
来源: REST Web Service开发实践–Jersey,Google Protocol Buffer, Tomcat结合样例 – – ITeye技术网站
当前REST化的WebService大行其道,Jersey是Sun推出的REST WEB Service参考实现,而Google Protocol Buffer由于其高效,短小,代码自动生成而成为分布式系统数据交互的优良选择, tomcat以市场占有率第一Servlet容器而知名,所以本文就讲叙怎么用Jersey, Google PB, Tomcat这三大法宝开发REST式的WEB service.
二 环境准备:
jersey版本:jersey-archive-1.2-SNAPSHOT
Google PB版本: protobuf-2.3.0
tomcat: tomcat6.0
Eclipse: 3.5.1 + tomcat plug in:http://www.eclipsetotale.com/tomcatPlugin.html
三 项目依赖的lib
sm-3.1.jar
jersey-server-1.2-SNAPSHOT.jar
jackson-core-asl-1.1.1.jar
jersey-spring-1.2-SNAPSHOT.jar
jersey-client-1.2-SNAPSHOT.jar
jettison-1.1.jar
jersey-core-1.2-SNAPSHOT.jar
jsr311-api-1.1.1.jar
jersey-json-1.2-SNAPSHOT.jar
protobuf-java-2.3.0.jar
请到jersey的包中和pb的包中找上述的lib
四 动手吧
4.1 在Eclipse新建一个tomcat工程, Eclipse的workspace为D:/workspace:
工程展开如图
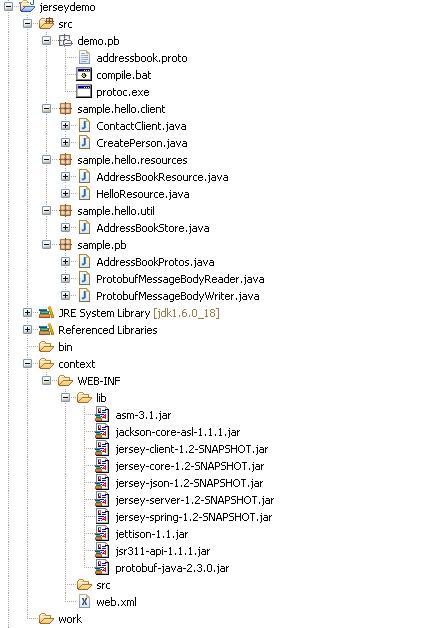
4.2 图中元素说明:
addressbook.proto pb自带的电话本message定义文件
compile.bat 自己写的message编译脚本
protoc.exe pb的编译命令行工具
ContactClient.java 访问REST service的client端代码
CreatePerson.java 自己写的生成Person PB结构,并存在D:盘根目录下的小工具类
AddressBookResource REST Service核心Resource类
HelloResource.java Hello world Resource类
AddressBookStore.java 自己写的一个服务器段电话簿存储类,以D:/addressBooks.txt为存储文件
AddressBookProtos.java addressbook.proto 被PB命令行工具编译后生成的java类
ProtobufMessageBodyReader.java 服务器把Request输入流转化成PB结构的Provider类,用以把用户上穿的字节流转成PB结构
ProtobufMessageBodyWriter.java 服务器把PB机构转化成输出流的Provider类,用以把PB结构转成字节流输出给用户
4.3 代码:
addressbook.proto
package demo;
option java_package = “sample.pb”;
option java_outer_classname = “AddressBookProtos”;
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}
———————————————————————-
compile.bat
protoc -I=D:/workspace/jerseydemo/src –java_out=D:/workspace/jerseydemo/src D:/workspace/jerseydemo/src/demo/pb/addressbook.proto
————————————————————————————–
ContactClient.java
package sample.hello.client;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.List;
import sample.pb.AddressBookProtos.Person;
import sample.pb.AddressBookProtos.Person.PhoneNumber;
public class ContactClient {
public static void main(String[] args) throws IOException {
String url1 = “http://localhost:8080/jerseydemo/rest/addressbook/”;
putContacts(url1, “hery”);
String url2 = “http://localhost:8080/jerseydemo/rest/addressbook/hery”;
getContacts(url2);
}
public static void putContacts(String url, String name) throws IOException {
File file = new File(“D:/”+name+”.per”);
Person p = Person.parseFrom(new FileInputStream(file));
byte[] content = p.toByteArray();
URL target = new URL(url);
HttpURLConnection conn = (HttpURLConnection) target.openConnection();
conn.setDoOutput(true);
conn.setDoInput(true);
conn.setRequestMethod(“PUT”);
conn.setRequestProperty(“Content-Type”, “application/x-protobuf”);
conn.setRequestProperty(“Accept”, “application/x-protobuf;q=0.5”);
conn.setRequestProperty(“Content-Length”, Integer.toString(content.length));
// set stream mode to decrease memory usage
conn.setFixedLengthStreamingMode(content.length);
OutputStream out = conn.getOutputStream();
out.write(content);
out.flush();
out.close();
conn.connect();
// check response code
int code = conn.getResponseCode();
boolean success = (code >= 200) && (code < 300);
System.out.println(“put person:”+name+” “+(success?”successful!”:”failed!”));
}
public static void getContacts(String url) throws IOException {
URL target = new URL(url);
HttpURLConnection conn = (HttpURLConnection) target.openConnection();
conn.setDoOutput(true);
conn.setDoInput(true);
conn.setRequestMethod(“GET”);
conn.setRequestProperty(“Content-Type”, “application/x-protobuf”);
conn.setRequestProperty(“Accept”, “application/x-protobuf”);
conn.connect();
// check response code
int code = conn.getResponseCode();
boolean success = (code >= 200) && (code < 300);
InputStream in = success ? conn.getInputStream() : conn.getErrorStream();
int size = conn.getContentLength();
byte[] response = new byte[size];
int curr = 0, read = 0;
while (curr < size) {
read = in.read(response, curr, size – curr);
if (read <= 0) break;
curr += read;
}
Person p = Person.parseFrom(response);
System.out.println(“id:”+p.getId());
System.out.println(“name:”+p.getName());
System.out.println(“email:”+p.getEmail());
List<PhoneNumber> pl = p.getPhoneList();
for(PhoneNumber pn : pl) {
System.out.println(“number:”+pn.getNumber()+” type:”+pn.getType().name());
}
}
}
————————————————————————
CreatePerson.java
package sample.hello.client;
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import sample.pb.AddressBookProtos.Person;
public class CreatePerson {
// This function fills in a Person message based on user input.
static Person create(BufferedReader stdin,
PrintStream stdout) throws IOException {
Person.Builder person = Person.newBuilder();
stdout.print(“Enter person ID: “);
person.setId(Integer.valueOf(stdin.readLine()));
stdout.print(“Enter name: “);
person.setName(stdin.readLine());
stdout.print(“Enter email address (blank for none): “);
String email = stdin.readLine();
if (email.length() > 0) {
person.setEmail(email);
}
while (true) {
stdout.print(“Enter a phone number (or leave blank to finish): “);
String number = stdin.readLine();
if (number.length() == 0) {
break;
}
Person.PhoneNumber.Builder phoneNumber =
Person.PhoneNumber.newBuilder().setNumber(number);
stdout.print(“Is this a mobile, home, or work phone? “);
String type = stdin.readLine();
if (type.equals(“mobile”)) {
phoneNumber.setType(Person.PhoneType.MOBILE);
} else if (type.equals(“home”)) {
phoneNumber.setType(Person.PhoneType.HOME);
} else if (type.equals(“work”)) {
phoneNumber.setType(Person.PhoneType.WORK);
} else {
stdout.println(“Unknown phone type. Using default.”);
}
person.addPhone(phoneNumber);
}
return person.build();
}
// Main function: Reads the entire address book from a file,
// adds one person based on user input, then writes it back out to the same
// file.
public static void main(String[] args) throws Exception {
Person p = create(new BufferedReader(new InputStreamReader(System.in)),
System.out);
// Write the new address book back to disk.
FileOutputStream output = new FileOutputStream(“D:/”+p.getName()+”.per”);
p.writeTo(output);
output.close();
}
}
——————————————————————
AddressBookResource.java
package sample.hello.resources;
import javax.ws.rs.GET;
import javax.ws.rs.PUT;
import javax.ws.rs.Path;
import javax.ws.rs.PathParam;
import javax.ws.rs.core.Response;
import sample.hello.util.AddressBookStore;
import sample.pb.AddressBookProtos.Person;
@Path(“/addressbook”)
public class AddressBookResource {
@PUT
public Response putPerson(Person person) {
AddressBookStore.store(person);
return Response.ok().build();
}
@GET
@Path(“/{name}”)
public Response getPerson(@PathParam(“name”) String name) {
Person p = AddressBookStore.getPerson(name);
return Response.ok(p, “application/x-protobuf”).build();
}
}
——————————————————————————
AddressBookStore.java
package sample.hello.util;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import sample.pb.AddressBookProtos.AddressBook;
import sample.pb.AddressBookProtos.Person;
public class AddressBookStore {
static AddressBook addressBook = null;
static {
try {
addressBook =
AddressBook.parseFrom(new FileInputStream(“D:/addressBooks.txt”));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static Person getPerson(String name) {
for(Person person: addressBook.getPersonList()) {
if(person.getName().equals(name)) {
return person;
}
}
return null;
}
public static void store(Person p) {
AddressBook.Builder addressBookBuilder = AddressBook.newBuilder();
try {
String fileName = “D:/addressBooks.txt”;
File file = new File(fileName);
if(!file.exists()) {
file.createNewFile();
}
addressBookBuilder.mergeFrom(new FileInputStream(fileName));
addressBookBuilder.addPerson(p);
addressBookBuilder.build().writeTo(new FileOutputStream(fileName));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
————————————————————————–
AddressBookProtos.java
自动生成的,略
—————————————————————————–
ProtobufMessageBodyReader.java
package sample.pb;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.lang.annotation.Annotation;
import java.lang.reflect.Type;
import javax.ws.rs.Consumes;
import javax.ws.rs.WebApplicationException;
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.MultivaluedMap;
import javax.ws.rs.ext.MessageBodyReader;
import javax.ws.rs.ext.Provider;
import sample.pb.AddressBookProtos.Person;
@Provider
@Consumes(“application/x-protobuf”)
public class ProtobufMessageBodyReader implements MessageBodyReader<Object> {
@Override
public boolean isReadable(Class<?> type, Type genericType, Annotation[] annotations,
MediaType mediaType) {
return mediaType.toString().equals(“application/x-protobuf”);
}
@Override
public Object readFrom(Class<Object> type, Type genericType,
Annotation[] annotations, MediaType mediaType,
MultivaluedMap<String, String> httpHeaders, InputStream inputStream)
throws IOException, WebApplicationException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[4096];
int read;
long total = 0L;
do {
read = inputStream.read(buffer, 0, buffer.length);
if (read > 0) {
baos.write(buffer, 0, read);
total += read;
}
} while (read > 0);
return Person.parseFrom(baos.toByteArray());
}
}
———————————————————————————————
ProtobufMessageBodyWriter.java
package sample.pb;
import java.io.IOException;
import java.io.OutputStream;
import java.lang.annotation.Annotation;
import java.lang.reflect.Type;
import java.util.Map;
import java.util.WeakHashMap;
import javax.ws.rs.Produces;
import javax.ws.rs.WebApplicationException;
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.MultivaluedMap;
import javax.ws.rs.ext.MessageBodyWriter;
import javax.ws.rs.ext.Provider;
import sample.pb.AddressBookProtos.Person;
@Provider
@Produces(“application/x-protobuf”)
public class ProtobufMessageBodyWriter implements MessageBodyWriter<Object> {
/** a cache to save the cost of duplicated call(getSize, writeTo) to one object. */
private Map<Object, byte[]> buffer = new WeakHashMap<Object, byte[]>();
@Override
public boolean isWriteable(Class<?> type, Type genericType, Annotation[] annotations,
MediaType mediaType) {
// it will handle all model classes
return mediaType.toString().equals(“application/x-protobuf”);
}
@Override
public long getSize(Object message, Class<?> type, Type genericType,
Annotation[] annotations, MediaType mediaType) {
Person p = (Person)message;
byte[] bytes = p.toByteArray();
buffer.put(message, bytes);
return bytes.length;
}
@Override
public void writeTo(Object message, Class<?> type, Type genericType,
Annotation[] annotations, MediaType mediaType,
MultivaluedMap<String, Object> httpHeaders, OutputStream entityStream)
throws IOException, WebApplicationException {
entityStream.write(buffer.remove(message));
}
}
————————————————————————————–
web.xml
<?xml version=”1.0″ encoding=”UTF-8″?>
<web-app xmlns=”http://java.sun.com/xml/ns/javaee” xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=”http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd”
version=”2.5″>
<servlet>
<servlet-name>ServletAdaptor</servlet-name>
<servlet-class>com.sun.jersey.server.impl.container.servlet.ServletAdaptor</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>ServletAdaptor</servlet-name>
<url-pattern>/rest/*</url-pattern>
</servlet-mapping>
</web-app>
——————————————————————————————
五 测试过程:
5.1 设定web application的context name为:
/jerseydemo
web application的root 为
/context
使用Eclipse的tomcat plugin的菜单
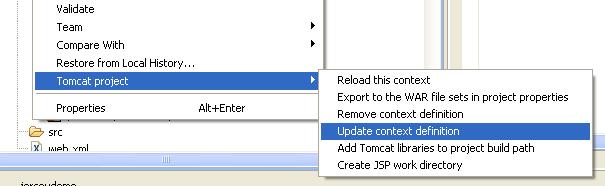
会在%TOMACT_HOME%\conf\Catalina\localhost下生成文件:
jerseydemo.xml
内容如下:
<Context path=”/jerseydemo” reloadable=”true” docBase=”D:\workspace\jerseydemo\context” workDir=”D:\workspace\jerseydemo\work” />
5.2 运行CreatePerson生成Person并写入磁盘:
在console进行如下输入:
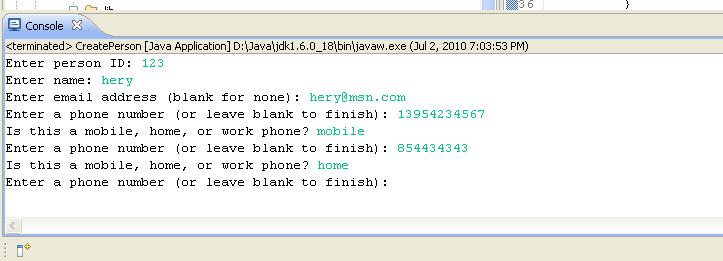
查看D:盘根目录,发现新生成的 hery.per 文件.
5.3 启动tomcat(我就是点下Eclipse上的那只小猫)
5.4 运行ContactClient, 执行结果如下:
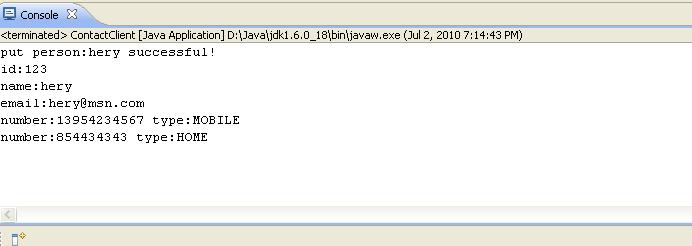
可见我们上传成功,并且能按名字查询.
D盘根目录下,同时生成了文件addressBooks.txt,这个为server段保留电话簿的地方.
六 完整的工程打包文件
















{kind=link}