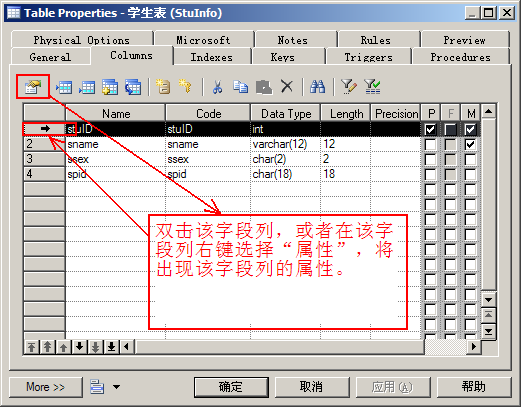
前端时间给别人做迁移数据库时候,遇到一些问题.大致是,如果备份的数据库存在EXTERNAL_ACCESS 和UNSAFE的程序集,那么在还原的时候程序集会出现一些奇怪的错误:
.csharpcode, .csharpcode pre { font-size: small; color: black; font-family: consolas,”Courier New”,courier,monospace; background-color: rgb(255, 255, 255); }.csharpcode pre { margin: 0em; }.csharpcode .rem { color: rgb(0, 128, 0); }.csharpcode .kwrd { color: rgb(0, 0, 255); }.csharpcode .str { color: rgb(0, 96, 128); }.csharpcode .op { color: rgb(0, 0, 192); }.csharpcode .preproc { color: rgb(204, 102, 51); }.csharpcode .asp { background-color: rgb(255, 255, 0); }.csharpcode .html { color: rgb(128, 0, 0); }.csharpcode .attr { color: rgb(255, 0, 0); }.csharpcode .alt { background-color: rgb(244, 244, 244); width: 100%; margin: 0em; }.csharpcode .lnum { color: rgb(96, 96, 96); }编译创建程序集.
在机器A上的数据库上执行:
CREATE DATABASE test;
USE test;
ALTER DATABASE test SET TRUSTWORTHY ON;
CREATE ASSEMBLY [TestCLR] FROM 'E:\Documents\Visual Studio 2010\Projects\TestCLR\TestCLR\bin\Release\TestCLR.dll' WITH PERMISSION_SET = EXTERNAL_ACCESS;
--SAFE;
CREATE PROC dbo.usp_test
AS
EXTERNAL NAME [TestCLR].StoredProcedures.Test;
EXEC dbo.usp_test;
USE master;
BACKUP DATABASE test TO DISK = 'c:\test.bak' WITH FORMAT;
.csharpcode, .csharpcode pre { font-size: small; color: black; font-family: consolas,”Courier New”,courier,monospace; background-color: rgb(255, 255, 255); }.csharpcode pre { margin: 0em; }.csharpcode .rem { color: rgb(0, 128, 0); }.csharpcode .kwrd { color: rgb(0, 0, 255); }.csharpcode .str { color: rgb(0, 96, 128); }.csharpcode .op { color: rgb(0, 0, 192); }.csharpcode .preproc { color: rgb(204, 102, 51); }.csharpcode .asp { background-color: rgb(255, 255, 0); }.csharpcode .html { color: rgb(128, 0, 0); }.csharpcode .attr { color: rgb(255, 0, 0); }.csharpcode .alt { background-color: rgb(244, 244, 244); width: 100%; margin: 0em; }.csharpcode .lnum { color: rgb(96, 96, 96); }将c:\test.bak copy 到机器B上,然后执行:
USE [master];
--还原数据库
RESTORE DATABASE test FROM DISK = 'c:\test.bak' WITH RECOVERY,
MOVE 'test' TO 'E:\data\test.mdf',
MOVE 'test_log' TO 'E:\data\test.ldf',REPLACE;
--如果没有启用CLR,开启
EXEC sp_configure 'clr enabled',1
RECONFIGURE WITH OVERRIDE;
USE test;
--查看程序集,是存在的.
SELECT * FROM sys.assemblies;
SELECT * FROM sys.assembly_files;
--还原之后的数据库TRUSTWORTHY 都是OFF的,需要重新设置
ALTER DATABASE test SET TRUSTWORTHY ON;
USE test;
--执行存储过程
EXEC dbo.usp_test;
.csharpcode, .csharpcode pre { font-size: small; color: black; font-family: consolas,”Courier New”,courier,monospace; background-color: rgb(255, 255, 255); }.csharpcode pre { margin: 0em; }.csharpcode .rem { color: rgb(0, 128, 0); }.csharpcode .kwrd { color: rgb(0, 0, 255); }.csharpcode .str { color: rgb(0, 96, 128); }.csharpcode .op { color: rgb(0, 0, 192); }.csharpcode .preproc { color: rgb(204, 102, 51); }.csharpcode .asp { background-color: rgb(255, 255, 0); }.csharpcode .html { color: rgb(128, 0, 0); }.csharpcode .attr { color: rgb(255, 0, 0); }.csharpcode .alt { background-color: rgb(244, 244, 244); width: 100%; margin: 0em; }.csharpcode .lnum { color: rgb(96, 96, 96); }但是一执行就报错了.
解决方案:
在还原数据库之后,我们可以将数据库的OWNER设置成SA.
exec sp_changedbowner ‘sa’
再调用存储过程就是成功的.
可以查看:KB http://support.microsoft.com/kb/918040
后来经过一些整理,发现当SQL CLR 存在EXTERNAL_ACCESS或者是UNSAFE的程序集的时候,SQL Server会检查DBO的SID在sys.databases 和sys.server_principals是否一致.
因此我们可能未必一定要修改成sa 的,只要所有者的SID在sys.databases和sys.server_principals 是一致的,就不出问题.
我们在SSMS里面右键数据库属性->找到文件选项卡->发现在所有者(是空的,还原以后原来的SID,数据库所有者在当前的 sys.server_principals不匹配的),我们可以在 […] 里面选择一个,具有创建CREATE ASSEMLY 权限的所有者就好,我选择了B\Administrator,然后测试 CLR 存储过程,没问题,
引深:
在SQL Server 复制里面也存在类似的问题,就是我们做 “对等复制” 的时候,会出现DBO不存在,以及sp_replcmd 不存在类似的错误.其实也是因为对等复制初始化订阅是通过 RESTORE 来实现的,因此只要简单的修改数据库所有者 就好了….那么对等复制的问题也就解决了!!