, IDictionary<string, object> dictionary)
203 {
204 //sqlDataReader不能用using 会关闭conn 导致不能获取到返回值。注意:DataReader获取值时必须保持连接状态
205 SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_R, ConnString_RW);
206 DbCommandCommon cmd = new DbCommandCommon(DbType);
207 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType, dictionary);
208 return cmd.DbCommand.ExecuteReader(CommandBehavior.CloseConnection);
209 }
210 #endregion
211
212 #region ExecuteDataTable 执行sql语句或者存储过程,返回一个DataTable---DataTable
213
214 /**
215 * Update At 2017-3-2 14:58:45
216 * Add the ExecuteDataTable Method into Sql_Helper_DG
217 **/
218 public static DataTable ExecuteDataTable(string commandTextOrSpName, CommandType commandType = CommandType.Text)
219 {
220 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_R, ConnString_RW))
221 {
222 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
223 {
224 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType);
225 using (DbDataAdapterCommon da = new DbDataAdapterCommon(DbType, cmd.DbCommand))
226 {
227 DataSet ds = new DataSet();
228 da.Fill(ds);
229 if (ds.Tables.Count > 0)
230 {
231 return ds.Tables[0];
232 }
233 return default(DataTable);
234 }
235 }
236 }
237 }
238 public static DataTable ExecuteDataTable(string commandTextOrSpName, CommandType commandType, IDictionary<string, object> dictionary)
239 {
240 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_R, ConnString_RW))
241 {
242 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
243 {
244 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType, dictionary);
245 using (DbDataAdapterCommon da = new DbDataAdapterCommon(DbType, cmd.DbCommand))
246 {
247 DataSet ds = new DataSet();
248 da.Fill(ds);
249 if (ds.Tables.Count > 0)
250 {
251 return ds.Tables[0];
252 }
253 return default(DataTable);
254 }
255 }
256 }
257 }
258 #endregion
259
260 #region ExecuteDataSet 执行sql语句或者存储过程,返回一个DataSet---DataSet
261 public static DataSet ExecuteDataSet(string commandTextOrSpName, CommandType commandType = CommandType.Text)
262 {
263 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_R, ConnString_RW))
264 {
265 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
266 {
267 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType);
268 using (DbDataAdapterCommon da = new DbDataAdapterCommon(DbType, cmd.DbCommand))
269 {
270 DataSet ds = new DataSet();
271 da.Fill(ds);
272 return ds;
273 }
274 }
275 }
276 }
277 public static DataSet ExecuteDataSet(string commandTextOrSpName, CommandType commandType, IDictionary<string, object> dictionary)
278 {
279 using (SqlConnection_RW conn = new SqlConnection_RW(DbType, ConnString_R, ConnString_RW))
280 {
281 using (DbCommandCommon cmd = new DbCommandCommon(DbType))
282 {
283 PreparCommand(conn.DbConnection, cmd.DbCommand, commandTextOrSpName, commandType, dictionary);
284 using (DbDataAdapterCommon da = new DbDataAdapterCommon(DbType, cmd.DbCommand))
285 {
286 DataSet ds = new DataSet();
287 da.Fill(ds);
288 return ds;
289 }
290 }
291 }
292 }
293 #endregion
294
295 #region ExecuteList Entity 执行sql语句或者存储过程,返回一个List<T>---List<T>
296 public static List<Entity> ExecuteList<Entity>(string commandTextOrSpName, CommandType commandType = CommandType.Text) where Entity : class
297 {
298 return GetListFromDataSetV2<Entity>(ExecuteDataSet(commandTextOrSpName, commandType));
299 }
300 public static List<Entity> ExecuteList<Entity>(string commandTextOrSpName, CommandType commandType, IDictionary<string, object> dictionary) where Entity : class
301 {
302 return GetListFromDataSetV2<Entity>(ExecuteDataSet(commandTextOrSpName, commandType, dictionary));
303 }
304 #endregion
305
306 #region ExecuteEntity 执行sql语句或者存储过程,返回一个Entity---Entity
307 public static Entity ExecuteEntity<Entity>(string commandTextOrSpName, CommandType commandType = CommandType.Text) where Entity : class
308 {
309 return GetEntityFromDataSetV2<Entity>(ExecuteDataSet(commandTextOrSpName, commandType));
310 }
311 public static Entity ExecuteEntity<Entity>(string commandTextOrSpName, CommandType commandType, IDictionary<string, object> dictionary) where Entity : class
312 {
313 return GetEntityFromDataSetV2<Entity>(ExecuteDataSet(commandTextOrSpName, commandType, dictionary));
314 }
315 #endregion
316
317 #region ---PreparCommand 构建一个通用的command对象供内部方法进行调用---
318 private static void PreparCommand(DbConnection conn, DbCommand cmd, string commandTextOrSpName, CommandType commandType, IDictionary<string, object> dictionary = null)
319 {
320 //打开连接
321 if (conn.State != ConnectionState.Open)
322 {
323 conn.Open();
324 }
325
326 //设置SqlCommand对象的属性值
327 cmd.Connection = conn;
328 cmd.CommandType = commandType;
329 cmd.CommandText = commandTextOrSpName;
330 cmd.CommandTimeout = 60;
331
332 if (dictionary != null)
333 {
334 cmd.Parameters.Clear();
335 DbParameter[] parameters;
336 switch (conn)
337 {
338 case SqlConnection s:
339 parameters = new SqlParameter[dictionary.Count];
340 break;
341 case MySqlConnection m:
342 parameters = new MySqlParameter[dictionary.Count];
343 break;
344 //case OracleConnection o:
345 //parameters = new OracleParameter[dictionary.Count];
346 //break;
347 default:
348 parameters = new SqlParameter[dictionary.Count];
349 break;
350 }
351
352 string[] keyArray = dictionary.Keys.ToArray();
353 object[] valueArray = dictionary.Values.ToArray();
354
355 for (int i = 0; i < parameters.Length; i++)
356 {
357 switch (conn)
358 {
359 case SqlConnection s:
360 parameters[i] = new SqlParameter(keyArray[i], valueArray[i]);
361 break;
362 case MySqlConnection m:
363 parameters[i] = new MySqlParameter(keyArray[i], valueArray[i]);
364 break;
365 //case OracleConnection o:
366 // parameters[i] = new OracleParameter(keyArray[i], valueArray[i]);
367 // break;
368 default:
369 parameters[i] = new SqlParameter(keyArray[i], valueArray[i]);
370 break;
371 }
372 }
373 cmd.Parameters.AddRange(parameters);
374 }
375 }
376 #endregion
377
378 #region 通过Model反射返回结果集 Model为 Entity 泛型变量的真实类型---反射返回结果集
379 public static List<Entity> GetListFromDataSet<Entity>(DataSet ds) where Entity : class
380 {
381 List<Entity> list = new List<Entity>();//实例化一个list对象
382 PropertyInfo[] propertyInfos = typeof(Entity).GetProperties(); //获取T对象的所有公共属性
383
384 DataTable dt = ds.Tables[0];//获取到ds的dt
385 if (dt.Rows.Count > 0)
386 {
387 //判断读取的行是否>0 即数据库数据已被读取
388 foreach (DataRow row in dt.Rows)
389 {
390 Entity model1 = System.Activator.CreateInstance<Entity>();//实例化一个对象,便于往list里填充数据
391 foreach (PropertyInfo propertyInfo in propertyInfos)
392 {
393 try
394 {
395 //遍历模型里所有的字段
396 if (row[propertyInfo.Name] != System.DBNull.Value)
397 {
398 //判断值是否为空,如果空赋值为null见else
399 if (propertyInfo.PropertyType.IsGenericType && propertyInfo.PropertyType.GetGenericTypeDefinition().Equals(typeof(Nullable<>)))
400 {
401 //如果convertsionType为nullable类,声明一个NullableConverter类,该类提供从Nullable类到基础基元类型的转换
402 NullableConverter nullableConverter = new NullableConverter(propertyInfo.PropertyType);
403 //将convertsionType转换为nullable对的基础基元类型
404 propertyInfo.SetValue(model1, Convert.ChangeType(row[propertyInfo.Name], nullableConverter.UnderlyingType), null);
405 }
406 else
407 {
408 propertyInfo.SetValue(model1, Convert.ChangeType(row[propertyInfo.Name], propertyInfo.PropertyType), null);
409 }
410 }
411 else
412 {
413 propertyInfo.SetValue(model1, null, null);//如果数据库的值为空,则赋值为null
414 }
415 }
416 catch (Exception)
417 {
418 propertyInfo.SetValue(model1, null, null);//如果数据库的值为空,则赋值为null
419 }
420 }
421 list.Add(model1);//将对象填充到list中
422 }
423 }
424 return list;
425 }
426 public static List<Entity> GetListFromDataSetV2<Entity>(DataSet ds) where Entity : class
427 {
428 List<Entity> list = new List<Entity>();
429 DataTable dt = ds.Tables[0];
430 if (dt.Rows.Count > 0)
431 {
432 foreach (DataRow row in dt.Rows)
433 {
434 Entity entity = FillAdapter<Entity>.AutoFill(row);
435 list.Add(entity);
436 }
437 }
438 return list;
439 }
440 public static Entity GetEntityFromDataReader<Entity>(DbDataReader reader) where Entity : class
441 {
442 Entity model = System.Activator.CreateInstance<Entity>(); //实例化一个T类型对象
443 PropertyInfo[] propertyInfos = model.GetType().GetProperties(); //获取T对象的所有公共属性
444 using (reader)
445 {
446 if (reader.Read())
447 {
448 foreach (PropertyInfo propertyInfo in propertyInfos)
449 {
450 //遍历模型里所有的字段
451 if (reader[propertyInfo.Name] != System.DBNull.Value)
452 {
453 //判断值是否为空,如果空赋值为null见else
454 if (propertyInfo.PropertyType.IsGenericType && propertyInfo.PropertyType.GetGenericTypeDefinition().Equals(typeof(Nullable<>)))
455 {
456 //如果convertsionType为nullable类,声明一个NullableConverter类,该类提供从Nullable类到基础基元类型的转换
457 NullableConverter nullableConverter = new NullableConverter(propertyInfo.PropertyType);
458 //将convertsionType转换为nullable对的基础基元类型
459 propertyInfo.SetValue(model, Convert.ChangeType(reader[propertyInfo.Name], nullableConverter.UnderlyingType), null);
460 }
461 else
462 {
463 propertyInfo.SetValue(model, Convert.ChangeType(reader[propertyInfo.Name], propertyInfo.PropertyType), null);
464 }
465 }
466 else
467 {
468 propertyInfo.SetValue(model, null, null);//如果数据库的值为空,则赋值为null
469 }
470 }
471 return model;//返回T类型的赋值后的对象 model
472 }
473 }
474 return default(Entity);//返回引用类型和值类型的默认值0或null
475 }
476 public static Entity GetEntityFromDataSet<Entity>(DataSet ds) where Entity : class
477 {
478 return GetListFromDataSet<Entity>(ds).FirstOrDefault();
479 }
480 public static Entity GetEntityFromDataSetV2<Entity>(DataSet ds) where Entity : class
481 {
482 DataTable dt = ds.Tables[0];// 获取到ds的dt
483 if (dt.Rows.Count > 0)
484 {
485 return FillAdapter<Entity>.AutoFill(dt.Rows[0]);
486 }
487 return default(Entity);
488 }
489 #endregion
490 }
491
492 /// <summary>
493 /// Auto Fill Adapter
494 /// </summary>
495 /// <typeparam name="Entity"></typeparam>
496 internal class FillAdapter<Entity>
497 {
498 private static readonly Func<DataRow, Entity> funcCache = GetFactory();
499 public static Entity AutoFill(DataRow row)
500 {
501 return funcCache(row);
502 }
503 private static Func<DataRow, Entity> GetFactory()
504 {
505 var type = typeof(Entity);
506 var rowType = typeof(DataRow);
507 var rowDeclare = Expression.Parameter(rowType, "row");
508 var instanceDeclare = Expression.Parameter(type, "t");
509 //new Student()
510 var newExpression = Expression.New(type);
511 //(t = new Student())
512 var instanceExpression = Expression.Assign(instanceDeclare, newExpression);
513 //row == null
514 var nullEqualExpression = Expression.NotEqual(rowDeclare, Expression.Constant(null));
515 var containsMethod = typeof(DataColumnCollection).GetMethod("Contains");
516 var indexerMethod = rowType.GetMethod("get_Item", BindingFlags.Instance | BindingFlags.Public, null, new[] { typeof(string) }, new[] { new ParameterModifier(1) });
517 var properties = type.GetProperties(BindingFlags.Instance | BindingFlags.Public);
518 var setExpressions = new List<Expression>();
519 //row.Table.Columns
520 var columns = Expression.Property(Expression.Property(rowDeclare, "Table"), "Columns");
521 foreach (var propertyInfo in properties)
522 {
523 if (propertyInfo.CanWrite)
524 {
525 //Id,Id is a property of Entity
526 var propertyName = Expression.Constant(propertyInfo.Name, typeof(string));
527 //row.Table.Columns.Contains("Id")
528 var checkIfContainsColumn = Expression.Call(columns, containsMethod, propertyName);
529 //t.Id
530 var propertyExpression = Expression.Property(instanceDeclare, propertyInfo);
531 //row.get_Item("Id")
532 var value = Expression.Call(rowDeclare, indexerMethod, propertyName);
533 //t.Id = Convert(row.get_Item("Id"), Int32)
534 var propertyAssign = Expression.Assign(propertyExpression, Expression.Convert(value, propertyInfo.PropertyType));
535 //t.Id = default(Int32)
536 var propertyAssignDefault = Expression.Assign(propertyExpression, Expression.Default(propertyInfo.PropertyType));
537 //if(row.Table.Columns.Contains("Id")&&!value.Equals(DBNull.Value<>)) {t.Id = Convert(row.get_Item("Id"), Int32)}else{t.Id = default(Int32)}
538 var checkRowNull = Expression.IfThenElse(Expression.AndAlso(checkIfContainsColumn, Expression.NotEqual(value, Expression.Constant(System.DBNull.Value))), propertyAssign, propertyAssignDefault);
539 //var checkContains = Expression.IfThen(checkIfContainsColumn, propertyAssign);
540 setExpressions.Add(checkRowNull);
541 }
542 }
543 var checkIfRowIsNull = Expression.IfThen(nullEqualExpression, Expression.Block(setExpressions));
544 var body = Expression.Block(new[] { instanceDeclare }, instanceExpression, checkIfRowIsNull, instanceDeclare);
545 return Expression.Lambda<Func<DataRow, Entity>>(body, rowDeclare).Compile();
546 }
547 }
548
549 /**
550 * author:qixiao
551 * time:2017-9-18 18:02:23
552 * description:safe create sqlconnection support
553 * */
554 internal class SqlConnection_RW : IDisposable
555 {
556 /// <summary>
557 /// SqlConnection
558 /// </summary>
559 public DbConnection DbConnection { get; set; }
560
561 public SqlConnection_RW(DataBaseType dataBaseType, string ConnString_RW)
562 {
563 this.DbConnection = GetDbConnection(dataBaseType, ConnString_RW);
564 }
565 /**
566 * if read db disabled,switchover to read write db immediately
567 * */
568 public SqlConnection_RW(DataBaseType dataBaseType, string ConnString_R, string ConnString_RW)
569 {
570 try
571 {
572 this.DbConnection = GetDbConnection(dataBaseType, ConnString_R);
573 }
574 catch (Exception)
575 {
576 this.DbConnection = GetDbConnection(dataBaseType, ConnString_RW);
577 }
578 }
579
580 /// <summary>
581 /// GetDataBase ConnectionString by database type and connection string -- private use
582 /// </summary>
583 /// <param name="dataBaseType"></param>
584 /// <param name="ConnString"></param>
585 /// <returns></returns>
586 private DbConnection GetDbConnection(DataBaseType dataBaseType, string ConnString)
587 {
588 switch (dataBaseType)
589 {
590 case DataBaseType.SqlServer:
591 return new SqlConnection(ConnString);
592 case DataBaseType.MySql:
593 return new MySqlConnection(ConnString);
594 case DataBaseType.Oracle:
595 //return new OracleConnection(ConnString);
596 default:
597 return new SqlConnection(ConnString);
598 }
599 }
600 /// <summary>
601 /// Must Close Connection after use
602 /// </summary>
603 public void Dispose()
604 {
605 if (this.DbConnection != null)
606 {
607 this.DbConnection.Dispose();
608 }
609 }
610 }
611 /// <summary>
612 /// Common sqlcommand
613 /// </summary>
614 internal class DbCommandCommon : IDisposable
615 {
616 /// <summary>
617 /// common dbcommand
618 /// </summary>
619 public DbCommand DbCommand { get; set; }
620 public DbCommandCommon(DataBaseType dataBaseType)
621 {
622 this.DbCommand = GetDbCommand(dataBaseType);
623 }
624
625 /// <summary>
626 /// Get DbCommand select database type
627 /// </summary>
628 /// <param name="dataBaseType"></param>
629 /// <returns></returns>
630 private DbCommand GetDbCommand(DataBaseType dataBaseType)
631 {
632 switch (dataBaseType)
633 {
634 case DataBaseType.SqlServer:
635 return new SqlCommand();
636 case DataBaseType.MySql:
637 return new MySqlCommand();
638 case DataBaseType.Oracle:
639 //return new OracleCommand();
640 default:
641 return new SqlCommand();
642 }
643 }
644 /// <summary>
645 /// must dispose after use
646 /// </summary>
647 public void Dispose()
648 {
649 if (this.DbCommand != null)
650 {
651 this.DbCommand.Dispose();
652 }
653 }
654 }
655 /// <summary>
656 /// DbDataAdapterCommon
657 /// </summary>
658 internal class DbDataAdapterCommon : DbDataAdapter, IDisposable
659 {
660 public DbDataAdapter DbDataAdapter { get; set; }
661 public DbDataAdapterCommon(DataBaseType dataBaseType, DbCommand dbCommand)
662 {
663 //get dbAdapter
664 this.DbDataAdapter = GetDbAdapter(dataBaseType, dbCommand);
665 //provid select command
666 this.SelectCommand = dbCommand;
667 }
668 private DbDataAdapter GetDbAdapter(DataBaseType dataBaseType, DbCommand dbCommand)
669 {
670 switch (dataBaseType)
671 {
672 case DataBaseType.SqlServer:
673 return new SqlDataAdapter();
674 case DataBaseType.MySql:
675 return new MySqlDataAdapter();
676 case DataBaseType.Oracle:
677 //return new OracleDataAdapter();
678 default:
679 return new SqlDataAdapter();
680 }
681 }
682 /// <summary>
683 /// must dispose after use
684 /// </summary>
685 public new void Dispose()
686 {
687 if (this.DbDataAdapter != null)
688 {
689 this.DbDataAdapter.Dispose();
690 }
691 }
692 }
693
694 /// <summary>
695 /// 用于批量操作的批量操作实体
696 /// </summary>
697 public class BatchExecuteModel
698 {
699 /// <summary>
700 /// 执行的语句或者存储过程名称
701 /// </summary>
702 public string CommandTextOrSpName { get; set; }
703 /// <summary>
704 /// 执行类别,默认执行sql语句
705 /// </summary>
706 public CommandType CommandType { get; set; } = CommandType.Text;
707 /// <summary>
708 /// 执行语句的参数字典
709 /// </summary>
710 public IDictionary<string, object> ParamsDic { get; set; }
711 }
712 }